
Hadoop-08-HDFS集群 基础知识 命令行上机实操 hadoop fs 分布式文件系统 读写原理 读流程与写流程 基本语法上传下载拷贝移动文件
章节内容 上一节完成: HDFS的简介内容 HDFS基础原理 HDFS读文件流程 HDFS写文件流程 背景介绍 这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。 之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。 ...

Hadoop基础学习---5、MapReduce概述和WordCount实操(本地运行和集群运行)、Hadoop序列化
1、MapReduce概述1.1 MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。1.2 MapReduce的优缺点1.2.1 优点1、易于编程它简单的实现一些接口,就可以完成一个分布式....
Hadoop原理与技术——Hbase实操
1:start-all.sh开启hadoop相关进程2: start-hbase.sh启动hbase3: jps查看启动的进程情况3: hbase shell进入hbase4: list显示所有表http://localhost:16010/master-status5: create ‘rg34’,’f1’,’f2’,’f3’创建rg34表,f1,f2,f3为列族6: describe ‘rg....

hadoop完全分布式环境搭建实操(6)
完全分布式环境搭建实操1.前提条件默认你已经安装好了一台 伪分布式环境,我的是bigdata121默认你已经看了前面的第5篇文章,完全分布式的规划和步骤,现在只讲实际操作2.修改伪分布式环境的几个hadoop的配置文件需要配置的文件bigdata121的配置文件core-site.xml(不需要改)<configuration> <!-- 指定HDFS中NameNode的地址 ....

Hadoop序列化、概述、自定义bean对象实现序列化接口(Writable)、序列化案例实操、编写流量统计的Bean对象、编写Mapper类、编写Reducer类、编写Driver驱动类
@[toc]12.Hadoop序列化12.1序列化概述12.1.1什么是序列化序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。 反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。12.1.2为什么要序列化一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被....
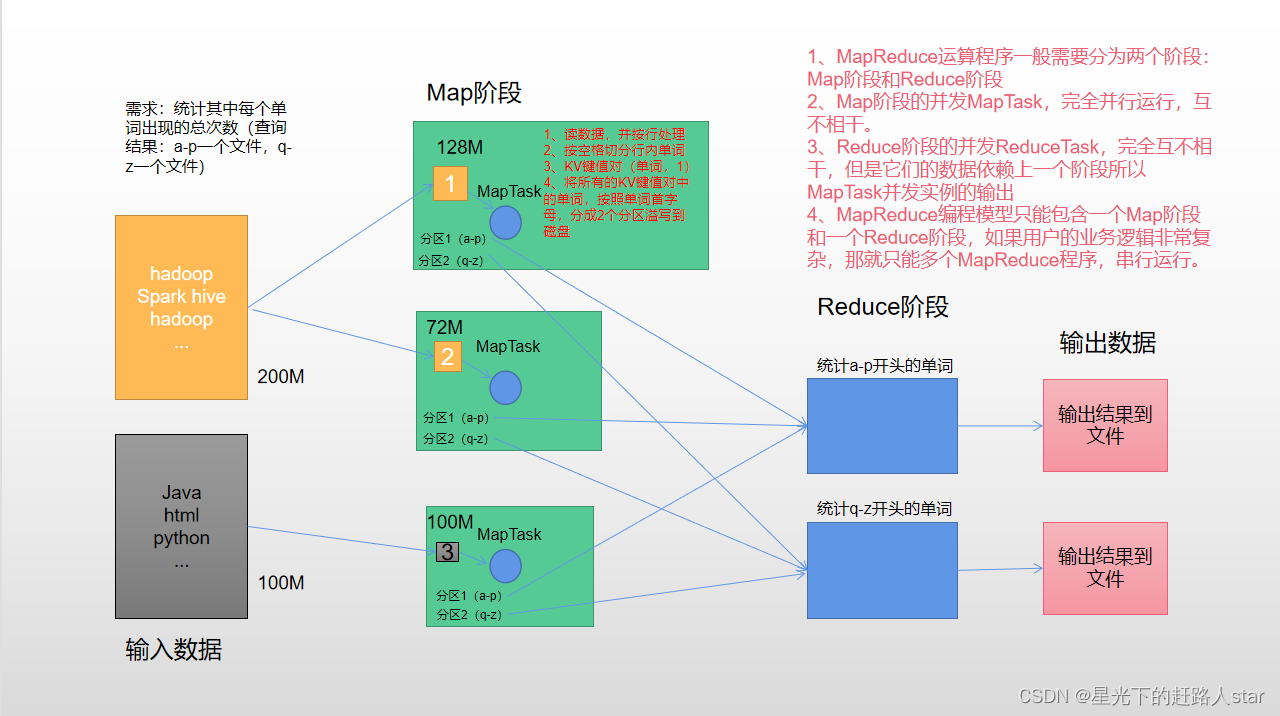
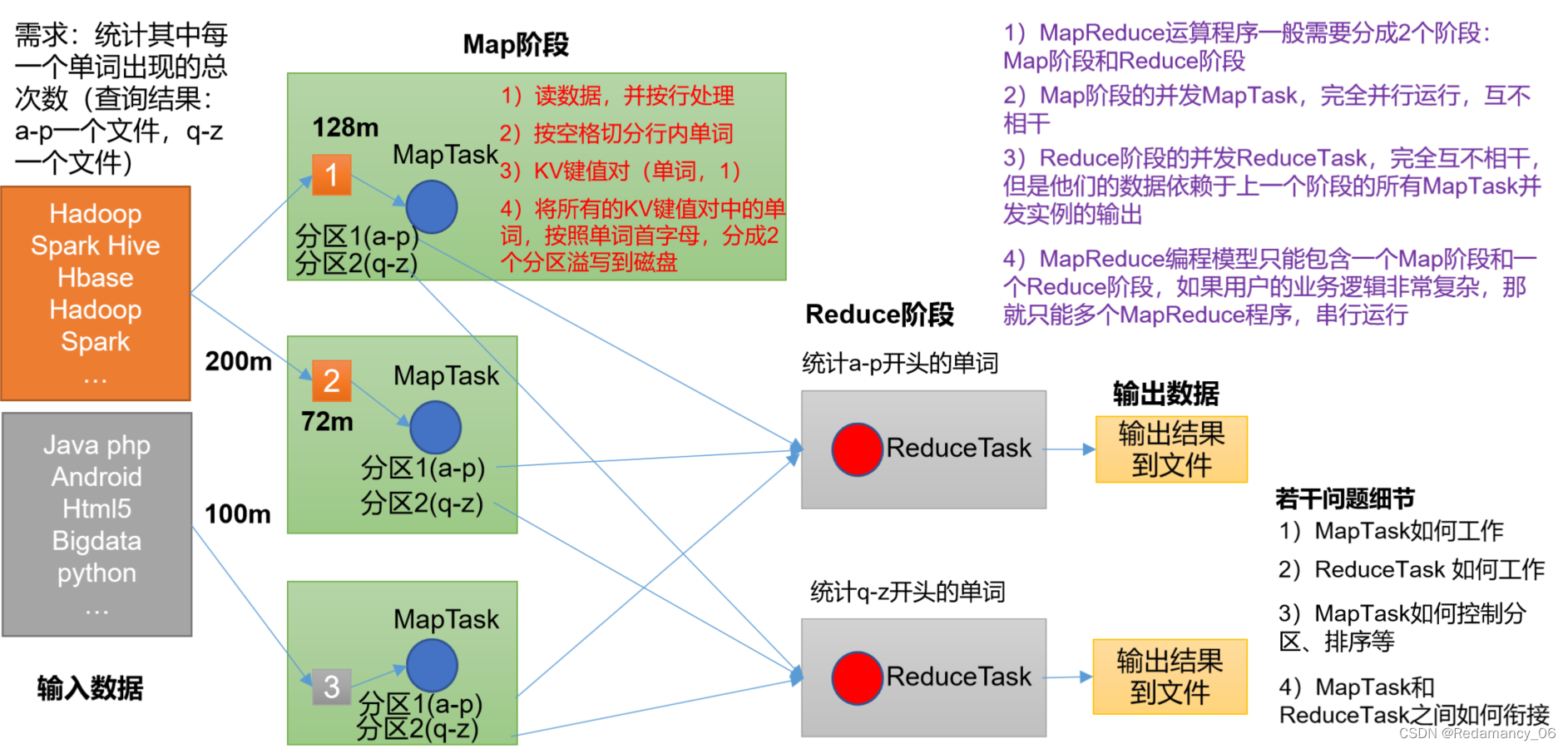
Hadoop中的MapReduce概述、优缺点、核心思想、编程规范、进程、官方WordCount源码、提交到集群测试、常用数据序列化类型、WordCount案例实操
@[toc]11.MapReduce概述11.1MapReduce定义 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。11.2MapReduce优缺点11.2.1优点11.2.1.1MapReduce....
