
搭建Hadoop环境
Hadoop是由Apache基金会使用Java语言开发的分布式开源软件框架,本文介绍如何在Linux操作系统的ECS实例上快速搭建Hadoop分布式和伪分布式环境。
【分布式计算框架】Hadoop伪分布式安装
Hadoop伪分布式安装 一、实验目的 安装Linux虚拟机(至少五台) hadoop伪分布式安装 二、实验环境 centos 6.5 三、实验内容 基本任务1:安装Linux虚拟机(至少5台) (1)BIOS设置(开启虚拟化) ...
大数据开发之Hadoop 伪分布式安装(4)【完结】
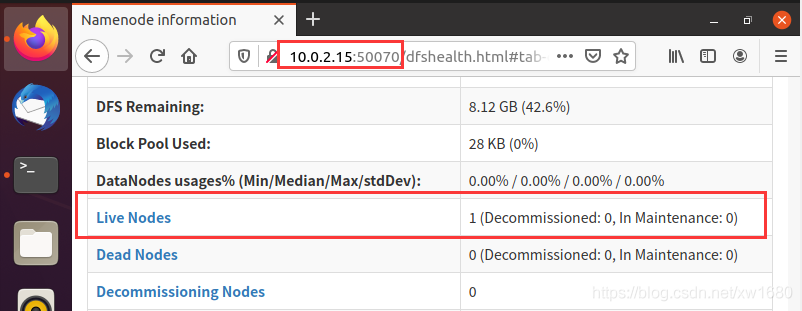
大数据开发之Hadoop 伪分布式安装(4)查看 Hadoop 的基本信息查看 HDFS Web 界面HDFS Web 界面可以检查当前 HDFS 与 DataNode 的运行情况,打开步骤如下。打开浏览器 Firefox,在浏览器的地址栏中输入:10.0.2.15:50070,向下滑动页面,可以看到活动节点,如下图所示:说明:10.0.2.15 为笔者虚拟机中的 IP 地址,读者应根据实际情况....
大数据开发之Hadoop 伪分布式安装(3)
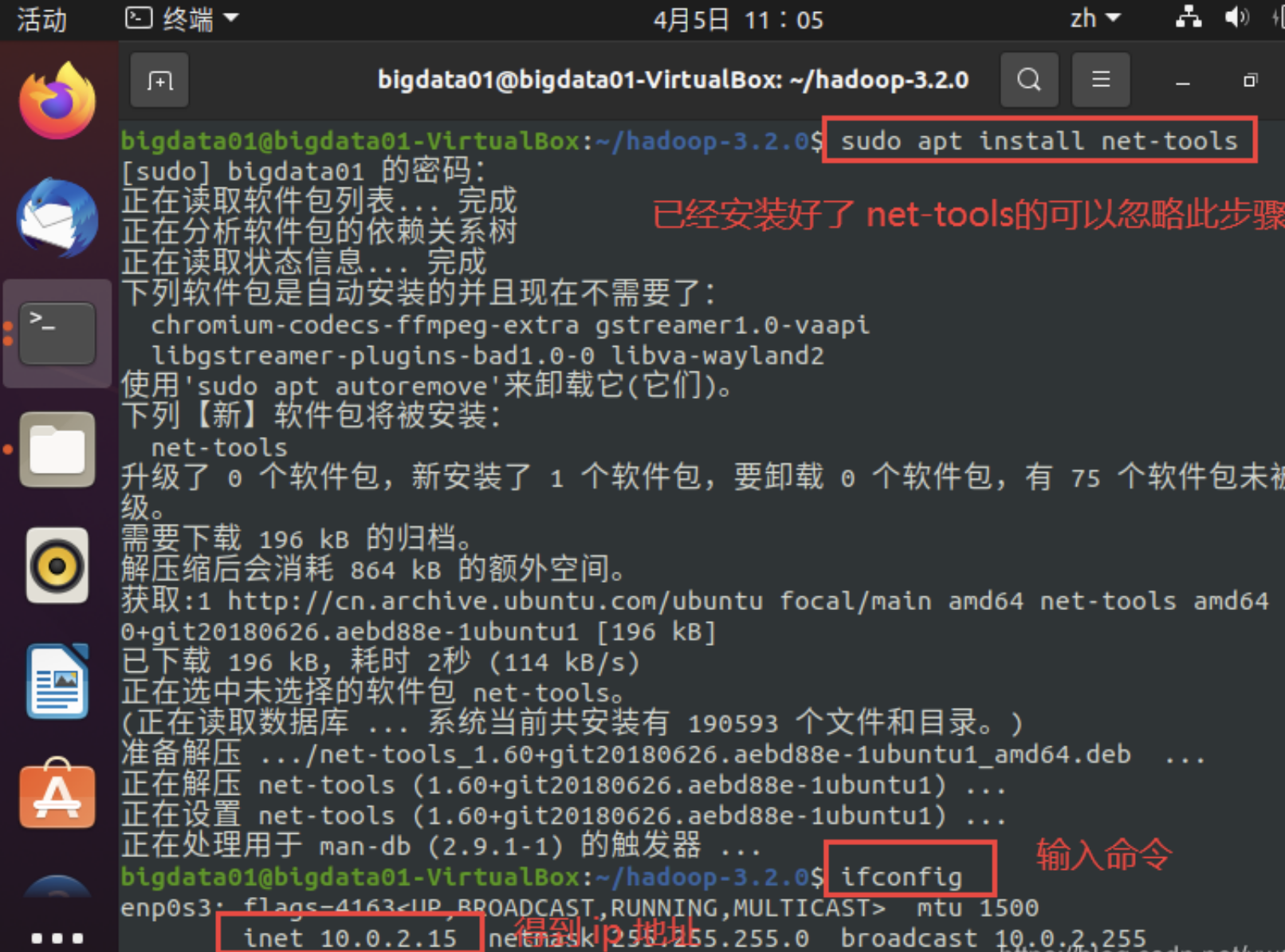
大数据开发之Hadoop 伪分布式安装(3)我们接着上一节,来配置Hadoop.Hadoop 环境配置1、配置 IP 和主机名下面分别通过命令查看本机的 IP 地址和主机名,并将 IP 地址和主机名写进 /etc/hosts 配置文件中,步骤如下:(1) 查看本机的 IP 地址,命令如下:sudo apt install net-tools ifconfig或者直接使用ip addr执行结果如下....
hadoop伪分布式安装记录
引语: 最近想接触一些大数据相关的技术,所以有了这篇文章,其实就是记录一下自己学习hadoop的过程,如果文章中有啥写的不对的地方,还望指正(有java开发经验,但是是大数据小白一只,各位大神轻喷.)我先是在网上搜索了一波大数据应该要学些什么技术,基本上不约而同的都是指向了hadoop. 摘自维基百科:Ap...

Hadoop伪分布式环境搭建之Linux操作系统安装
Hadoop伪分布式环境搭建之Linux操作系统安装本篇文章是接上一篇《超详细hadoop虚拟机安装教程(附图文步骤)》,上一篇有人问怎么没写hadoop安装。在文章开头就已经说明了,hadoop安装会在后面写到,因为整个系列的文章涉及到每一步的截图,导致文章整体很长。会分别先对虚拟机的安装、Linux系统安装进行介绍,然后才会写到hadoop安装,关于hadoop版本我使用的是大快搜索三节点发....
