
如何通过ES-Hadoop实现Spark读写阿里云Elasticsearch数据
Spark是一种通用的大数据计算框架,拥有Hadoop MapReduce所具有的计算优点,能够通过内存缓存数据为大型数据集提供快速的迭代功能。与MapReduce相比,减少了中间数据读取磁盘的过程,进而提高了处理能力。本文介绍如何通过ES-Hadoop实现Hadoop的Spark服务读写阿里云Elasticsearch数据。
Hadoop-08-HDFS集群 基础知识 命令行上机实操 hadoop fs 分布式文件系统 读写原理 读流程与写流程 基本语法上传下载拷贝移动文件
章节内容 上一节完成: HDFS的简介内容 HDFS基础原理 HDFS读文件流程 HDFS写文件流程 背景介绍 这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。 之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。 ...

Hadoop-07-HDFS集群 基础知识 分布式文件系统 读写原理 读流程与写流程 基本语法上传下载拷贝移动文件
章节内容 上一节完成: Hadoop历史服务器配置 Hadoop历史日志聚集 Hadoop历史日志可视化 背景介绍 这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。 之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。 ...

【揭秘Hadoop背后的秘密!】HDFS读写流程大曝光:从理论到实践,带你深入了解Hadoop分布式文件系统!
Hadoop 分布式文件系统(HDFS)是 Hadoop 生态系统中的核心组件之一,旨在提供高吞吐量的数据访问能力,非常适合大规模数据集的分布式存储。本文将详细探讨 HDFS 中的数据读写流程,并通过示例代码展示具体的操作步骤。 HDFS 的设计目标是支持海量数据的存储和处理,因此其架构中包含 NameNode 和 DataNode。Nam...
