
Hadoop知识点总结——MapReduce的Shuffle
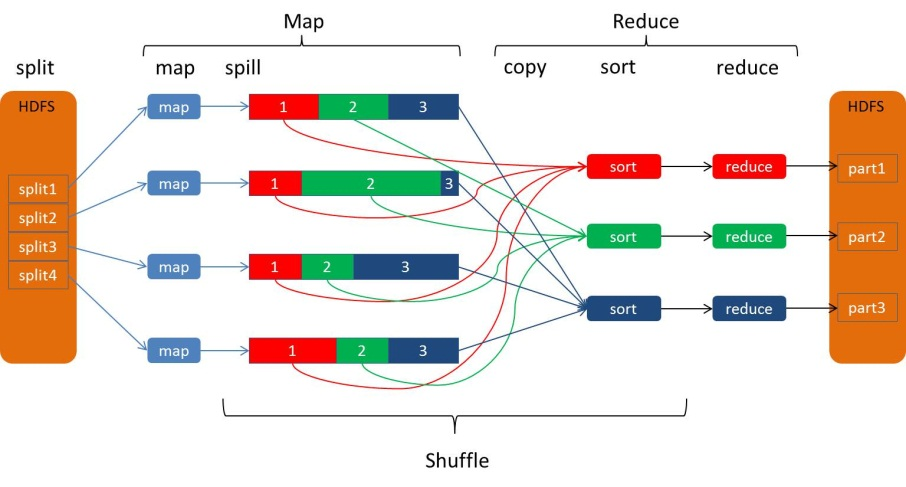
Hadoop学习之路(二十三)MapReduce中的shuffle详解 <= 以下内容出自该博客 从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示:Spill过程Spill过程包括输出、排序、溢写、合并等步骤,如图所示:Collect每个Map....
Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
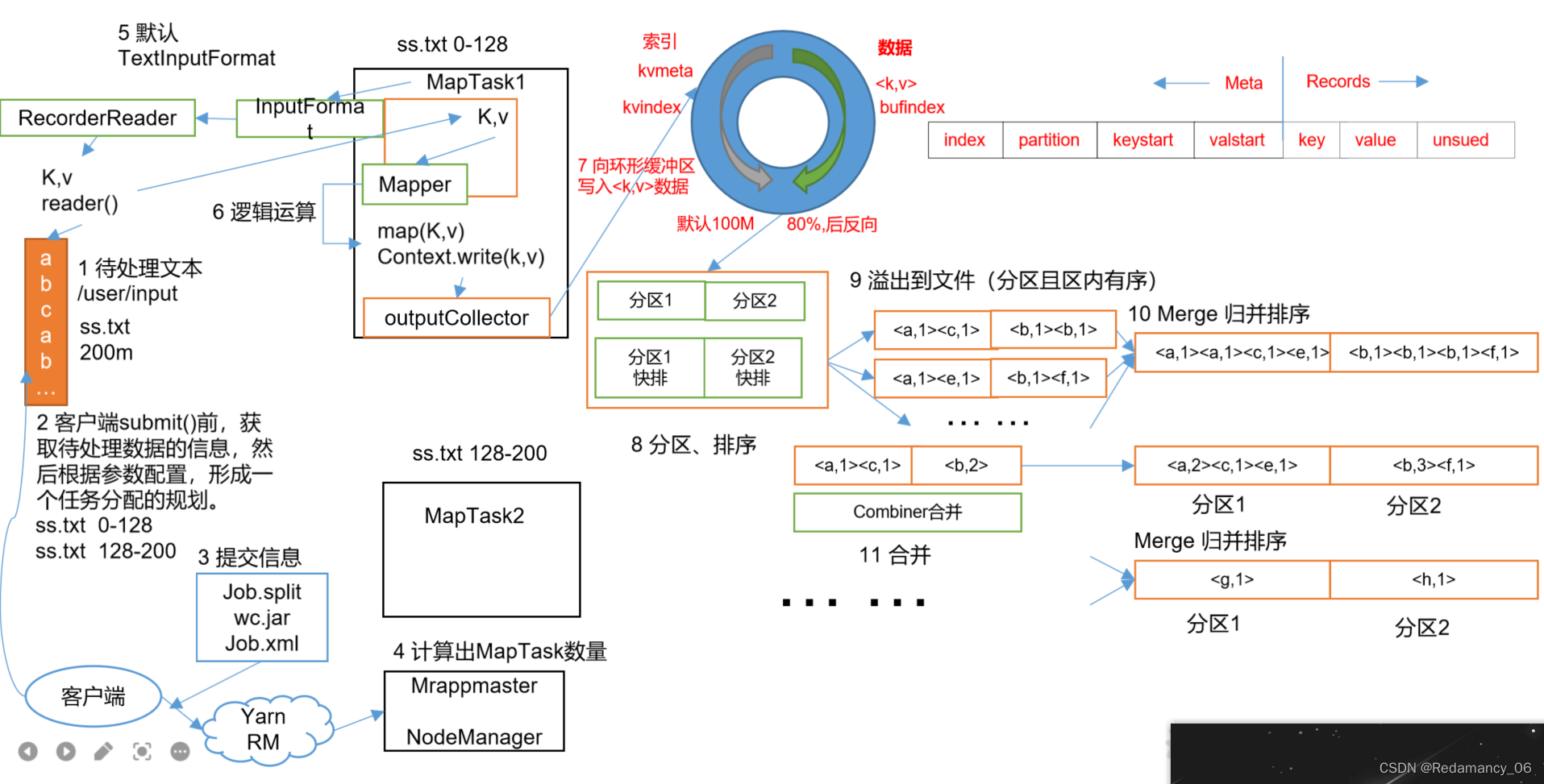
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件(3)多个溢出文件会被合并成大的溢出文件(4)在溢出过程及合并的....
MapReduce shuffle过程详解!
一、MR的shuffle过程MR的shuffle过程:input -> map -> shuffle -> reduce ->outputMR的原理图:二、Map shuffle1.map()的数据会写入到内存(环形缓冲区:默认大小:100mb),当数据达到缓冲区总容量的80%(阈值)时,会将我们的数据spill到本地磁盘1)分区(partitioner):...

有什么方法可以解决Hadoop MapReduce和早期Spark在shuffle过程中的问题?
有什么方法可以解决Hadoop MapReduce和早期Spark在shuffle过程中的问题?
mapReduce中shuffle阶段的工作流程是什么,如何优化shuffle阶段呢?
mapReduce中shuffle阶段的工作流程是什么,如何优化shuffle阶段呢?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce产品
- 开源大数据平台 E-MapReduce参数
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce dataset
- 开源大数据平台 E-MapReduce工作空间
- 开源大数据平台 E-MapReduce s3
- 开源大数据平台 E-MapReduce oss
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce文件
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce模式
- 开源大数据平台 E-MapReduce map
- 开源大数据平台 E-MapReduce版本
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
+关注