
使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主要从事数据方面的工作,包...

Apache Hudi在Linkflow构建实时数据湖的生产实践
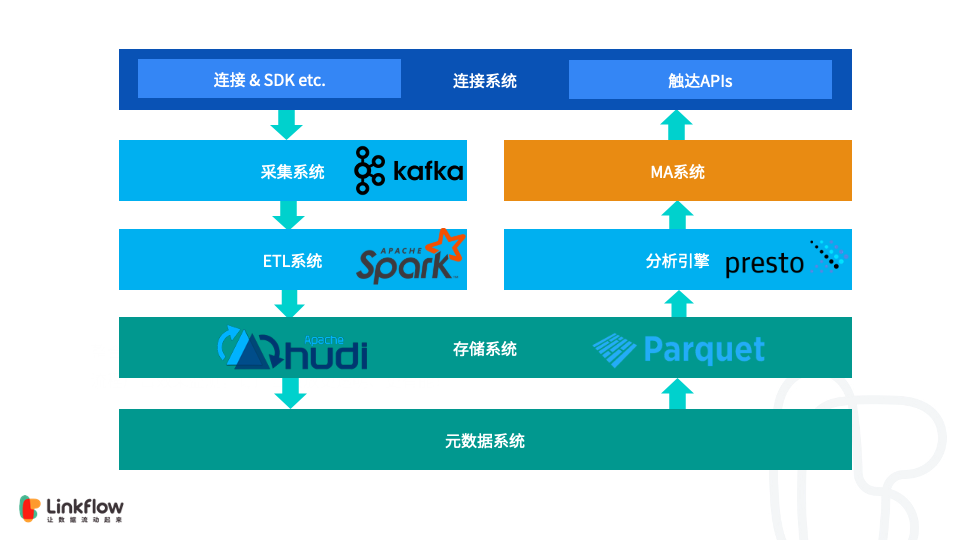
1. 背景 Linkflow 作为客户数据平台(CDP),为企业提供从客户数据采集、分析到执行的运营闭环。每天都会通过一方数据采集端点(SDK)和三方数据源,如微信,微博等,收集大量的数据。这些数据都会经过清洗,计算,整合后写入存储。使用者可以通过灵活的报表或标签对持久化的数据进行分析和计算,结果又会作为MA (Marketing Automation) 系统的数据源,从而实现对特定人群...
字节跳动基于Apache Hudi构建EB级数据湖实践
接下来将分为场景需求、设计选型、功能支持、性能调优、未来展望五部分介绍Hudi在字节跳动推荐系统中的实践。 ...


