
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(二)
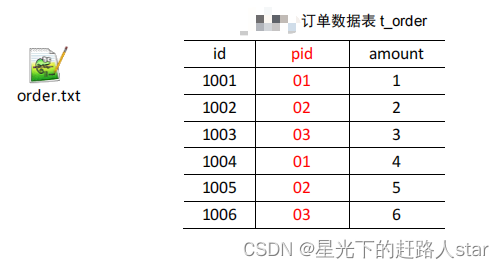
3、Join应用3.1 Reduce Join(1)Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。(2)Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并....
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(一)
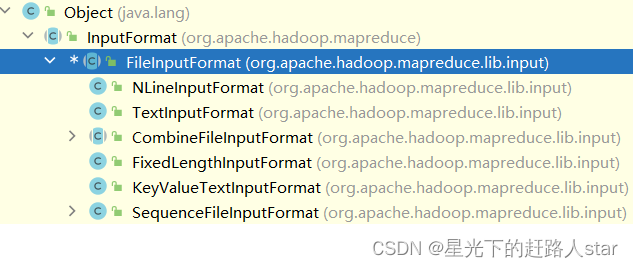
1、OutputFormat数据输出1.1 OutputFormat接口实现类OutputFormat是MapReduce输出的基类,所以实现MapReduce输出都实现了OutputFormat接口。1、MapReduce默认的输出格式是TextOutputFormat2、也可以自定义OutputFormat类,只要继承就行。1.2 自定义OutputFormat案例实操1、需求过滤输入的 l....
Hadoop基础学习---6、MapReduce框架原理(二)
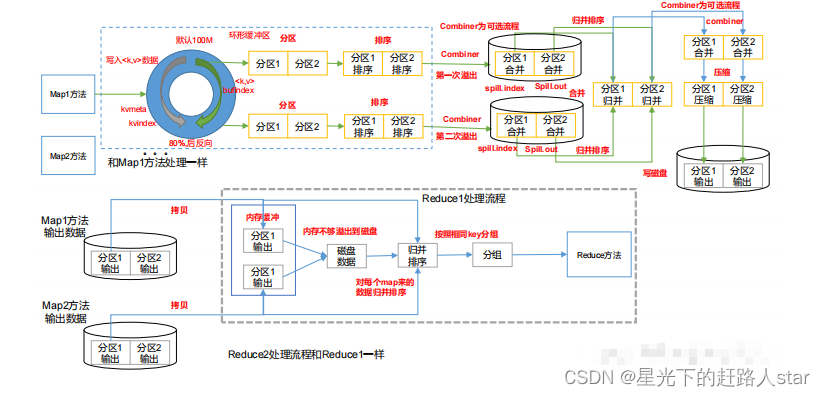
1.3 Shuffle机制1.3.1 Shuffle机制Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。1.3.2 Partition1、问题引出要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照收集归属地不同省份输出到不同文件中。2、默认Partitioner分区默认分区时根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制....
Hadoop基础学习---6、MapReduce框架原理(一)
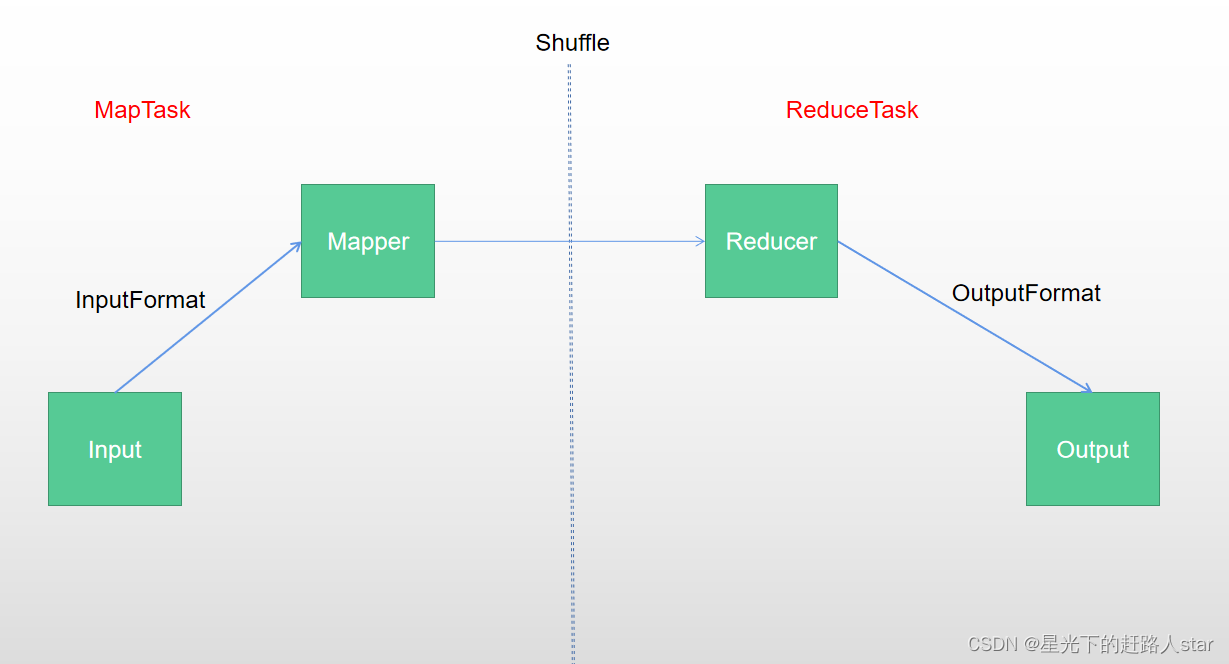
1、MapReduce框架原理1.1 InputFormat数据输入1.1.1 切片与MapTask并行度决定机制1、问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个job的处理速度。2、MapTask并行度决定机制数据块:Block是HDFS物理上吧数据分成一块一块。数据块是HDFS储存数据单位。数据切片:数据切片只是在逻辑上对输出进行分片,并不会在磁盘上将其切分成....