【Hadoop】HDFS 读写流程
当我们谈论大数据时,就不得不提到HDFS,即Hadoop分布式文件系统。它是Apache Hadoop项目的核心组件之一,被设计用来存储和处理大规模数据集。那么,HDFS是如何实现读写数据的呢?让我来详细解析一下。 HDFS概述 在深入了解HDFS的读写流程之前,让我们先了解一下HDFS的基本概念。HDFS采用了一种称为“块”的存储方式,将大文件划分成若干个大小相等的块,通常默认大小为1...

如何通过ES-Hadoop实现Hive读写阿里云Elasticsearch数据_检索分析服务 Elasticsearch版(ES)
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。本文介绍通过ES-Hadoop组件在Hive上进行Elasticsearch数据的查询和写入,帮助您将...
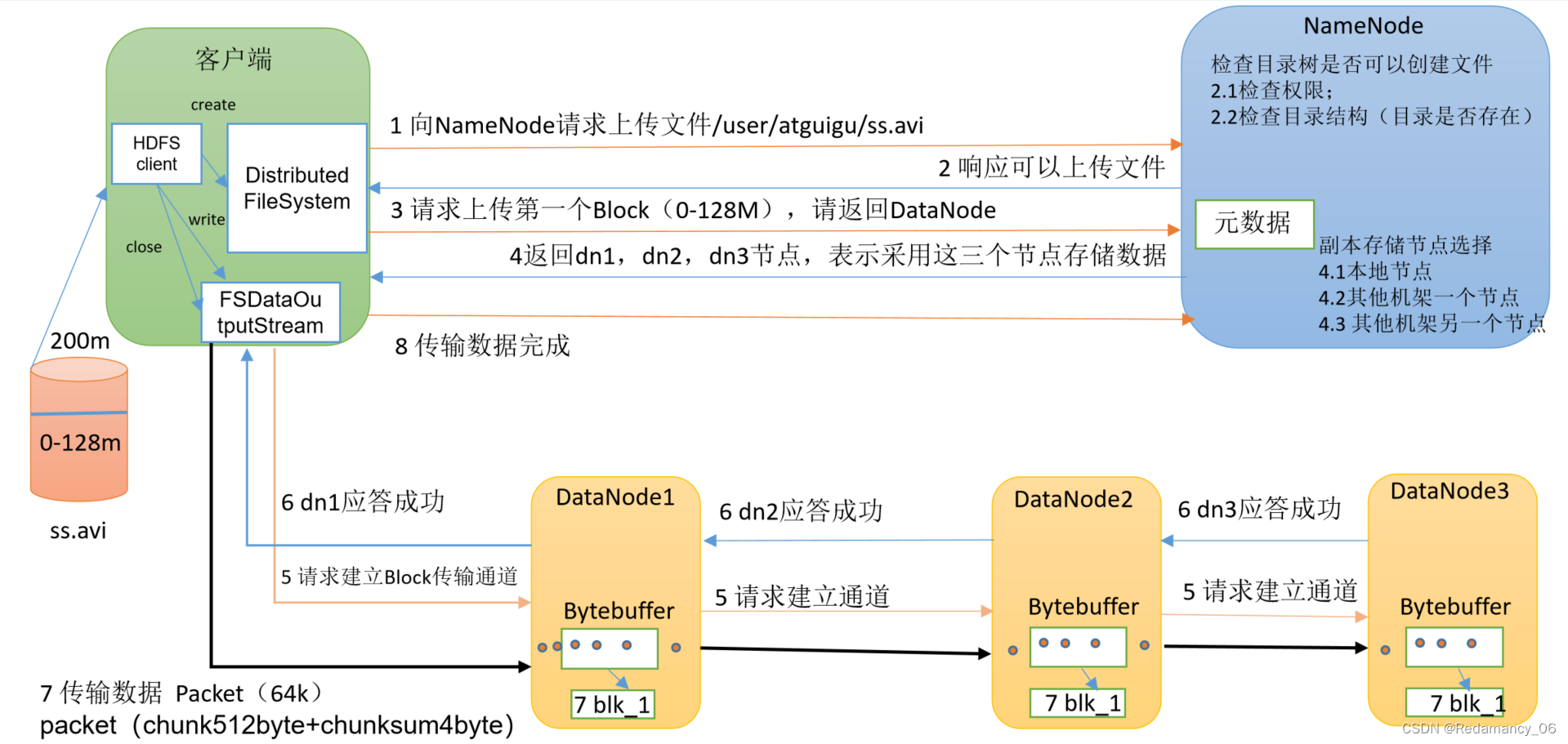
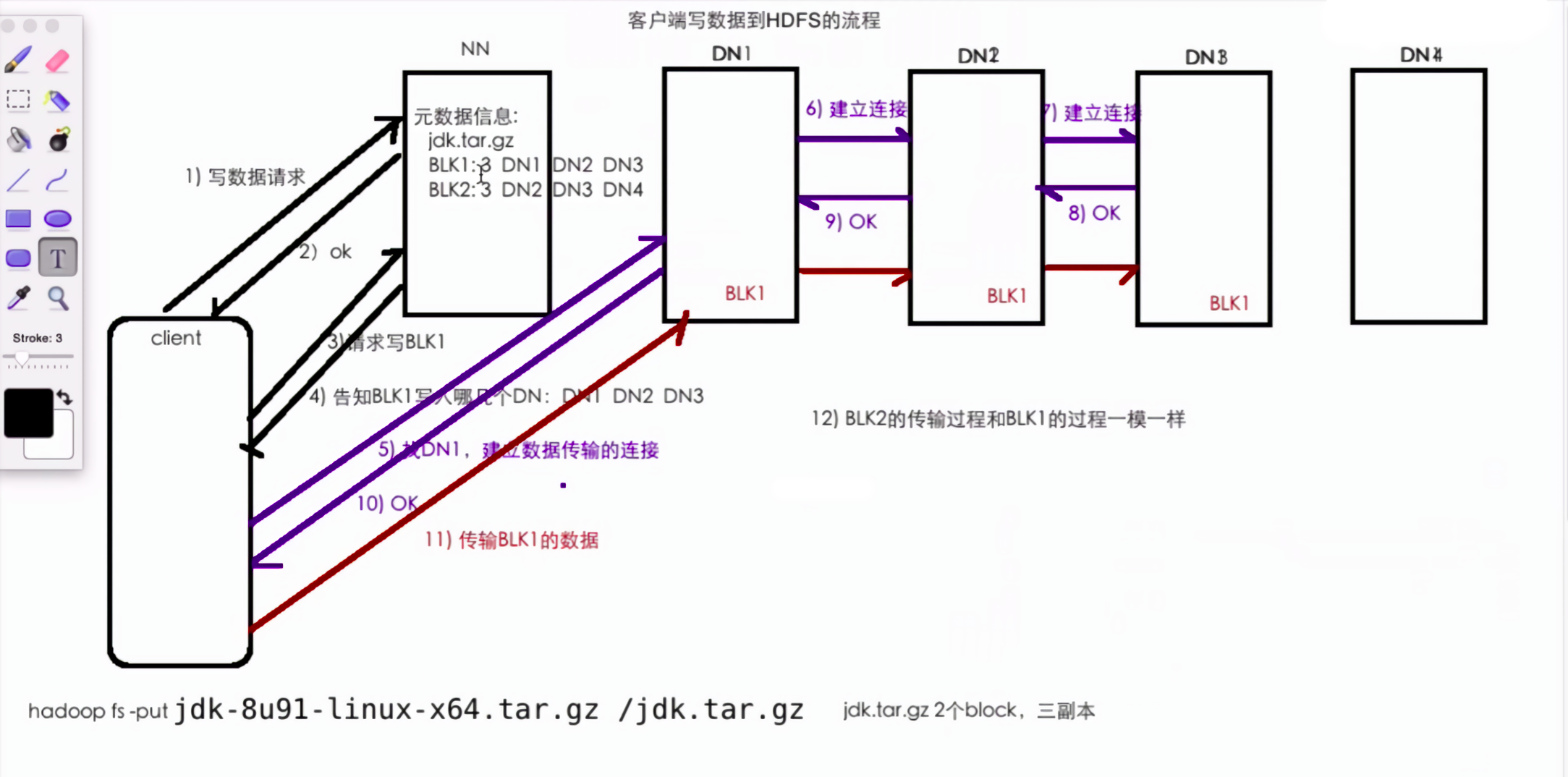
Hadoop中HDFS的读写流程(面试重点)、为什么搜不到BlockPlacementPolicyDefault、网络拓扑-节点距离计算、机架感知(副本存储节点选择)
@[toc]8.HDFS的读写流程(面试重点)8.1HDFS写数据流程8.1.1剖析文件写入(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。(2)NameNode返回是否可以上传。(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。(4)NameNode返回3个DataNo....
