
大数据-62 Kafka 高级特性 主题 kafka-topics相关操作参数 KafkaAdminClient 偏移量管理
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(正在更新…) ...

步入未来科技前沿:全方位解读Unity在VR/AR开发中的应用技巧,带你轻松打造震撼人心的沉浸式虚拟现实与增强现实体验——附详细示例代码与实战指南
VR/AR开发新纪元:使用Unity创建沉浸式虚拟体验 虚拟现实(Virtual Reality,简称VR)和增强现实(Augmented Reality,简称AR)技术正在以前所未有的方式改变着人们的生活。从教育到娱乐,从医疗到工业,VR/AR的应用范围越来越广泛。Un...
Kafka不重复消费的终极秘籍!解锁幂等性、偏移量、去重神器,让你的数据流稳如老狗,告别数据混乱时代!
Kafka,作为分布式流处理平台的佼佼者,以其高吞吐量和低延迟的特性在大数据处理领域占据了一席之地。然而,在使用Kafka时,如何确保不消费重复数据是许多开发者关心的问题。本文将详细介绍Kafka如何避免重复消费数据,并提供相应的示例代码和策略。 Kafka 重复消费的原因首先,我们需要了解Kafka中重复消费数...
面试题Kafka问题之查看偏移量为23的消息如何解决
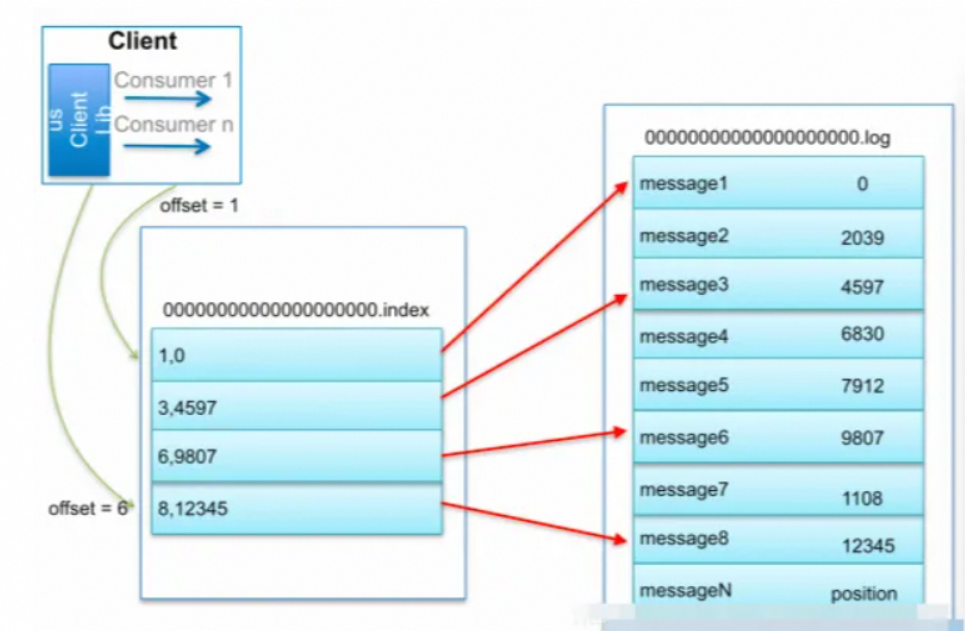
问题一:如何使用Kafka查看偏移量为23的消息? 如何使用Kafka查看偏移量为23的消息? 参考回答: 通过查询跳跃表ConcurrentSkipListMap,定位到在00000000000000000000.index ,通过二分法在偏移量索引文件中找到不大于 23 的最大索引项,即offset 20 那栏,然后从日志分段文件中的物理位置为32...
Kafka日志处理:深入了解偏移量查找与切分文件
Hello, 大家好!我是你们的技术小伙伴小米,今天要和大家分享一些关于Kafka日志处理的深入知识。我们将讨论如何查看偏移量为23的消息,以及Kafka日志分段的切分策略。准备好了吗?让我们开始吧! 如何查看偏移量为23的消息? 在Kafka中,偏移量是消息的唯一标识,了解如何查找特定偏移量的消息是非常重要的。下面,我们将一步步详细介绍如何通过查询跳跃表ConcurrentSk...

