
Hadoop基础学习---6、MapReduce框架原理(二)
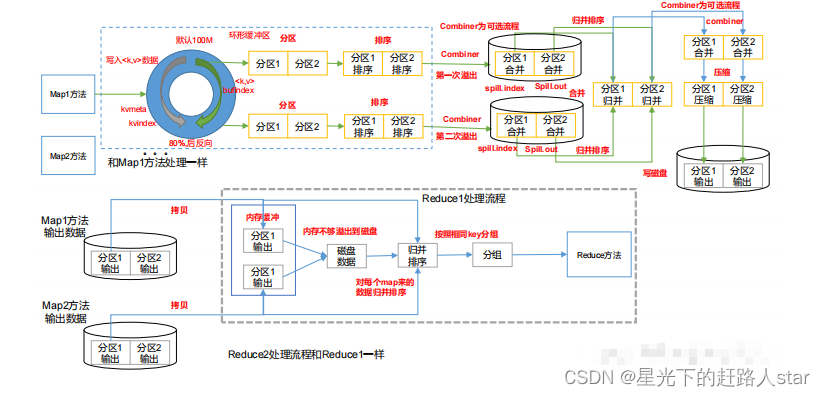
1.3 Shuffle机制1.3.1 Shuffle机制Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。1.3.2 Partition1、问题引出要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照收集归属地不同省份输出到不同文件中。2、默认Partitioner分区默认分区时根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制....