Java: Hadoop文件系统的读写操作
所需jar包路径:hadoop-2.8.5/share/hadoop/common hadoop-2.8.5/share/hadoop/common/bin hadoop-2.8.5/share/hadoop/hdfs hadoop-2.8.5/share/hadoop/hdfs/binjava代码实例import org.apache.hadoop.conf.Configuration; im....
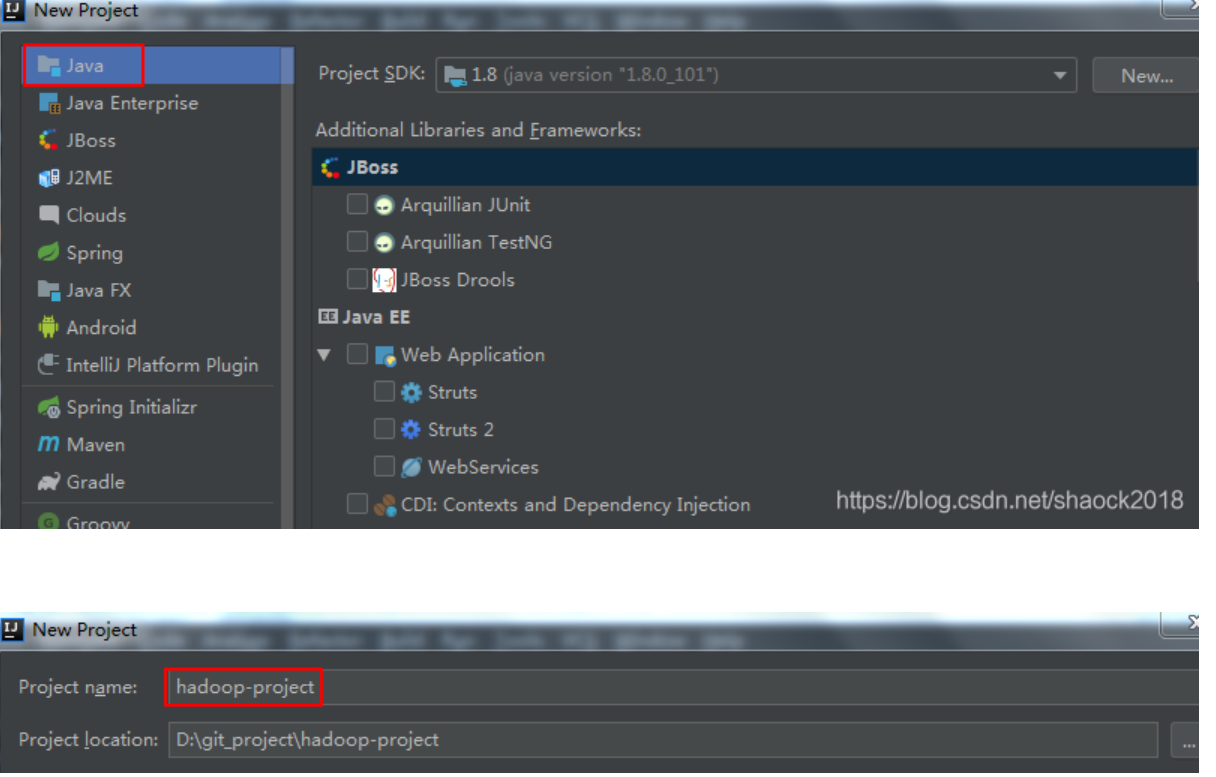
IntelliJ IDEA实现Hadoop读写HDFS文件(非Maven、离线版)
0x00 教程内容新建Java项目编写HDFS读写代码打包到服务器执行实验前提:a. 安装好了JDK0x01 新建Java项目1. 新建Java项目a. 新建一个Java项目,配置好Project SDK,然后Next,Next,起个有意义的项目名hadoop-project:b. 如果有提示,可以随便选一个2. 项目配置a. 右击src,建一个包,比如:com.shaonaiyib. 然后编辑....
Hadoop基础-06-HDFS数据读写
源码见:https://github.com/hiszm/hadoop-trainHDFS写数据HDFS读数据元数据HDFS的目录结构以及每个文件的BLOCK信息(id,副本系数,存储的位置[ { hadoop/tmp/dir } ] /name/.......)CheckpointSaveMode
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop您可能感兴趣
- hadoop开发环境
- hadoop hbase
- hadoop集群
- hadoop数据处理
- hadoop数据分析
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop技术
- hadoop大数据
- hadoop hdfs
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop分布式
- hadoop数据
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作