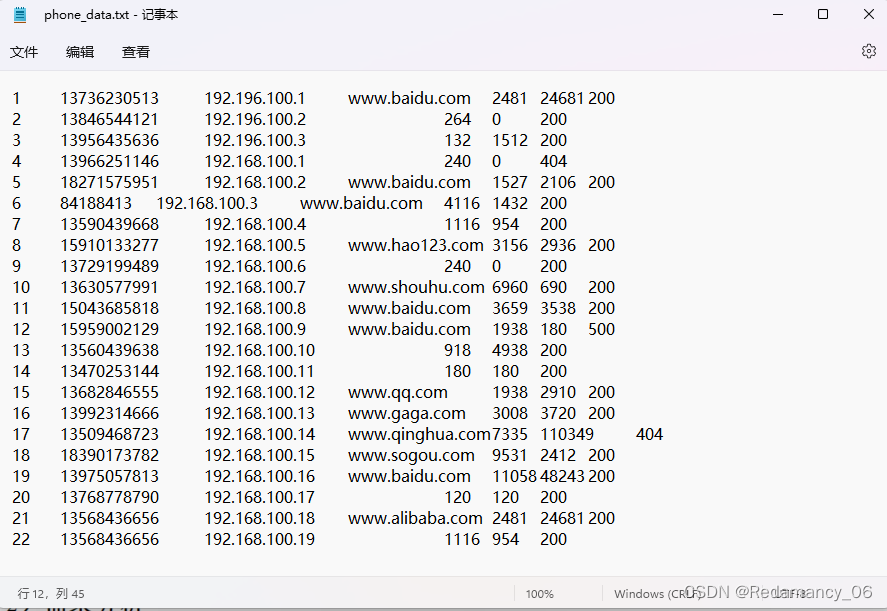
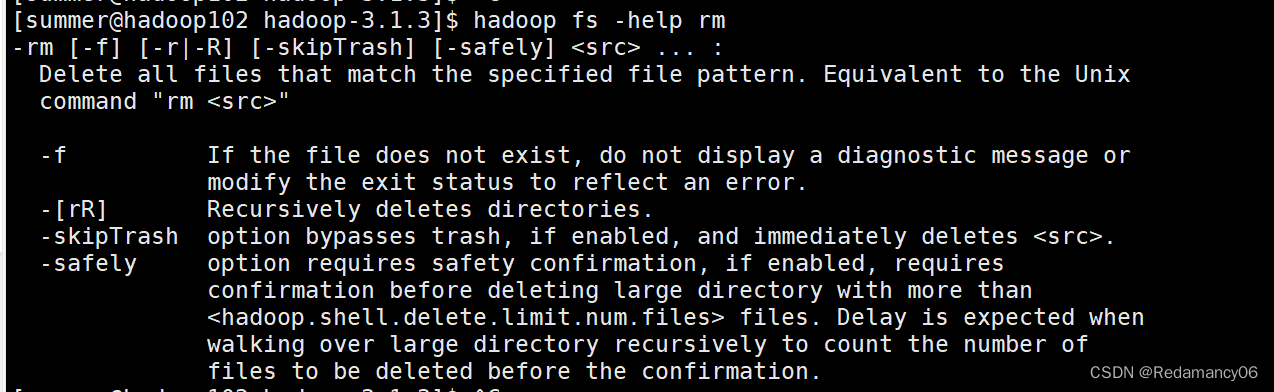
Hadoop中HDFS的Shell操作(开发重点)、启动Hadoop集群、基本语法、常用命令实操、命令大全、-help、-mkdir、-moveFromLocal、-copyFromLocal
@[toc]6.HDFS的Shell操作(开发重点)6.1基本语法hadoop fs 具体命令 OR hdfs dfs 具体命令两个是完全相同的6.2命令大全[atguigu@hadoop102 hadoop-3.1.3]$ bin/hadoop fs [-appendToFile <localsrc> ... <dst>] [-cat [-igno...