Hadoop基础学习---6、MapReduce框架原理(一)
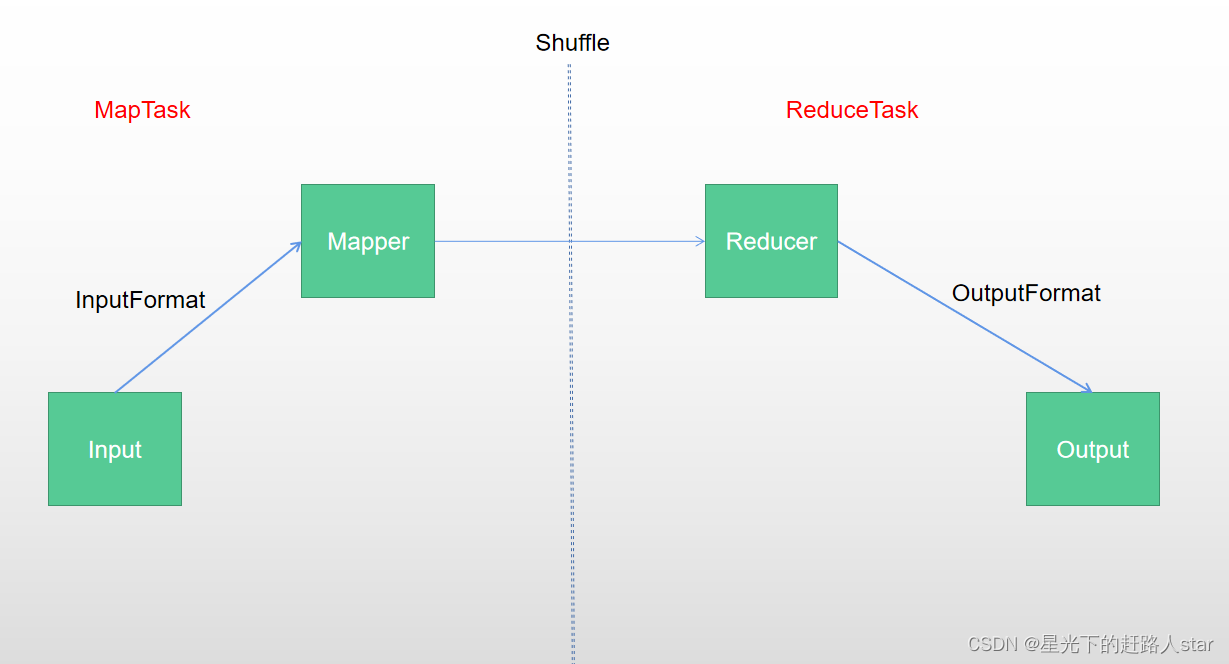
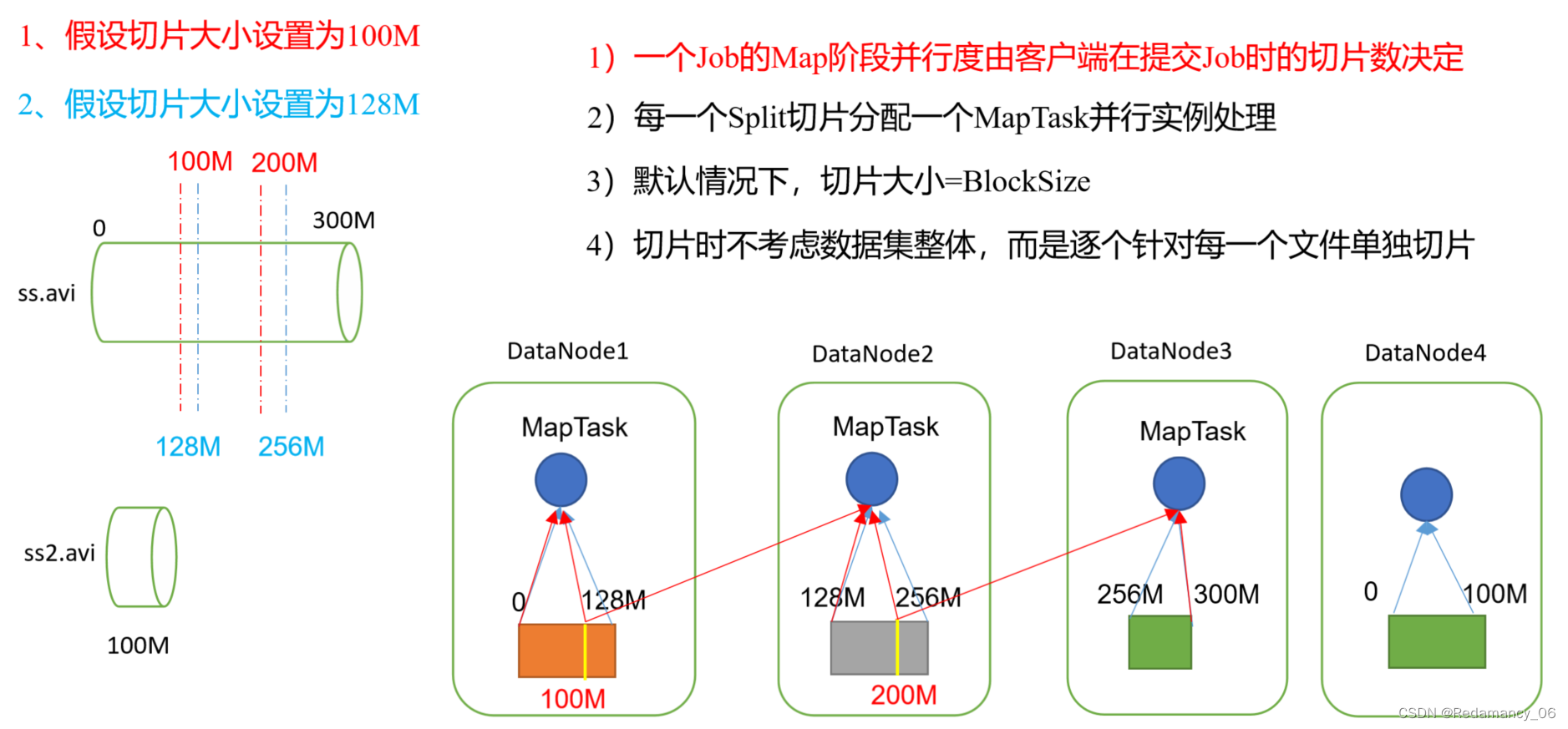
1、MapReduce框架原理1.1 InputFormat数据输入1.1.1 切片与MapTask并行度决定机制1、问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个job的处理速度。2、MapTask并行度决定机制数据块:Block是HDFS物理上吧数据分成一块一块。数据块是HDFS储存数据单位。数据切片:数据切片只是在逻辑上对输出进行分片,并不会在磁盘上将其切分成....
