
流计算引擎数据问题之在 Spark Structured Streaming 中水印计算和使用如何解决
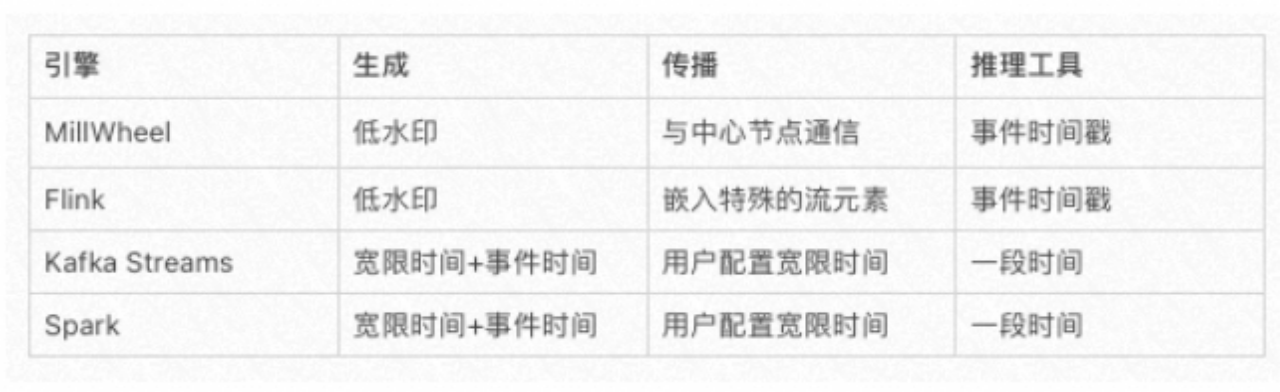
问题一:Apache Kafka Streams 的完整性推理过程是怎样的? Apache Kafka Streams 的完整性推理过程是怎样的? 参考回答: Apache Kafka Streams 的完整性推理过程不使用流中嵌入的特殊元信息或系统级低水印时间戳,而是允许通过在每个算子上配置宽限期来进行细粒度的完整性确定。生产阶段,事件流经算子时,算...
如何通过Spark Structured Streaming流式写入Iceberg表
本文为您介绍如何通过Spark Structured Streaming流式写入Iceberg表。
Spark Structured Streaming 和 Kafka 在数据完整性推理上有何不足?
Spark Structured Streaming 和 Kafka Streams 在数据完整性推理上有何不足?
在 Spark Structured Streaming 中,水印是如何计算和使用的?
在 Spark Structured Streaming 中,水印是如何计算和使用的?
在 Spark Structured 中,为什么全局水印的设计可能会导致不正确的聚合结果?
在 Spark Structured Streaming 中,为什么全局水印的设计可能会导致不正确的聚合结果?
大数据Spark Structured Streaming集成 Kafka
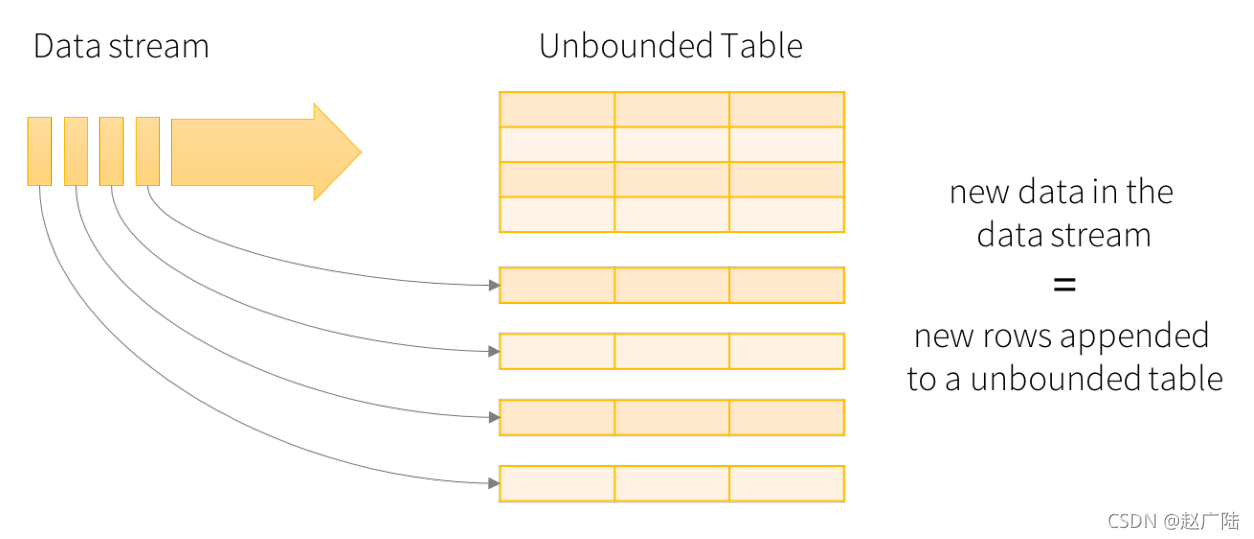
1 Kafka 数据消费Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。StructuredStreaming很好的集成Kafka,可以从Kafka拉取消息,然后就可以把流数据看做一个DataFrame, 一张无限增长的大表,在这个大表上做查询,Structured Stre....
