
数据湖技术:Hadoop与Spark在大数据处理中的协同作用
数据湖技术:Hadoop与Spark在大数据处理中的协同作用 在大数据时代,数据湖技术以其灵活性和成本效益成为了企业存储和分析大规模异构数据的首选。Hadoop和Spark作为数据湖技术中的两个核心组件,它们在大数据处理中的协同作用至关重要。本文将探讨Hadoop与Spark的最佳实践,以及如何在实际应用中发挥它们的协同效应。 Hadoop...
数据湖技术:Hadoop与Spark在大数据处理中的协同作用
随着大数据技术的不断发展,数据湖作为一种集中式存储和处理海量数据的架构,越来越受到企业的青睐。Hadoop和Spark作为数据湖技术的两大核心组件,在大数据处理中发挥着不可替代的作用。本文将通过最佳实践的形式,详细探讨Hadoop与Spark在大数据处理中的协同作用,并提供具体的示例代码。 Hadoop,作为一个...
Hudi数据湖技术引领大数据新风口(四)核心概念
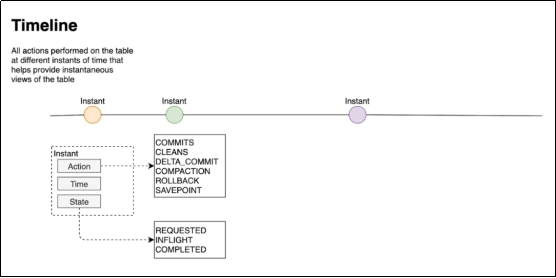
第3章 核心概念3.1 基本概念3.1.1 时间轴(TimeLine)Hudi的核心是维护表上在不同的即时时间(instants)\执行的所有操作的时间轴(timeline)\,这有助于提供表的即时视图,同时还有效地支持按到达顺序检索数据。一个instant由以下三个部分组成:*1)Instant action:在表上执行的操作类型\Ø COMMITS:一次commit表示将一批数据原子性地写入....
Hudi数据湖技术引领大数据新风口(三)解决spark模块依赖冲突
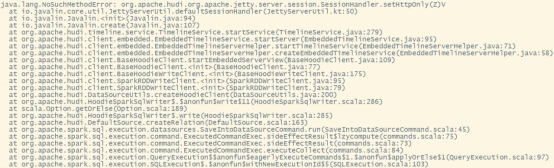
解决spark模块依赖冲突修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。1)修改hudi-spark-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty:vim /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml在382行的位置,修改如....
Hudi数据湖技术引领大数据新风口(二)编译安装
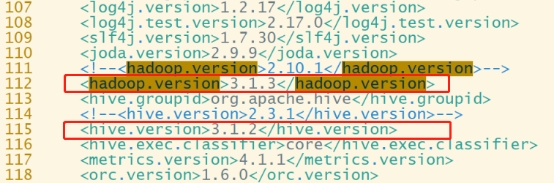
第2章 编译安装2.1 编译环境准备本教程的相关组件版本如下:Hadoop3.1.3Hive3.1.2Flink1.13.6,scala-2.12Spark3.2.2,scala-2.12(1)安装Maven(1)上传apache-maven-3.6.1-bin.tar.gz到/opt/software目录,并解压更名tar -zxvf apache-maven-3.6.1-bin.tar.gz....
Hudi:数据湖技术引领大数据新风口
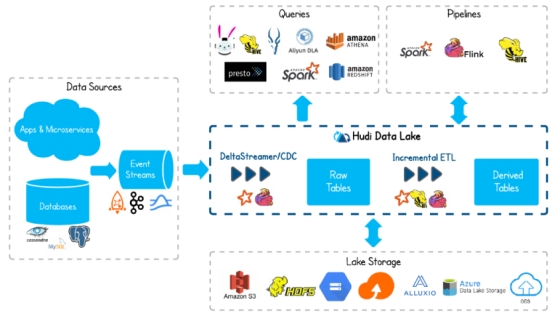
Hudi:数据湖技术引领大数据新风口1.1 Hudi简介Apache Hudi(Hadoop Upserts Delete and Incremental)是下一代流数据湖平台。Apache Hudi将核心仓库和数据库功能直接引入数据湖。Hudi提供了表、事务、高效的upserts/delete、高级索引、流摄取服务、数据集群/压缩优化和并发,同时保持数据的开源文件格式。Apache Hudi不....
耳朵经济快速增长背后,喜马拉雅数据价值如何释放 | 创新场景
作者|张申宇编辑|盖虹达作为“耳朵经济”发展的领军者,喜马拉雅坐拥数以亿计的月活流量,却没有停止创新和思考,如何让这个庞大的用户群体有更好的体验,并在庞大的数据基础上进一步实现商业创新。数据显示,2021年时中国在线音频市场的复合年增长率已经超过了60%,预计2026年市场规模将增长至1204亿元人民币。喜马拉雅看到了音频市场在终端应用方面(如天猫精灵和汽车内嵌系统)有着市场巨大的潜力。向来注重....

数据湖见证从 BI 到 BI+AI的关键技术演进
1. 前言 数据湖作为大数据平台的底层支撑架构,从存储、元数据、计算框架维度提供了良好的支撑。在BI时代,支撑好海量数据存储的稳定性、扩展性、成本是关键技术竞争力;随着AI的兴起,特别是 LLM 大模型计算的热潮,对数据湖也带来在性能、安全性上更多的需求,阿里云数据湖在该领域已有多年探索,希望能够通过本次分享给业界在 BI+AI 的基础设施建设上带来更多思路。 ...

《基于数据湖的精准广告投放系统技术解密》电子版地址
《基于数据湖的精准广告投放系统技术解密》基于数据湖的精准广告投放系统技术解密 电子版下载地址: https://developer.aliyun.com/ebook/4149 电子书: </div>

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
