
Hadoop 生态圈中的组件如何协同工作来实现大数据处理的全流程
Hadoop 生态圈中的各个组件通过协同工作实现了大数据处理的完整流程,具体过程如下: 数据摄取和预处理: Flume 可以收集和聚集各种来源的大数据,如日志、传感器数据等,并将其流式传输到 HDFS 中存储。Sqoop 用于在关系型数据库和 HDFS 之间进行批量数据传输。 数据存储: HDFS 提供了分布式的、容错的文件系统,可以存储大规模的结构化和非结构化数据。HBase 为需要实时随机访....
Hadoop生态圈组件及其作用
Hadoop 生态圈是一个庞大的系统,包含了许多不同的组件,每个组件都有其特定的功能和作用。以下是 Hadoop 生态圈中一些主要的组件及其作用: HDFS (Hadoop Distributed File System): HDFS 是 Hadoop 的核心组件,提供了一个分布式的文件系统,用于存储大规模数据。它具有高容错性、高吞吐量和海量存储的特点。 MapReduce: MapReduce....
Hadoop生态系统介绍(二)大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 具有可靠、高效、可伸缩的特点。 Hadoop的核心是YARN,HDFS和Mapreduce 下图是hadoop生态系统,集成spark生态圈。在未来一段时间内,ha...

部分大数据相关的都要用到python这是为什么?Hadoop整个生态圈都是Java的,python的
部分大数据相关的都要用到python这是为什么?Hadoop整个生态圈都是Java的,python的定位是什么?
大数据Hadoop生态圈体系视频课程
课程介绍 熟悉大数据概念,明确大数据职位都有哪些;熟悉Hadoop生态系统都有哪些组件;学习Hadoop生态环境架构,了解分布式集群优势;动手操作Hbase的例子,成功部署伪分布式集群;动手Hadoop安装和配置部署;动手实操Hive例子实现;动手实现GPS项目的操作;动手实现Kafka消息队列例子等 学习地址 链接:https://pan.baidu.com/s/1e0ve05_or2x...

04 Hadoop生态圈以及各组成部分的简介
重点组件:HDFS:分布式文件系统MAPREDUCE:分布式运算程序开发框架HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具HBASE:基于Hadoop的分布式海量数据库ZOOKEEPER:分布式协调服务基础组件Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库Oozie:工作流调度框架Sqoop:数据导入导出工具Flume:日志数据采....
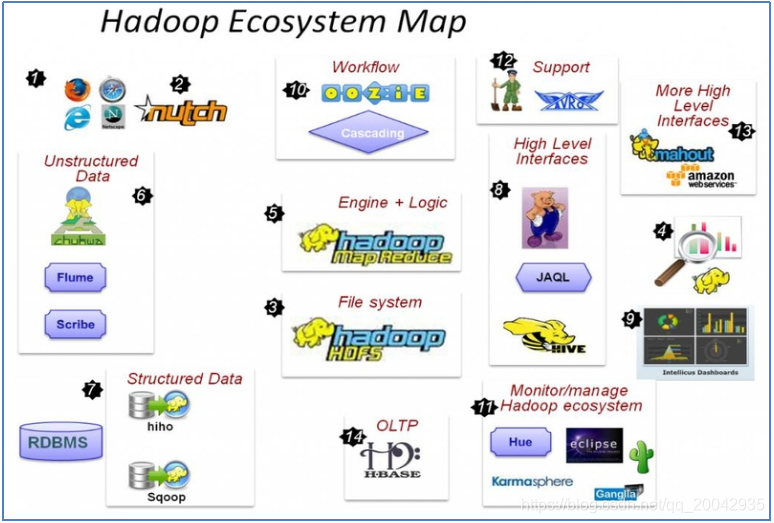
【大数据处理框架】Hadoop大数据处理框架,包括其底层原理、架构、编程模型、生态圈
Hadoop是一个开源的大数据处理框架,它包含了底层的分布式文件系统和分布式计算资源管理系统,以及高级的数据处理编程接口。底层原理Hadoop是一个开源的大数据处理框架,它的底层原理是基于分布式计算和存储的。首先,我们来了解一下HDFS。HDFS是Hadoop的核心组件之一,它是一个分布式文件系统,将文件分成多个数据块,并存储在集群中的不同节点上,每个数据块的默认大小为128MB。为了保证数据的....
大数据入门与实战-Hadoop生态圈技术总览
1 Hadoop生态圈技术纵览2 分布式概念3 HDFS 读写过程HDFS 读过程HDFS 写过程4 伪分布式集群5 MapReduceMapReduce是一个编程框架,允许我们在分布式环境中对大型数据集执行分布式和并行处理:MapReduce由两个不同的任务组成 Map和Reduce。正如MapReduce的名称所示,reducer阶段发生在mapper阶段完成之后。因此,第一个是....