MapReduce 的原理、流程【重要】
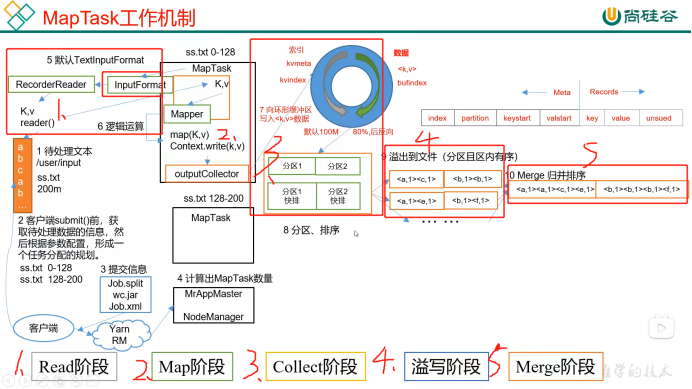
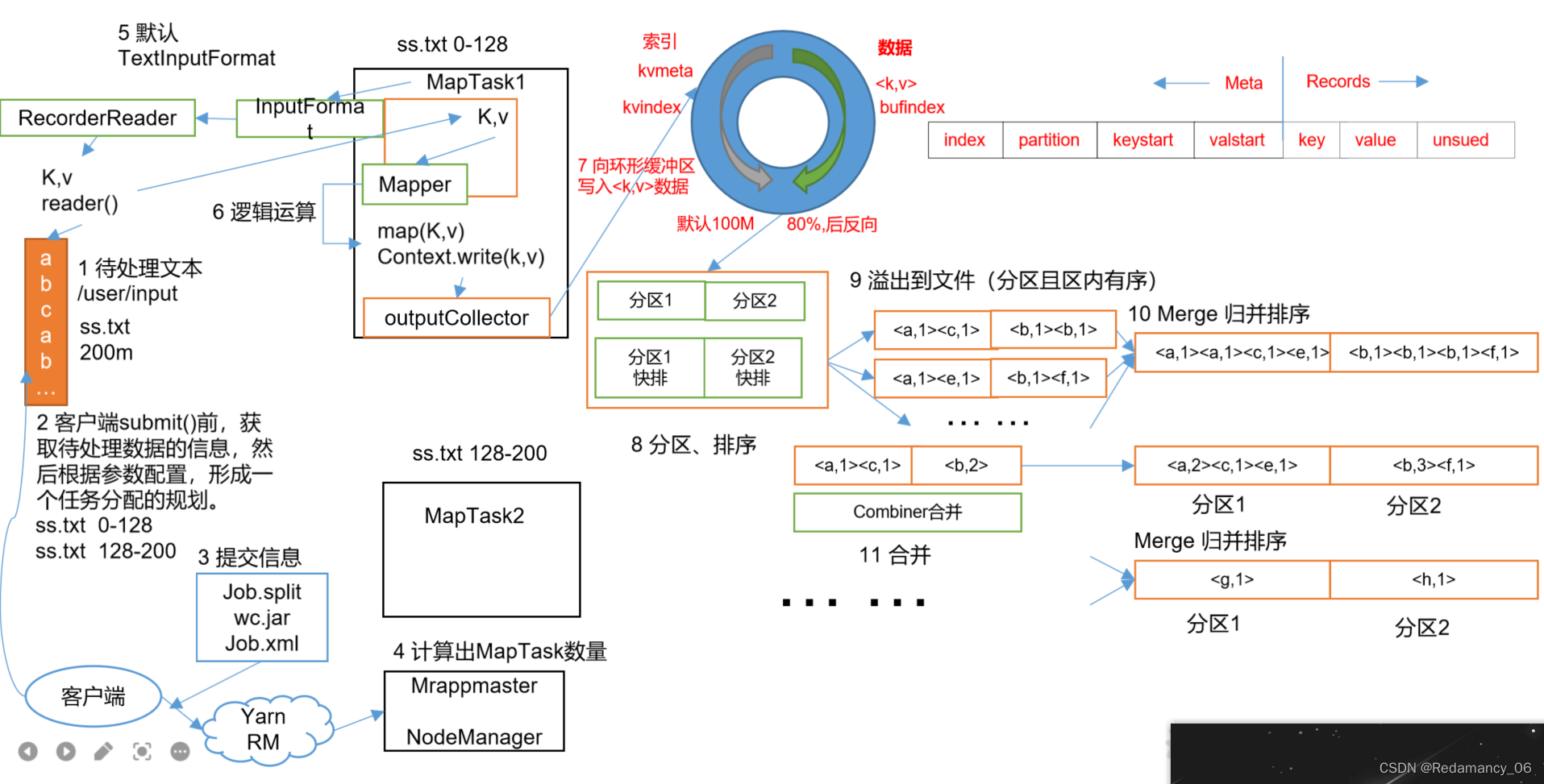
MapReduce 分为两个阶段,Map 阶段和 Reduce 阶段:MapTask 工作机制:首先是 Map 阶段,Map 有五个阶段:Read 阶段、Map 阶段、Collect 阶段、溢写阶段、Merge 阶段(1)Read 阶段:默认用 TextInputFormat 进行读取数据,用 RecordReader 中的 reader()方法进行读取,以(K,V)的形式传入 Mapper 中....
Hadoop生态系统中的数据处理技术:MapReduce的原理与应用
Hadoop生态系统是大数据处理的核心框架之一。在Hadoop生态系统中,MapReduce是一种常用的数据处理技术。本文将介绍MapReduce的原理和应用,并提供代码示例。 一、MapReduce的原理 MapReduce是一种分布式计算模型,用于处理大规模数据集。它的原理可以简单概括为“分而治之”。具体来说,MapReduce将数据分...
