
读写HBase
基于HBase官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接HBase。本文为您介绍在EMR Serverless Spark环境中实现HBase的数据读取和写入操作。
HBase的读写操作是如何进行的?
HBase的读写操作是如何进行的?HBase是一个分布式、可扩展的列式数据库,它基于Hadoop的HDFS存储数据,并提供了高性能的读写操作。在本文中,我将使用一个具体的案例来解释HBase的读写操作是如何进行的,并提供详细的注释。假设我们有一个名为"orders"的HBase表,用于存储订单数据。每个订单都有以下列:user_id(用户ID)、product_id(产品ID)、quantity....
分布式NoSQL列存储数据库Hbase_MR集成Hbase:读写Hbase规则(九)
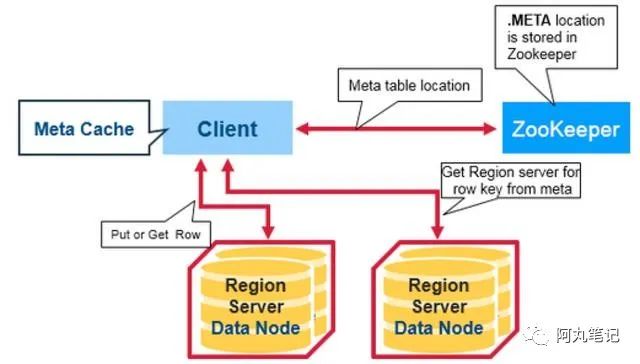
分布式NoSQL列存储数据库Hbase(九)知识点01:课程回顾简述Hbase中hbase:meta表的功能及存储内容功能:记录表的元数据信息内容rowkey:Hbase中每张表的每个Region的名称列Region名称Region范围:startKey,stopKeyRegion所在的RegionServer地址简述Hbase中数据写入流程step1:客户端连接ZK,获取meta表所在的地址,....
Python编程:happybase读写HBase数据库
happybase文档:https://happybase.readthedocs.io/en/latest/安装pip install happybase表操作import happybase # 连接数据库 connection = happybase.Connection(host='hostname', port=9090) # 查询所有表 table_name_list = conne....
深入HBase读写
1.首次读写的基本过程在上一篇 深入HBase架构(建议收藏)中已经做了介绍。这里再重申一下。这里要解决的主要问题是,client如何知道去那个region server执行自己的读写请求。有一个特殊的HBase表,叫做META table,保存了集群中各个region的位置。而这个表的位置信息是保存在zookeeper中的。因此,当我们第一次访问HBase集群时,会做以下操作:1)客户端从zk....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云数据库HBase版您可能感兴趣
- 云数据库HBase版物理
- 云数据库HBase版结构
- 云数据库HBase版存储
- 云数据库HBase版逻辑
- 云数据库HBase版开发环境
- 云数据库HBase版架构
- 云数据库HBase版hive
- 云数据库HBase版案例
- 云数据库HBase版数据库
- 云数据库HBase版类型
- 云数据库HBase版数据
- 云数据库HBase版集群
- 云数据库HBase版shell
- 云数据库HBase版hadoop
- 云数据库HBase版flink
- 云数据库HBase版表
- 云数据库HBase版报错
- 云数据库HBase版应用
- 云数据库HBase版操作
- 云数据库HBase版大数据
- 云数据库HBase版安装
- 云数据库HBase版实践
- 云数据库HBase版java
- 云数据库HBase版地址
- 云数据库HBase版查询
- 云数据库HBase版spark
- 云数据库HBase版设计
- 云数据库HBase版技术
- 云数据库HBase版region
- 云数据库HBase版场景
云原生多模数据库Lindorm
Lindorm是适用于任何规模、多种类型的云原生数据库服务,支持海量数据的低成本存储处理和弹性按需付费,兼容HBase、Solr、SQL、OpenTSDB等多种开源标准接口,是互联网、IoT、车联网、广告、社交、监控、游戏、风控等场景首选数据库,也是为阿里巴巴核心业务提供支撑的数据库之一。
+关注