hadoop伪分布式2.4.1安装
一、准备: 1、修改主机名: vi /etc/sysconfig/network内容如下: NETWORKING=yes HOSTNAME=myHadoop 2、修改主机名和IP的映射关系,即hosts文件: vi /etc/hosts 192.168.127.150 myHadoop 3、关闭防火墙: 3.1、查看防火墙状态 ...
Hadoop伪分布式安装Spark
应用场景 搭建部署了hadoop环境后,使用MapReduce来进行计算,速度非常慢,因为MapReduce只是分布式批量计算,用于跑批的场景,并不追求速率,因为它需要频繁读写HDFS,并不能实时反馈结果,这种跑批的场景用的还是比较少的。一般客户最想看到的是输入后立马有结果反馈。那此时我们就需要在Hadoop伪分布式集群上部署Spark环境了!因为Spark是内存计算,它把计算的中间结果...
Hadoop伪分布式安装
卸载JDK: 1 2 3 4 5 [root@localhost mzsx]# rpm -qa | grep java java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.x86_64 tzdata-java-2012c-1.el6.noarch [root@localhost mzsx]# rpm -e --nodeps tzdata-ja...
Hadoop伪分布式安装
前言: hadoop:存储和处理平台 hdfs:集群,NN,SNN,DN //SNN:将HDFS的日志和映像进行合并操作 mapreduce: 集群,有中心node,jobTracker/Task tracker, jT:集群资源管理 TT:任务,map,reduce hadoop 2.0 YARN:集群资源管理,分割 MapReduce:数据处理 RN,N...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop您可能感兴趣
- hadoop开发环境
- hadoop hbase
- hadoop集群
- hadoop数据处理
- hadoop数据分析
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop技术
- hadoop大数据
- hadoop hdfs
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop分布式
- hadoop数据
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作