Mapreduce执行机制之提交任务和切片原理
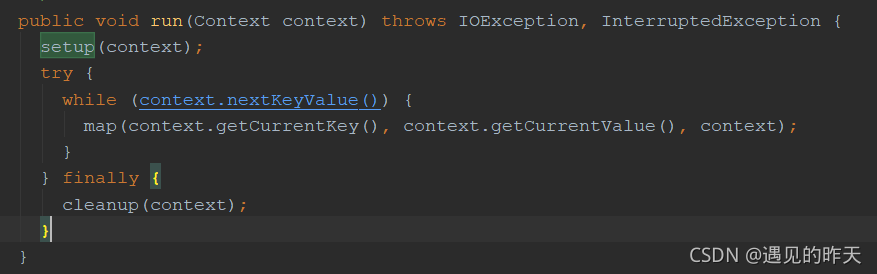
1、Mapper 类 * Maps input key/value pairs to a set of intermediate key/value pairs. * * <p>Maps are the individual tasks which transform input records into a * intermediate records. The tr...
MapReduce 原理与实践
MapReduce 简介MapReduce 核心思想Hadoop MapReduce 是一个编程框架,它可以轻松地编写应用程序,以可靠的、容错的方式处理大量的数据(数千个节点)。正如其名,MapReduce 的工作模式主要分为 Map 阶段和 Reduce 阶段。一个 MapReduce 任务(Job)通常将输入的数据集分割成独立的块,这些块被 map 任务以完全并行的方式处理。框架对映射(ma....
