
HADOOP MapReduce 处理 Spark 抽取的 Hive 数据【解决方案一】
开端:今天咱先说问题,经过几天测试题的练习,我们有从某题库中找到了新题型,并且成功把我们干趴下,昨天今天就干了一件事,站起来。沙问题?java mapeduce 清洗 hive 中的数据 ,清晰之后将driver代码 进行截图提交。坑号1: spark之前抽取的数据是.parquet格式的, 对 mapreduce 不太友好,我决定从新抽取, 还是用spark技术,换一种文件格式坑号2....
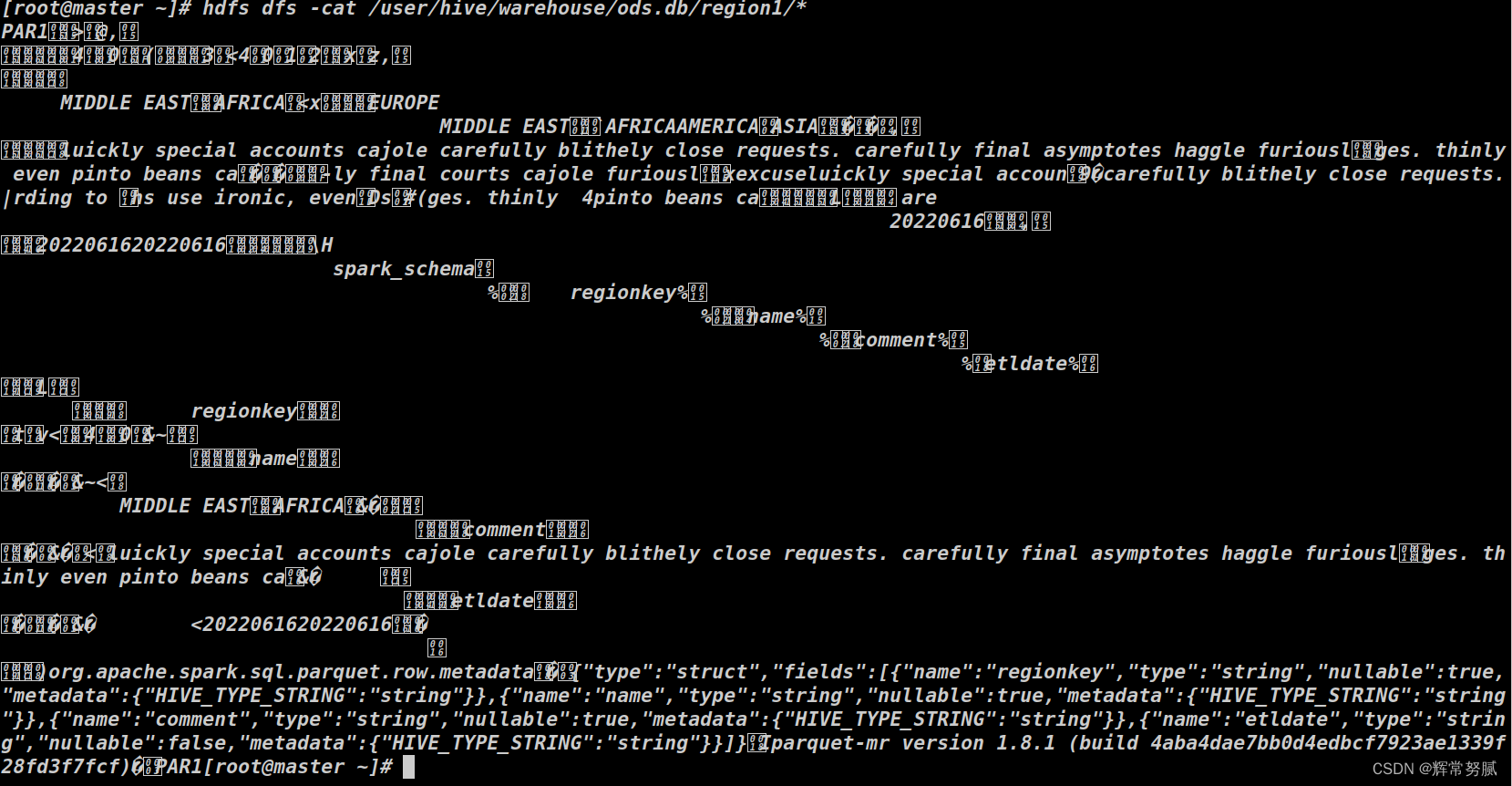
使用Spark 编码 写入 hive 的过程中 hive字段乱码 [解决方案]
由于元数据中的表结构中包含中文,我在抽取到spark过程中已经解决了一次乱码问题,具体显示为问题????,解决方法是在mysql连接上加参数spark 字段乱码 def readMysql(sparkSession: SparkSession,table: String): DataFrame = { val frame: DataFrame = sparkSession ...