Hadoop基础学习---5、MapReduce概述和WordCount实操(本地运行和集群运行)、Hadoop序列化
1、MapReduce概述1.1 MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。1.2 MapReduce的优缺点1.2.1 优点1、易于编程它简单的实现一些接口,就可以完成一个分布式....
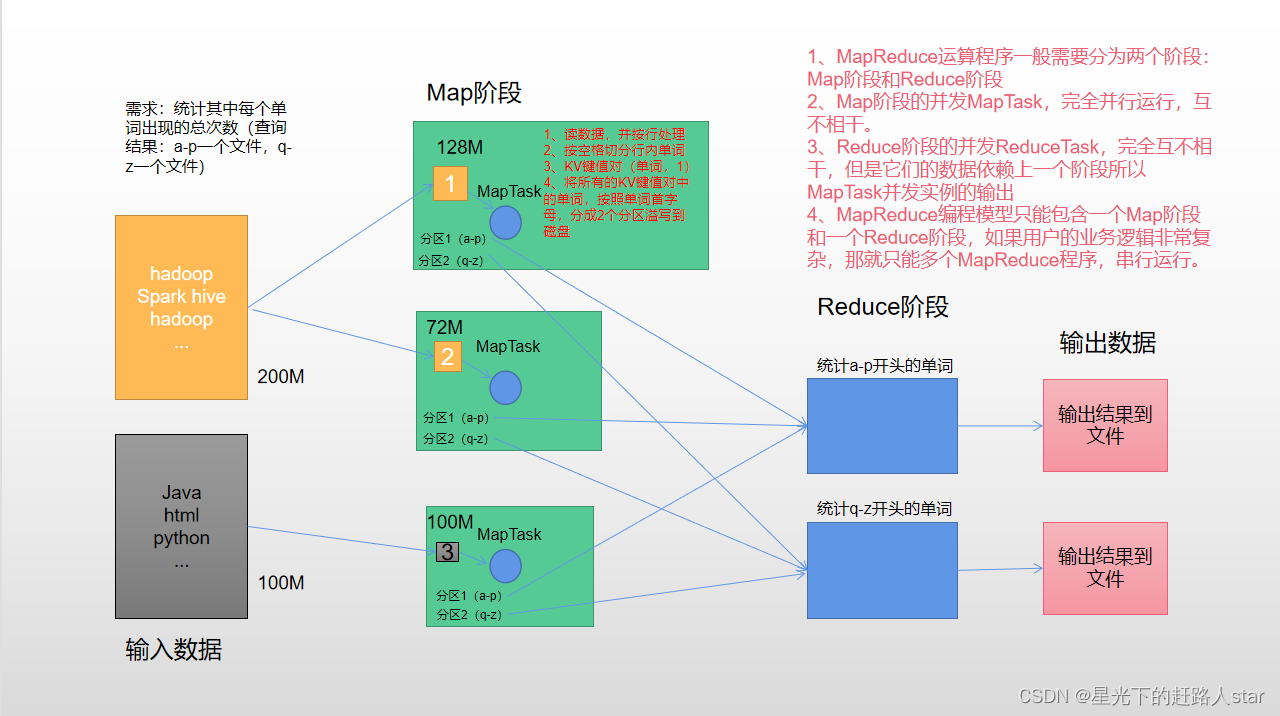
MapReduce系统学习(2)
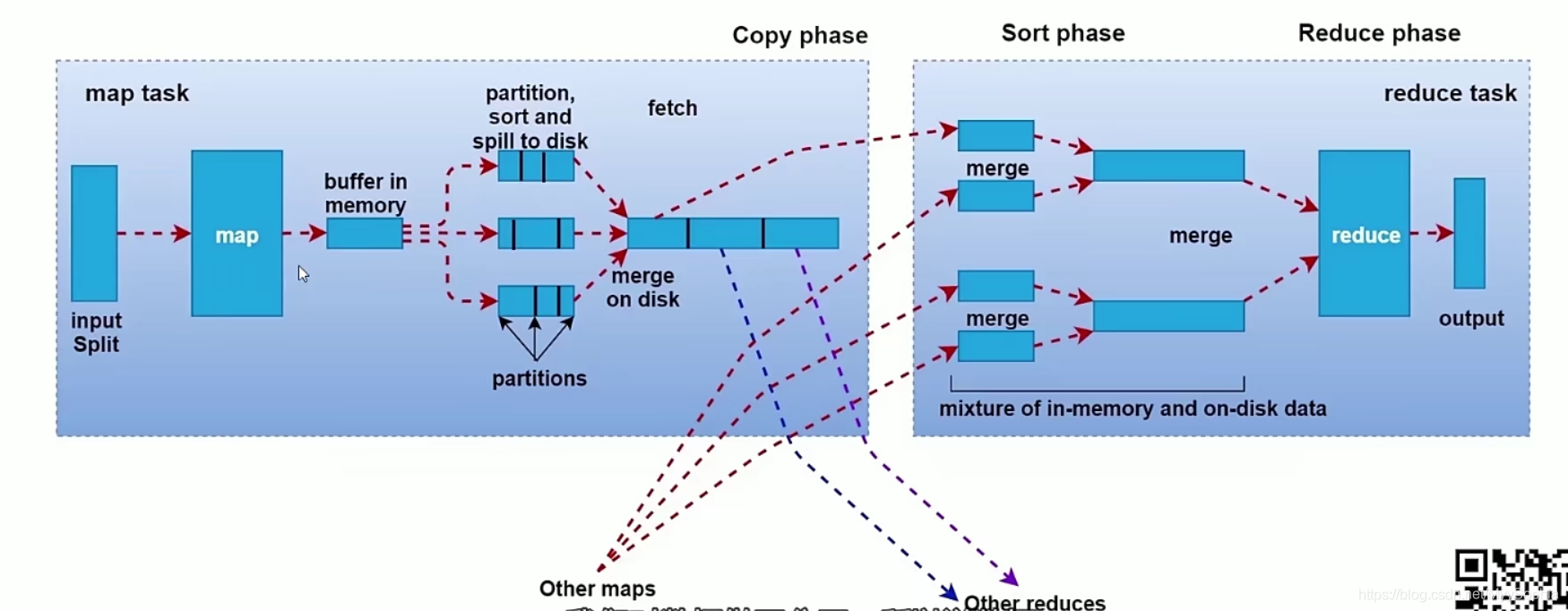
Shuffle过程详解shuffer是一个网络拷贝的过程,是指通过网络把数据从map端拷贝到reduce端的过程.map阶段最左边有一个inputsplit,最终会产生一个map任务,map任务在执行的时候会k1,v1转化为k2,v2,这些数据会先临时存储到一个内存缓冲区中,这个内存缓冲区的大小默认是100M(io.sort.mb属性),当达到内存缓冲区大小的80%(io.sort.spill.per....
MapReduce系统学习
MapReduce介绍计算扑克牌中的黑桃个数就是我们平时打牌时用的扑克牌,现在呢,有一摞牌,我想知道这摞牌中有多少张黑桃最直接的方式是一张一张检查并且统计出有多少张是黑桃,但是这种方式的效率比较低,如果说这一摞牌只有几十张也就无所谓了,如果这一摞拍有上千张呢?你一张一张去检查还不疯了?这个时候我们可以使用MapReduce的计算方法第一步:把这摞牌分配给在座的所有玩家 ....

Hadoop学习:MapReduce实现WordCount经典案例
一、✌题目要求> 统计文本中每个单词的数量二、✌实现思想> Map阶段默认输入为TextInputFormat,键值对对应为行的偏移量和每行的文本内容 > 在map函数中将每行文本进行切分,提取出每个单词 > 在Reduce阶段根据相同Key值进行累加求和 > 三、✌代码实现1.✌Map类public class WordCountMapper extends Ma....