Kafka 新的消费组默认的偏移量设置和消费行为
默认消费行为 当一个新的消费者组第一次订阅一个主题时,它会根据 auto-offset-reset 的配置来决定从哪里开始消费消息。auto-offset-reset 有三个选项: earliest:如果消费者组没有已提交的偏移量(即新的消费者组),则从主题的最早消息开始消费。 latest:如果消费者组没有已提交的偏移量,则从最新的消息开始消费(即从消费者...
实时计算 Flink版操作报错合集之无法将消费到的偏移量提交到Kafka如何解决
问题一:Flink CDC比如检查到挂了,我重启了,这个会重新连不,我刚刚重启了还是一样的错? Flink CDC比如检查到挂了,我重启了,这个会重新连不,我刚刚重启了还是一样的错? 参考回答: ...
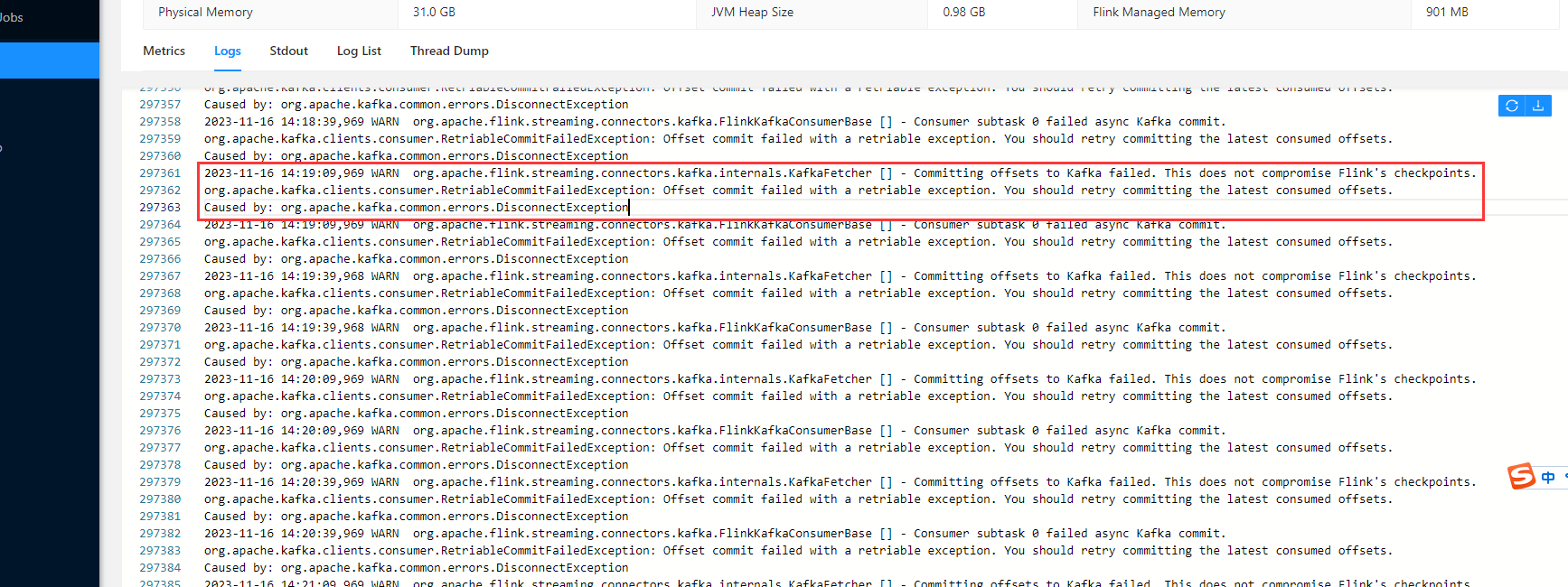
flink作业数据来源是kafka ,配置偏移量策略是earlest,有什么办法吗?
flink作业数据来源是kafka ,配置偏移量策略是earlest,而且作业使用了rockdb状态后端,状态的生命周期是1个月, 目前kafka中的数据只能存3天,但是作业需要停7天 ,想重启作业时尽可能的多消费数据 且 停止作业时的保存点中的状态不丢数 ,有什么办法吗? 是直接就保存保存点 然后停止作业,7天后直接从保存点启动作业吗?
Kafka【付诸实践 02】消费者和消费者群组+创建消费者实例+提交偏移量(自动、手动)+监听分区再平衡+独立的消费者+消费者其他属性说明(实例源码粘贴可用)【一篇学会使用Kafka消费者】
1.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响。Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经常会做一些高延迟的操作,比如把数据写到数据库或HDFS ,或者进行耗时的计算,在这些情况下,单个消费者无法跟上数据生成的速度。此时可以增加更多的消费者,让它们分担负载,分别处理部分分区的消息,这就.....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云消息队列 Kafka 版您可能感兴趣
- 云消息队列 Kafka 版hub
- 云消息队列 Kafka 版event
- 云消息队列 Kafka 版并发
- 云消息队列 Kafka 版spring
- 云消息队列 Kafka 版springcloud
- 云消息队列 Kafka 版stream
- 云消息队列 Kafka 版报错
- 云消息队列 Kafka 版接收
- 云消息队列 Kafka 版镜像
- 云消息队列 Kafka 版clickhouse
- 云消息队列 Kafka 版flink
- 云消息队列 Kafka 版数据
- 云消息队列 Kafka 版cdc
- 云消息队列 Kafka 版分区
- 云消息队列 Kafka 版集群
- 云消息队列 Kafka 版topic
- 云消息队列 Kafka 版配置
- 云消息队列 Kafka 版同步
- 云消息队列 Kafka 版消息队列
- 云消息队列 Kafka 版消费
- 云消息队列 Kafka 版mysql
- 云消息队列 Kafka 版apache
- 云消息队列 Kafka 版安装
- 云消息队列 Kafka 版消费者
- 云消息队列 Kafka 版消息
- 云消息队列 Kafka 版日志
- 云消息队列 Kafka 版sql
- 云消息队列 Kafka 版原理
- 云消息队列 Kafka 版生产者
- 云消息队列 Kafka 版连接

云消息队列
涵盖 RocketMQ、Kafka、RabbitMQ、MQTT、轻量消息队列(原MNS) 的消息队列产品体系,全系产品 Serverless 化。RocketMQ 一站式学习:https://rocketmq.io/
+关注