【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型(二)
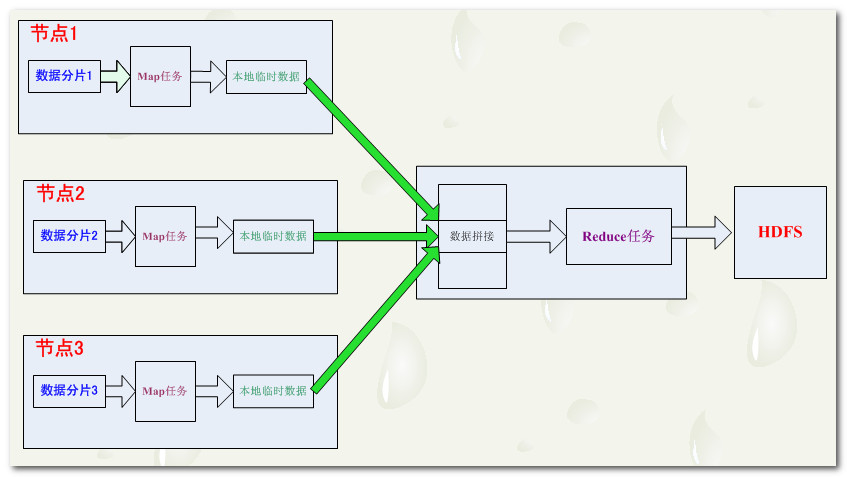
3. Reduce 数据流Reduce任务 : map 任务的数量要远远多于 Reduce 任务;-- 无本地化优势 : Reduce 的任务的输入是 Map 任务的输出, reduce 任务的绝大多数数据 本地是没有的;-- 数据合并 : map 任务 输出的结果, 会通过网络传到 reduce 任务节点上, 先进行数据的合并, 然后在输入到reduce 任务中进行处理;-- 结果输出 : r....
【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型(一)
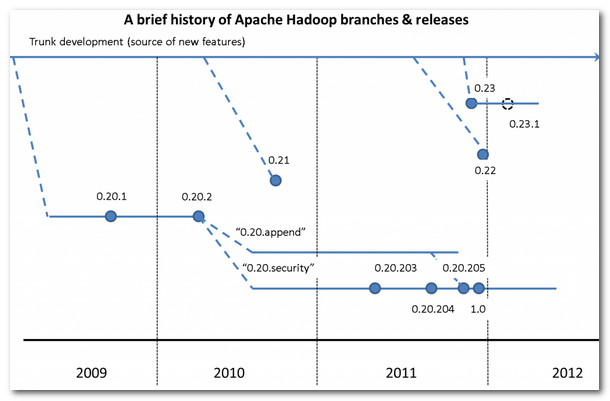
一 Hadoop版本 和 生态圈1. Hadoop版本(1) Apache Hadoop版本介绍Apache的开源项目开发流程 : -- 主干分支 : 新功能都是在 主干分支(trunk)上开发;-- 特性独有分支 : 很多新特性稳定性很差, 或者不完善, 在这些分支的独有特定很完善之后, 该分支就会并入主干分支;-- 候选分支 : 定期从主干分支剥离, 一般候选分支发布, 该分支就会停止更新新....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop您可能感兴趣
- hadoop开发环境
- hadoop hbase
- hadoop集群
- hadoop数据处理
- hadoop数据分析
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop技术
- hadoop大数据
- hadoop hdfs
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop分布式
- hadoop数据
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作