Hadoop学习:MapReduce实现文件的解压缩
一、✌实现思想压缩> 获取输入流 > 获取压缩相关信息(反射) > 获取输出流 > 流的对拷 > 关闭资源解压缩> 校验文件是否可以解压 > 获取输入流 > 获取输出流 > 流的对拷 > 关闭资源二、✌代码实现1.✌compress压缩方法public static void compress(String fileName, Stri....
Hadoop学习:MapReduce实现倒排索引
一、✌题目要求文件1:a.txt文件2:b.txt文件3:c.txt最终输出格式:二、✌实现思想> 首先在map阶段,获得每个单词所在的文件名称 > 然后在方法中,每个单词作为Key,所在文件名称+1作为Value > 在Reduce阶段,针对每个Key,对他们的Value迭代,将Value切割获得个数,不断累加 > 最终按照指定格式写出三、✌代码实现1.✌Map类imp....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开源大数据平台 E-MapReduce学习相关内容
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce产品
- 开源大数据平台 E-MapReduce参数
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce dataset
- 开源大数据平台 E-MapReduce工作空间
- 开源大数据平台 E-MapReduce s3
- 开源大数据平台 E-MapReduce oss
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce文件
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce模式
- 开源大数据平台 E-MapReduce map
- 开源大数据平台 E-MapReduce版本
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
+关注