大数据Spark Structured Streaming 2
2.3 编程模型Structured Streaming将流式数据当成一个不断增长的table,然后使用和批处理同一套API,都是基于DataSet/DataFrame的。如下图所示,通过将流式数据理解成一张不断增长的表,从而就可以像操作批的静态数据一样来操作流数据了。在这个模型中,主要存在下面几个组成部分:第一部分:Input Table(Unbounded Table),流式数据的抽象表示,....
大数据Spark Structured Streaming 1
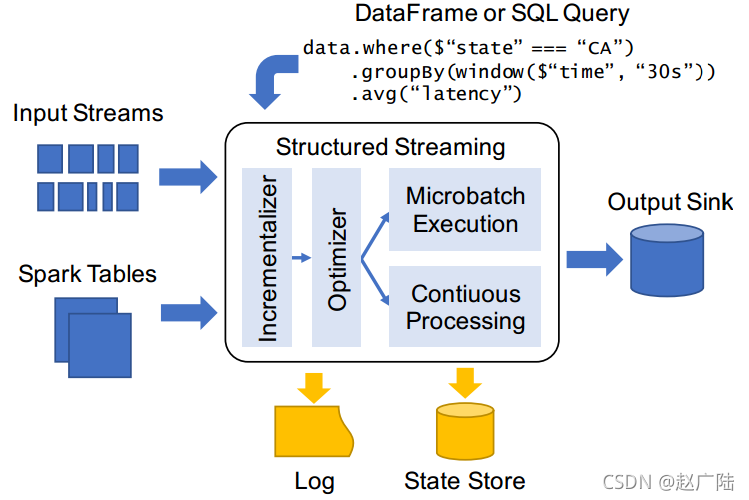
1 Spark Streaming 不足Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。个人总结:spark Streaming就是对RDD进行批量处理,Structured Streaming就相当于Spark....
5万字Spark全集之末尾Structured Streaming续集!!!!!(二)
6、output mode每当结果表更新时,我们都希望将更改后的结果行写入外部接收器。这里有三种输出模型:1.Append mode:输出新增的行,默认模式。每次更新结果集时,只将新添加到结果集的结果行输出到接收器。仅支持添加到结果表中的行永远不会更改的查询。因此,此模式保证每行仅输出一次。例如,仅查询select,where,map,flatMap,filter,join等会支持追加模式。不支....
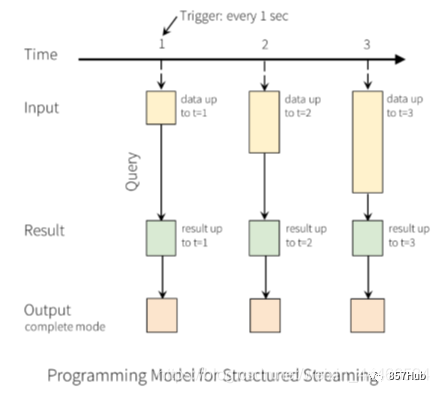
5万字Spark全集之末尾Structured Streaming续集!!!!!(一)
九、Structured Streaming曲折发展史1、Spark StreamingSpark Streaming针对实时数据流,提供了一套可扩展、高吞吐、可容错的流式计算模型。Spark Streaming接收实时数据源的数据,切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。本质上,这是一种micro-batch(微批处理)的方....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache sparkstructured相关内容
apache spark您可能感兴趣
- apache spark安装
- apache spark日志
- apache spark分析
- apache spark应用
- apache spark OSS
- apache spark机制
- apache spark缓存
- apache spark rdd
- apache spark湖仓
- apache spark lakehouse
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark操作
- apache spark技术
- apache spark yarn
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注