基于 Apache Hudi 构建分析型数据湖
为了更好地发展业务,每个组织都在迅速采用分析。在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能。通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特定受众。只有当我们能够大规模提供分析时,这一切才有可能。 对数据湖的需求 在 NoBrokercom[1],出于操作目的,事务数据存储在基于 SQL 的数据库中,事件数据存储在 No-S...
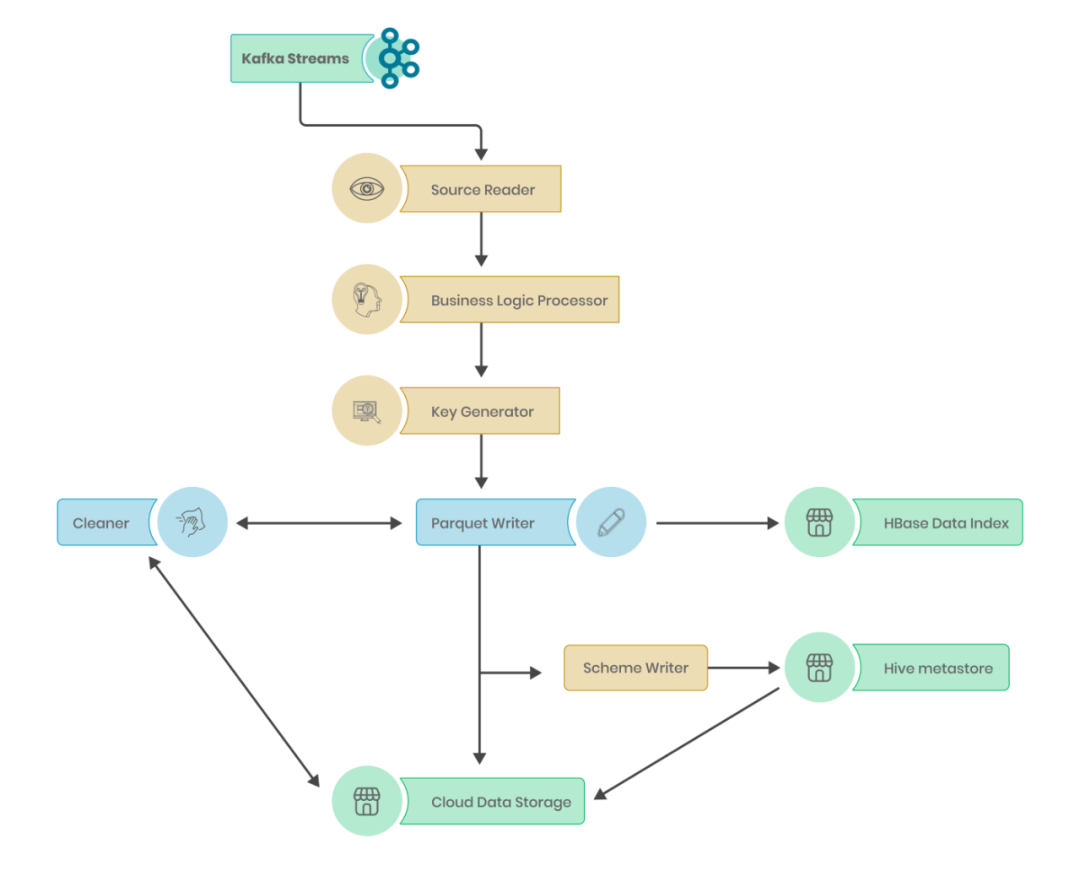
基于Apache Hudi + MinIO 构建流式数据湖
Apache Hudi 是一个流式数据湖平台,将核心仓库和数据库功能直接引入数据湖。Hudi 不满足于将自己称为 Delta 或 Apache Iceberg 之类的开放文件格式,它提供表、事务、更新/删除、高级索引、流式摄取服务、数据聚簇/压缩优化和并发性。Hudi 于 2016 年推出,牢牢扎根于 Hadoop 生态系统,解释了名称背后的含义:Hadoop Upserts Deletes a....

Uber基于Apache Hudi增量 ETL 构建大规模数据湖
Uber 的全球数据仓库团队使用统一的、 PB 级、集中建模的数据湖使所有 Uber 的数据民主化。数据湖由使用维度数据建模技术[1]开发的基础事实、维度和聚合表组成,工程师和数据科学家可以自助方式访问这些表,为 Uber 的数据工程、数据科学、机器学习和报告提供支持。因此,计算这些表的 ETL(提取、转换、加载)管道对 Uber 的应用程序和服务至关重要,为乘客安全、ETA 预测、欺诈检测等核....

基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品。多年来数据以多种方式存储在计算机中,包括数据库、blob存储和其他方法,为了进行有效的业务分析,必须对现代应用程序创建的数据进行处理和分析,并且产生的数据量非常巨大!有效地存储数PB数据并拥有必要的工具来查询它以便使用它至关重要,只有....
基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化。虽然能够在海量批处理场景中取得不错的效果,但依然存在如下现状问题:问题一:不支持事务由于传统大数据方案不支持事务,有可能会读到未写完成的数据,造成数据统计错误。为了规避该问题,通常控制读写任务顺序调用,在保....