Hadoop压缩机制及实操
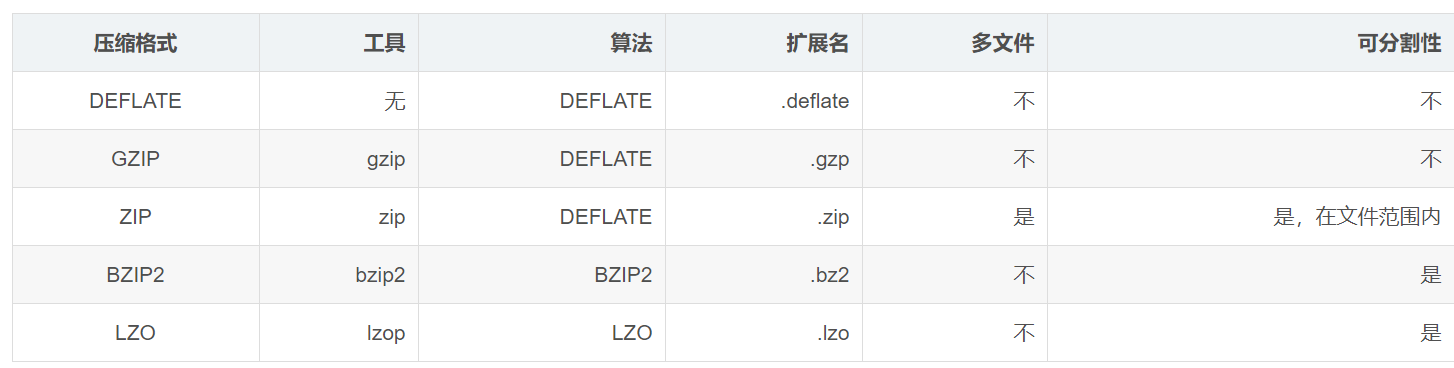
0x00 文章内容Hadoop压缩机制代码实操压缩是一种通过特定的算法来减小计算机文件大小的机制。这种机制是一种很方便的发明,尤其是对网络用户,因为它可以减小文件的字节总数,使文件能够通过较慢的互联网连接实现更快传输,此外还可以减少文件的磁盘占用空间。——摘自百度百科简而言之,通过一定的算法对数据进行特殊编码,使得数据存储的空间更小,此过程称为压缩,反之为解压缩,与Windows和Mac或者手机....
Hadoop的序列化与反序列化实操
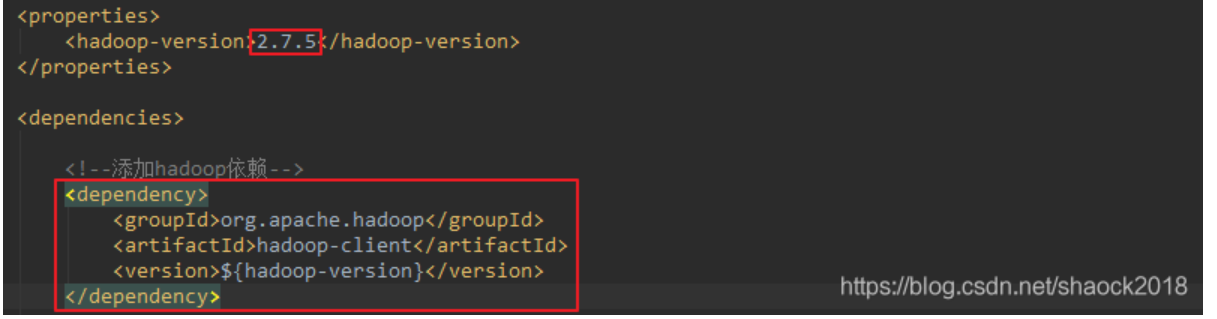
0x00 文章内容编写代码测试结果0x01 编写代码前提:因为需要用到Hadoop,所以需要先引入Hadoop相关的jar包<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <ve...
【Hadoop】(四)Hadoop 序列化 及 MapReduce 序列化案例实操
文章目录1 序列化概述2 自定义bean对象实现序列化接口(Writable)3 序列化案例实操1 序列化概述2 自定义bean对象实现序列化接口(Writable)在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。具体实现bean对象序列化步骤如下7步。(1)必须实现Writable接口(2)反序列化时,需要反....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop实操相关内容
hadoop您可能感兴趣
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop分布式
- hadoop系统
- hadoop存储
- hadoop解析
- hadoop大数据处理
- hadoop大数据
- hadoop集群
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop spark
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作