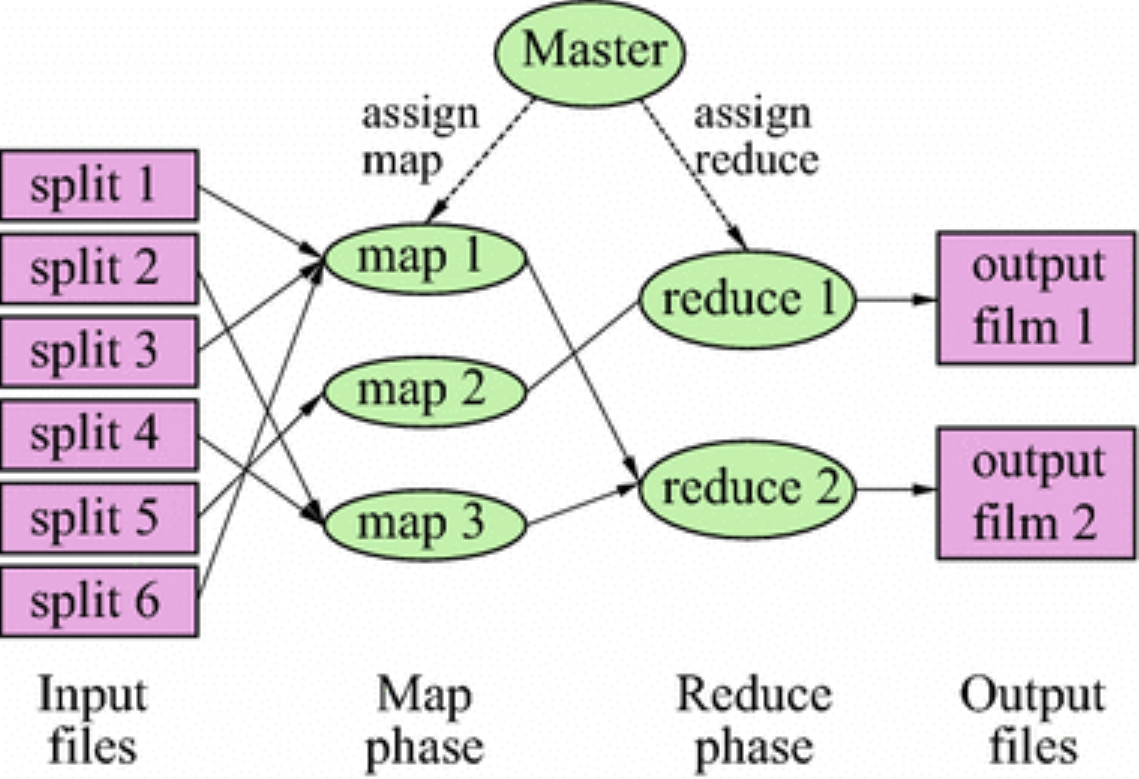
大数据基础-MapReduce原理及核心编程思想
组件模块MapReduce :MapReduce 是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和MapReduce自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。MapReduce 进程:MrAppMaster:负责整个程序的过程调度及状态协调MapTask:负责 Map 阶段的整个数据处理流程。并行处理输入数据ReduceTask:负责 ....
Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件(3)多个溢出文件会被合并成大的溢出文件(4)在溢出过程及合并的....
Hadoop中的MapReduce框架原理、切片源码断点在哪断并且介绍相关源码、FileInputFormat切片源码解析、总结,那些可以证明你看过切片的源码
@[toc]13.MapReduce框架原理13.1InputFormat数据输入13.1.3FileInputFormat切片源码解析13.1.3.1切片源码断点在哪断并且介绍相关源码:断点在https://blog.csdn.net/Redamancy06/article/details/126501627?spm=1001.2014.3001.5501这篇文章写了一部分了,可以先跟着这篇文....

Hadoop中的MapReduce框架原理、Job提交流程源码断点在哪断并且介绍相关源码、切片与MapTask并行度决定机制、MapTask并行度决定机制
@[toc]13.MapReduce框架原理13.1InputFormat数据输入13.1.1切片与MapTask并行度决定机制13.1.1.1问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度 思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce产品
- 开源大数据平台 E-MapReduce参数
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce dataset
- 开源大数据平台 E-MapReduce工作空间
- 开源大数据平台 E-MapReduce s3
- 开源大数据平台 E-MapReduce oss
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce文件
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce模式
- 开源大数据平台 E-MapReduce map
- 开源大数据平台 E-MapReduce版本
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
+关注