
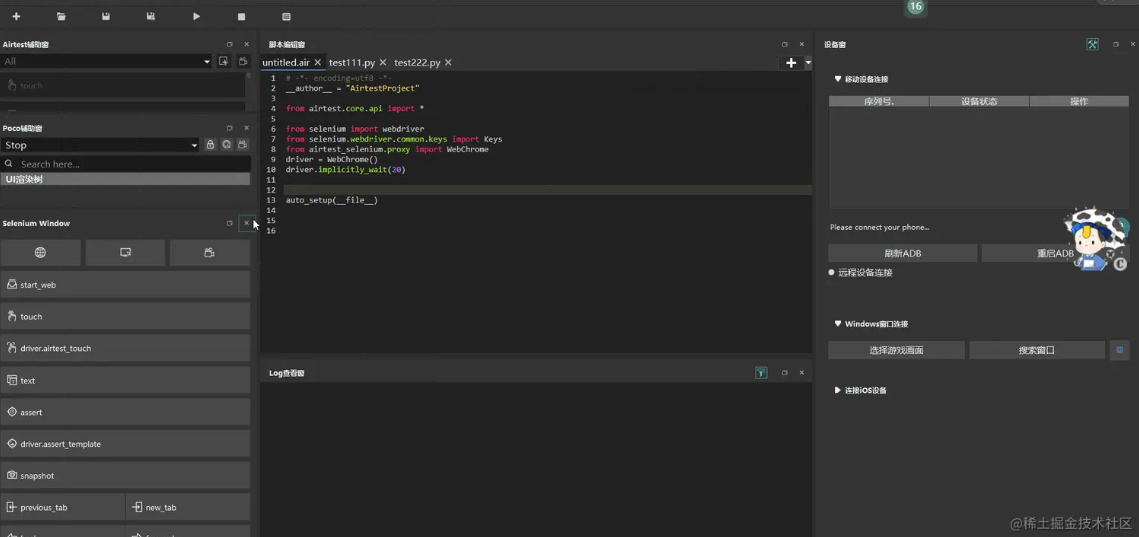
Airtest-Selenium实操小课①:爬取新榜数据
版权声明:允许转载,但转载必须保留原链接;请勿用作商业或者非法用途 1. 前言 最近看到群里很多小伙伴都在用Airtest-Selenium做一些web自动化的尝试,正好趁此机会,我们也出几个关于web自动化的实操小课,仅供大家参考~ 今天跟大家分享的是一个非常简单的爬取网页信息的小练习,在百度找到新榜网页,搜索关键词“自动化”,爬取前5名的公众号名称。 ...

实战练习:用airtest-selenium脚本爬取百度热搜标题
此文章来源于项目官方公众号:“AirtestProject” 版权声明:允许转载,但转载必须保留原链接;请勿用作商业或者非法用途 1. 前言 很多同学,使用AirtestIDE都是做移动端的测试,其实它还有个隐藏功能,就是做web自动化测试。 搞网页测试,使用AirtestIDE的好处是,能借助selenium的辅助窗,帮助我们快捷地生产we...
scrapy_selenium爬取Ajax、JSON、XML网页:豆瓣电影
导语 在网络爬虫的开发过程中,我们经常会遇到一些动态加载的网页,它们的数据不是直接嵌入在HTML中,而是通过Ajax、JSON、XML等方式异步获取的。这些网页对于传统的scrapy爬虫来说,是很难直接解析的。那么,我们该如何使用scrapy_selenium来爬取这些数据格式的网页呢?本文将为你介绍scrapy_selenium的基本原理和使用方法,并给出一个实际的案例。 概述 scra...

如何使用Selenium Python爬取动态表格中的多语言和编码格式
正文 Selenium是一个用于自动化Web浏览器的工具,它可以模拟用户的操作,如点击、输入、滚动等。Selenium也可以用于爬取网页中的数据,特别是对于那些动态生成的内容,如表格、图表、下拉菜单等。本文将介绍如何使用Selenium Python爬取一个动态表格中的多语言和编码格式的数据,并将其保存为CSV文件。 特点 S...

如何使用Selenium Python爬取动态表格中的复杂元素和交互操作
正文Selenium是一个自动化测试工具,可以模拟浏览器的行为,如打开网页,点击链接,输入文本等。Selenium也可以用于爬取网页中的数据,特别是那些动态生成的数据,如表格,图表,下拉菜单等。本文将介绍如何使用Selenium Python爬取动态表格中的复杂元素和交互操作。特点Selenium可以处理JavaScript生成的动态内容,而传统的爬虫工具如requests或BeautifulS....

如何使用Selenium Python爬取多个分页的动态表格并进行数据整合和分析
导语 在网络爬虫的领域中,动态表格是一种常见的数据展示形式,它可以显示大量的结构化数据,并提供分页、排序、筛选等功能。动态表格的数据通常是通过JavaScript或Ajax动态加载的,这给爬虫带来了一定的挑战。本文将介绍如何使用Selenium Python这一强大的自动化测试工具来爬取多个分页的动态表格,并进行数据整合和分析。 正文 Selenium Python简介 Selenium...

Selenium+代理爬取需要模拟用户交互的网站
在日常爬虫采集网站的过程中,部分数据价值较高的网站,会限制访客的访问行为。这种时候建议通过登录的方式,获取目标网站的cookie,然后再使用cookie配合代理IP进行数据采集分析。今天我们就介绍下如何使用Selenium库来爬取网页数据,特别是那些需要模拟用户交互的动态网页。Selenium是一个自动化测试工具,...
使用 Scrapy + Selenium 爬取动态渲染的页面
背景在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动....
【Python】手把手教你用selenium爬取某东月饼数据
前言工欲善其事,必先利其器 本期我们使用Pycharm+python3.7.9+selenium实现对京东月饼等信息的爬取,爬取信息不限于月饼,可以是京东上所有在销商品selenium(WEB自动化测试工具)Selenium 1() 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10...
用selenium爬取中国开源搜索界面的翻页,只能打开一个页面,怎么全都打开??报错
运行后报错stale element reference: element is not attached to the page document 只能打开第一页,之后页码不会打开。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Selenium您可能感兴趣
- Selenium playwright
- Selenium数据
- Selenium chromedriver
- Selenium表单
- Selenium库
- Selenium模拟登录
- Selenium python
- Selenium采集
- Selenium数据抓取
- Selenium web
- Selenium自动化
- Selenium测试
- Selenium自动化测试
- Selenium java
- Selenium教程
- Selenium浏览器
- Selenium webdriver
- Selenium框架
- Selenium元素
- Selenium爬虫
- Selenium定位
- Selenium方法
- Selenium chrome
- Selenium报错
- Selenium页面
- Selenium详细教程
- Selenium测试框架
- Selenium元素定位
- Selenium软件测试
- Selenium环境搭建
开发与运维
集结各类场景实战经验,助你开发运维畅行无忧
+关注