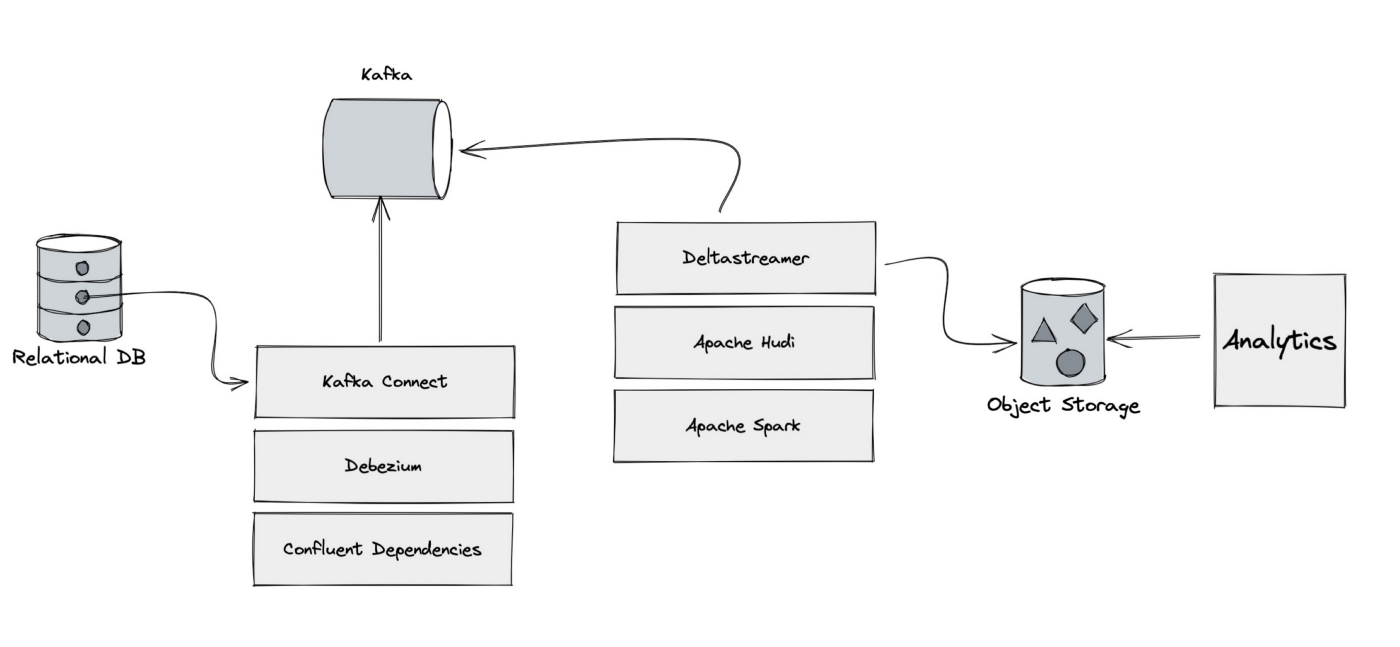
使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好、更快的决策。Amazon Simple Storage Service(amazon S3)是针对结构化和非结构化数据的高性能对象存储服务,可以用来作为数据湖底层的存储服务。然而许多用例,如从上游关系数据库执行变更数据捕获(CDC)到基于Amazon S3的数据湖,都需要在记录级....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache hudi相关内容
- Apache hudi lakehouse
- hudi Apache
- Apache hudi s3
- Apache hudi最佳实践
- Apache hudi架构
- Apache hudi cdc
- Apache hudi构建管道
- Apache hudi管道
- Apache hudi分析
- Apache hudi存储
- Apache hudi场景
- Apache hudi索引分析
- Apache hudi索引
- hudi Apache索引分析
- Apache hudi deltalake
- Apache hudi示例
- 数据湖Apache hudi
- Apache hudi zeppelin
- Apache hudi集成
- Apache hudi应用场景
- 实战Apache hudi
- 实战datadog监控Apache hudi
- Apache hudi事务
- Apache hudi大规模数据湖
- Apache hudi数据湖
- Apache hudi迁移机制
- Apache hudi异步compaction
- Apache hudi异步部署
- Apache hudi异步
- Apache hudi amazon emr
Apache更多hudi相关
- Apache hudi运行
- Apache hudi功能
- 技术Apache hudi
- 查询Apache hudi
- Apache hudi方案
- Apache hudi构建lakehouse
- Apache hudi实时数据湖
- Apache hudi数据湖实践
- Apache hudi构建实时数据湖
- Apache pulsar hudi构建lakehouse方案
- Apache hudi平台
- Apache hudi概念
- Apache hudi流批一体实践
- Apache hudi核心概念
- Apache hudi模式
- Apache hudi机制
- Apache hudi实战
- Apache hudi清理
- Apache hudi aws
- Apache hudi湖仓一体
- Apache hudi流批一体
- Apache hudi数据集
- Apache hudi构建平台
- Apache hudi类型
- Apache hudi流式
- Apache hudi payload
- Apache hudi流批一体架构
- Apache hudi数据湖平台
- Apache hudi湖仓
- Apache hudi特性
Apache您可能感兴趣
- Apache php版本
- Apache mysql
- Apache php
- Apache湖仓
- Apache湖仓一体
- Apache架构
- Apache doris
- Apache php7.1
- Apache方法
- Apache编译
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache实践
- Apache日志
- Apache应用
- Apache web

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注