大佬,请教下,flink写数据后用spark读数据,这个时区问题有好的解决方案不
大佬,请教下,flink写数据后用spark读数据,这个时区问题有好的解决方案不
一站式Flink&Spark平台解决方案——StreamX
什么是StreamXStreamX 是Flink & Spark极速开发脚手架,流批一体一站式大数据平台。自2021年3月开源以来,贡献者已累计发展到10多位。随着Flink&Spark生态的不断完善,越来越多的企业选择这两款组件,或者其中之一作为离线&实时的大数据开发工具,但是在使用他们进行大数据的开发中我们会遇到一些问题,比如:任务运行监控怎么处理?使用Cluster....

MaxCompute Spark中Driver Memory的原因及解决方案是什么?
MaxCompute Spark中Driver Memory的原因及解决方案是什么?
MaxCompute Spark中Executor 内存不足的原因及解决方案是什么?
MaxCompute Spark中Executor 内存不足的原因及解决方案是什么?
Spark安装完毕遇到中Hadoop HDFS的写入权限问题的解决方案是什么?
Spark安装完毕遇到中Hadoop HDFS的写入权限问题的解决方案是什么?
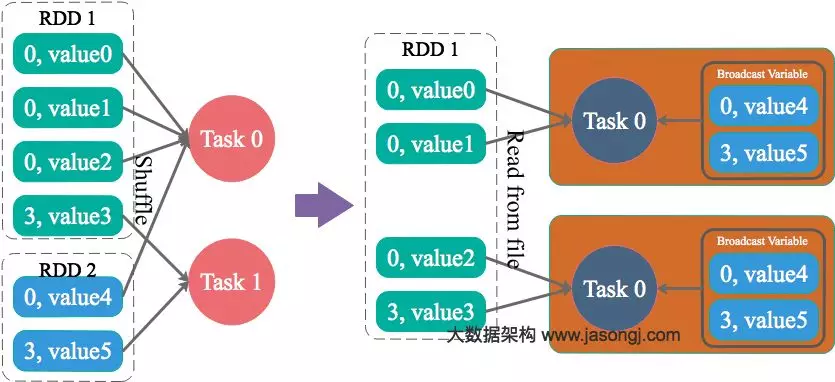
Spark 数据倾斜及其解决方案
作者简介: 郑志彬,毕业于华南理工大学计算机科学与技术(双语班)。先后从事过电子商务、开放平台、移动浏览器、推荐广告和大数据、人工智能等相关开发和架构。目前在vivo智能平台中心从事 AI中台建设以及广告推荐业务。擅长各种业务形态的业务架构、平台化以及各种业务解决方案。 原文链接 转载自公众号:vivo互联网技术 一、什么是数据倾斜 对 Spark/Hadoop 这样的分布式大数据系统来讲,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark技术
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark任务
- apache spark调度
- apache spark yarn
- apache spark作业
- apache spark Hive
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark应用
- apache spark实战
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注