
请问下Flink,需求做一个宽表,有大量大表join,如果需要跑大数据量的历史数据该怎么处理?
请问下Flink,需求做一个宽表,有大量大表join,因此只能使用look up join,增量还可以,如果需要跑大数据量的历史数据该怎么处理?
实时计算 Flink版产品使用问题之在进行数据同步时,重新创建了一个新的任务,但发现无法删除旧任务同步的历史数据,是什么导致的
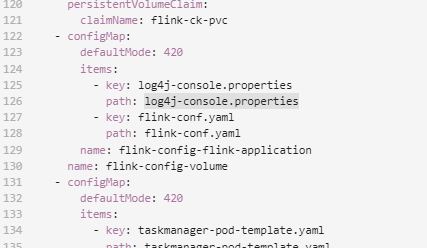
问题一:有没有 知道 flink operator 默认添加的这个 confimap 我怎么修改啊 ? 有没有 知道 flink on k8s operator , operator 默认添加的这个 confimap 我怎么修改啊 ?我重新制作了一个flink 镜像 修改了 log4j-console.properties 但是容器启动后 还是用 原来 的log4j-console.pr...
在Flink大概什么样的场景会需要用到流批一体?一边处理实时流,一边批处理历史数据
在Flink大概什么样的场景会需要用到流批一体?一边处理实时流,一边批处理历史数据
实时计算 Flink版产品使用问题之如何实现重启后直接跑最新的任务而不是根据checkpoint跑历史数据
问题一:这种场景阿里云flink引擎有计划吗? flink 去 lookup join 一张实时写入的维表,在join不到情况下,加入缓存,然后delay retry。这种场景阿里云flink引擎有计划吗? 参考答案: 阿里云Flink引擎确实提供了一些功能来支持维表join操作的优化,但关于特定场景下“实时写入的维表在join不到时加入缓存并延迟重试...
实时计算 Flink版产品使用问题之kafka2hive同步数据时,如何回溯历史数据
问题一:flink中,join如果不指定窗口,会把join结果一直存储下来吗? flink中,join如果不指定窗口,会把join结果一直存储下来吗? 参考答案: Apache Flink 中,如果不指定窗口进行 join,join 结果不会无限期地存储下来。在无窗口的情况下进行 join,Flink 会根据数据流的到达顺序和关联键进行即时 join。...
实时计算 Flink版产品使用问题之任务在同步过程中新增同步表后选择全量初始化历史数据,是否会阻塞原先其余表的增量同步
问题一:Flink cdc在同步过程中新增同步表后选择全量初始化历史数据,会阻塞原先其余表的增量同步吗? Flink cdc任务在同步过程中新增同步表后选择全量初始化历史数据,会阻塞原先其余表的增量同步么? 参考答案: 新增表不影响其他,有个feature是新增表不断流。增量数据从任务开始就在同步了。历史数据同步及binlog同步在全量阶段是并行执行的...

实时计算 Flink版产品使用合集之全量历史数据比较多,全量同步阶段时间长,是否会同时读取binlog进行合并输出
问题一:Flink CDC这个意思是全量阶段也会进行binlog消费吧? Flink CDC这个意思是全量阶段也会进行binlog消费吧? 参考答案: 全量阶段走的jdbc不消费binlog 关于本问题的更多回答可点击进行查看: https://developer.aliyun.com/ask/582302 ...

实时计算 Flink版产品使用合集之从MySQL同步数据到Doris时,历史数据时间字段显示为null,而增量数据部分的时间类型字段正常显示的原因是什么
问题一:Flink CDC这个案例我是跑不了,不知道问题出在哪里? Flink CDC这个案例我是跑不了,不知道问题出在哪里? ...
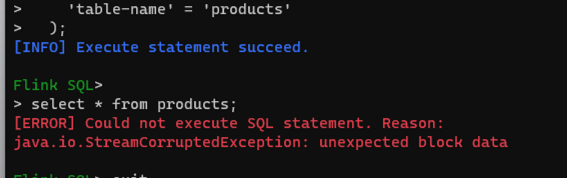
Flink CDC里用的datastream,不知道为什么每次都会消费历史数据?
Flink CDC里用的datastream,不知道为什么每次都会消费历史数据?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
实时计算 Flink版历史数据相关内容
实时计算 Flink版您可能感兴趣
- 实时计算 Flink版银行
- 实时计算 Flink版实战
- 实时计算 Flink版案例
- 实时计算 Flink版CEP
- 实时计算 Flink版云上
- 实时计算 Flink版批计算
- 实时计算 Flink版增量
- 实时计算 Flink版构建
- 实时计算 Flink版最佳实践
- 实时计算 Flink版数仓
- 实时计算 Flink版CDC
- 实时计算 Flink版数据
- 实时计算 Flink版SQL
- 实时计算 Flink版mysql
- 实时计算 Flink版报错
- 实时计算 Flink版同步
- 实时计算 Flink版任务
- 实时计算 Flink版实时计算
- 实时计算 Flink版flink
- 实时计算 Flink版版本
- 实时计算 Flink版oracle
- 实时计算 Flink版kafka
- 实时计算 Flink版表
- 实时计算 Flink版配置
- 实时计算 Flink版产品
- 实时计算 Flink版Apache
- 实时计算 Flink版设置
- 实时计算 Flink版作业
- 实时计算 Flink版模式
- 实时计算 Flink版数据库
实时计算 Flink
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
+关注