
《从机器学习到深度学习》笔记(5)集成学习之随机森林
集成学习模型与其他有监督模型的出发点大相径庭,之前的模型都是在给定的训练集上通过构建越来越强大的算法进行数据拟合。而集成学习着重于在训练集上做文章:将训练集划分为各种子集或权重变换后用较弱的基模型拟合,然后综合若干个基模型的预测作为最终整体结果。在Scikit-Learn中实现了两种类型的集成学习算法,一种是Bagging methods,另一种是Boosting methods。 随机森林(R....
《从机器学习到深度学习》笔记(4)划分数据集
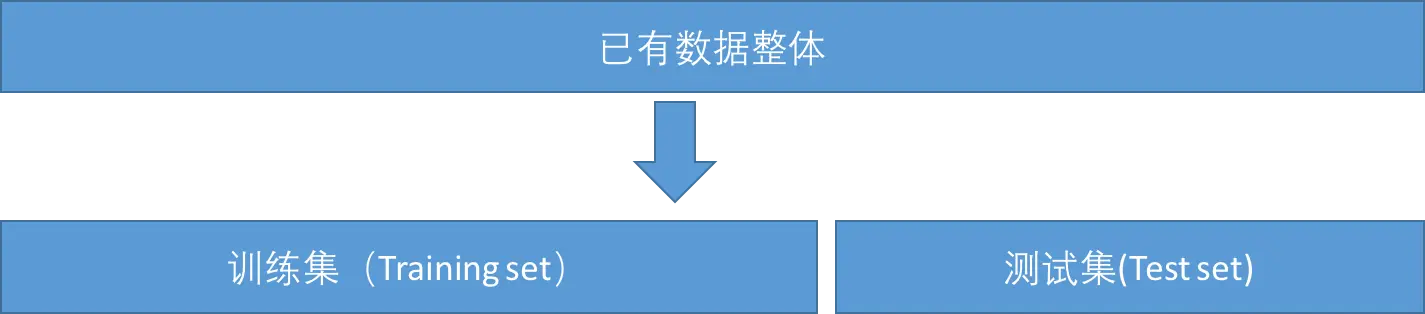
任何机器学习算法都是基于对已有数据集或环境的信息挖掘,要求将从现有数据学习得到的模型能够适配于未来的新数据。 1. 训练集(Training set)与测试集(Test set) 很自然的,在评估模型能力的时候需要采用与模型训练时不同的数据集,因此在训练模型之前需要将已有数据集划分成如图1-13的两部分。 图1-13 训练集与测试集 顾名思义,图中的训练集用于在训练模型时使用,测试集用于评估模.....
《从机器学习到深度学习》笔记(3)强化学习
强化学习是对英文Reinforced Learning的中文翻译,它的另一个中文名称是“增强学习”。相对于有监督学习和无监督学习,强化学习是一个相对独特的分支;前两者偏向于对数据的静态分析,后者倾向于在动态环境中寻找合理的行为决策。 强化学习的行为主体是一个在某种环境中独立运行的Agent(可以理解为“机器人”), 其可以通过训练获得在该环境中的最佳行为模式。强化学习被看成是最接近人工智能的一个....
《从机器学习到深度学习》笔记(2)无监督学习
有监督学习用于解决分类问题的前提是必须有一个带标签数据的样本集,但获得数据标签的代价往往是非常昂贵的。同时,这些标签通常都是人工标注,标注错误的情况也时有发生。这样就促使了无监督学习策略的发展,简单的说它就是:对无标签数据进行推理的机器学习方法。1. 场景由于无监督学习的前提是不需要前期的人类判断,所以它一般是作为某项学习任务的前置步骤,用于规约数据;在无监督学习之后,需要加入人类知识以使成果有....
《从机器学习到深度学习》笔记(1)有监督学习
有监督学习(Supervised Learning)是指这样的一种场景: 有一组数量较多的历史样本集,其中每个样本有一组特征(features)和一个或几个标示其自身的类型或数值的标签(label);对历史样本学习得到模型后,可以用新样本的特征预测其对应的标签。 场景 在有监督学习中可以将每条数据看成是一条由特征到标签的映射,训练的目的是找出映射的规律。根据标签的类型可以将有监督学习再分为两个子....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
机器学习平台 PAI笔记相关内容
- 机器学习平台 PAI精炼笔记
- 机器学习平台 PAI吴恩达笔记
- 笔记机器学习平台 PAI
- 机器学习平台 PAI笔记支持向量机
- 机器学习平台 PAI笔记神经网络
- 机器学习平台 PAI笔记单变量
- 机器学习平台 PAI测试笔记
- 机器学习平台 PAI课程学习笔记gnns
- 机器学习平台 PAI冬季课程学习笔记
- 机器学习平台 PAI冬季课程学习笔记networks
- 机器学习平台 PAI冬季课程学习笔记knowledge
- cs224w机器学习平台 PAI冬季课程学习笔记graph
- 机器学习平台 PAI冬季笔记embeddings
- 机器学习平台 PAI笔记model
- 机器学习平台 PAI笔记learning
- 机器学习平台 PAI自学笔记
- 机器学习平台 PAI笔记逻辑回归
- machine learning笔记机器学习平台 PAI
- andrew ng机器学习平台 PAI课程笔记
- andrew ng机器学习平台 PAI笔记pca
- andrew机器学习平台 PAI笔记learning
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI scikit-learn
- 机器学习平台 PAI python
- 机器学习平台 PAI代码
- 机器学习平台 PAI论文
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI模型
- 机器学习平台 PAI构建
- 机器学习平台 PAIpai
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI分类
- 机器学习平台 PAI平台
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践
- 机器学习平台 PAI决策
- 机器学习平台 PAIai
- 机器学习平台 PAI部署
- 机器学习平台 PAI网络
- 机器学习平台 PAI线性回归