
MapReduce之数据倾斜问题
MapReduce是分为Map阶段和Reduce阶段,其实提高执行效率就是提高这两个阶段的执行效率默认情况下Map阶段中Map任务的个数是和数据的InputSplit相关的,InputSplit的个数一般是和Block块是有关联的,所以可以认为Map任务的个数和数据的block块个数有关系,针对Map任务的个数我们一般 是不需要干预的。如果遇到海量小文件,可以考虑把小文件合并成大文件。使用had....
MapReduce中数据倾斜的产生和解决办法详解
说明:关于数据倾斜的产生原因我将结合 map 和 reduce 阶段中的 shuffle 来讲解,若是对 shuffle 有所忘记需要温故的请到 MapReduce:详解Shuffle(copy,sort,merge)过程 进行相关了解。另本人能力有限,仅根据自己所了解的知识回答,若有误处或不足之处望不吝指出。一、什么是数据倾斜以及数据倾斜是怎么产生的? 简单来说数据倾....
【Hadoop】(五)MapReduce 如何解决数据倾斜问题
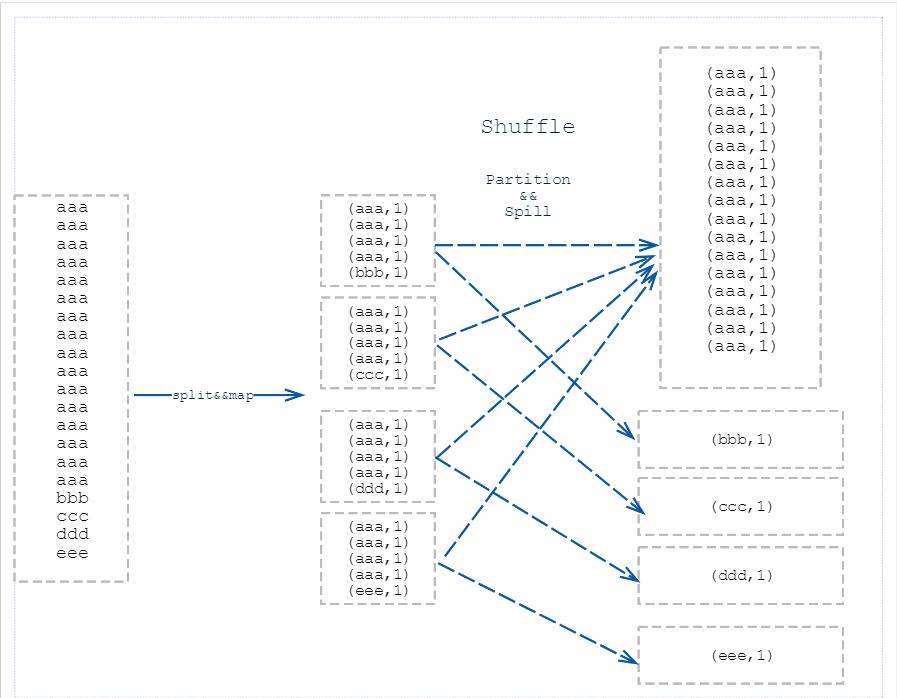
文章目录一、什么是数据倾斜以及数据倾斜是怎么产生的?二、为什么说数据倾斜与业务逻辑和数据量有关?三、如何处理数据倾斜问题呢?四、总结一、什么是数据倾斜以及数据倾斜是怎么产生的?简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少的局面。举个 word count 的入门例子,它的map 阶段就是形成 (“aaa”,1)的形式,然后在reduce 阶段进行 valu....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开源大数据平台 E-MapReduce数据倾斜相关内容
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce产品
- 开源大数据平台 E-MapReduce参数
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce notebook
- 开源大数据平台 E-MapReduce dataset
- 开源大数据平台 E-MapReduce工作空间
- 开源大数据平台 E-MapReduce s3
- 开源大数据平台 E-MapReduce oss
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce文件
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce模式
- 开源大数据平台 E-MapReduce map
- 开源大数据平台 E-MapReduce版本
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
+关注