
流计算引擎数据问题之在 Spark Structured Streaming 中水印计算和使用如何解决
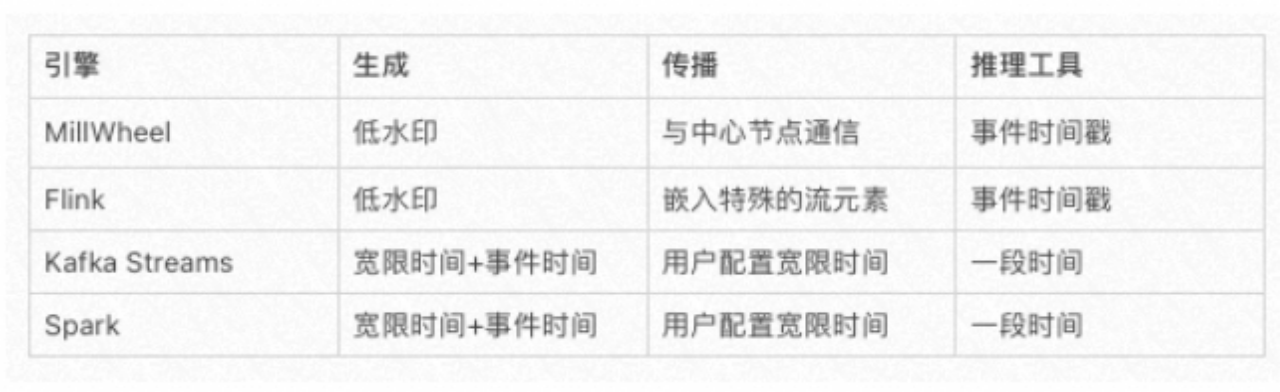
问题一:Apache Kafka Streams 的完整性推理过程是怎样的? Apache Kafka Streams 的完整性推理过程是怎样的? 参考回答: Apache Kafka Streams 的完整性推理过程不使用流中嵌入的特殊元信息或系统级低水印时间戳,而是允许通过在每个算子上配置宽限期来进行细粒度的完整性确定。生产阶段,事件流经算子时,算...
如何在Spark Streaming SQL中使用INSERT INTO语句
StarRocks中INSERT INTO语句的使用方式和MySQL等数据库中INSERT INTO语句的使用方式类似, 但在StarRocks中,所有的数据写入都是一个独立的导入作业 ,所以StarRocks中将INSERT INTO作为一种导入方式介绍。本文为您介绍Insert Into导入的使用场景、相关配置以及导入示例。
如何通过Spark Structured Streaming流式写入Iceberg表
本文为您介绍如何通过Spark Structured Streaming流式写入Iceberg表。
Spark Structured Streaming 和 Kafka 在数据完整性推理上有何不足?
Spark Structured Streaming 和 Kafka Streams 在数据完整性推理上有何不足?
在 Spark Structured Streaming 中,水印是如何计算和使用的?
在 Spark Structured Streaming 中,水印是如何计算和使用的?
大数据Spark Structured Streaming集成 Kafka
1 Kafka 数据消费Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。StructuredStreaming很好的集成Kafka,可以从Kafka拉取消息,然后就可以把流数据看做一个DataFrame, 一张无限增长的大表,在这个大表上做查询,Structured Stre....
大数据Spark Structured Streaming 2
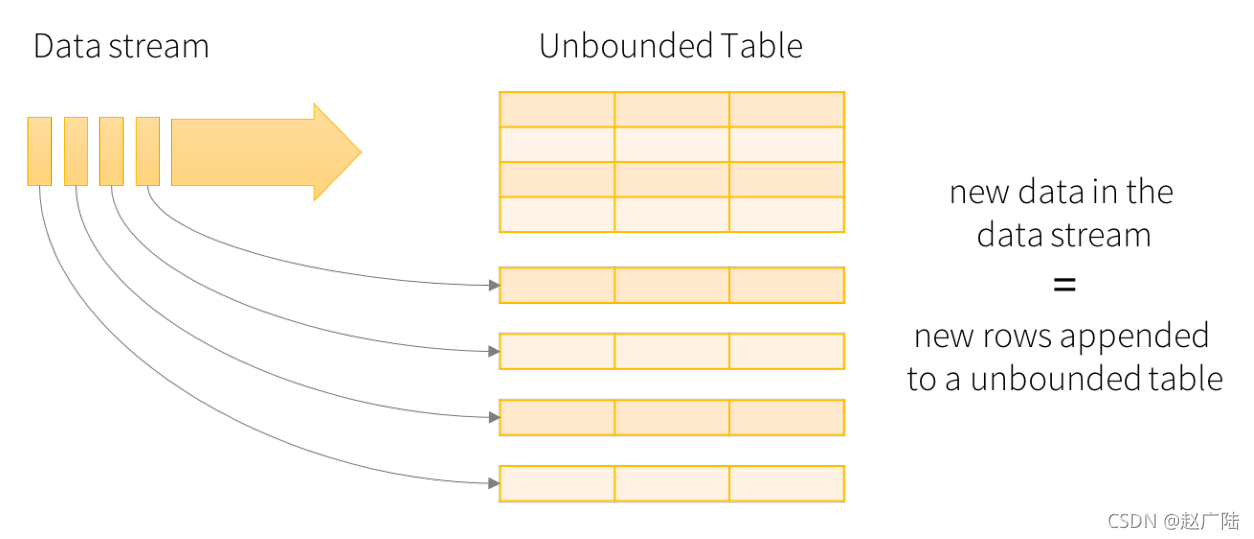
2.3 编程模型Structured Streaming将流式数据当成一个不断增长的table,然后使用和批处理同一套API,都是基于DataSet/DataFrame的。如下图所示,通过将流式数据理解成一张不断增长的表,从而就可以像操作批的静态数据一样来操作流数据了。在这个模型中,主要存在下面几个组成部分:第一部分:Input Table(Unbounded Table),流式数据的抽象表示,....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache sparkstreaming相关内容
- 大数据apache spark streaming
- apache spark Streaming Kafka
- apache spark streaming黑名单
- apache spark集群streaming
- apache spark streaming rdd
- apache spark streaming窗口案例
- apache spark streaming概述
- apache spark streaming案例
- apache spark streaming代码
- apache spark streaming数据流
- apache spark streaming窗口
- apache spark streaming流程
- apache spark Streaming概念
- apache spark streaming计算
- 开发apache spark streaming
- apache spark streaming任务
- apache spark apache spark streaming
- apache spark streaming实战
- apache spark streaming数据处理
- apache spark streaming端到端
- apache spark streaming编程
- apache spark streaming区别
- flink apache spark streaming
- apache spark streaming流数据
- apache spark Streaming容错性
- apache spark streaming数据源
- apache spark streaming操作
- apache spark streaming dstream操作
- apache spark streaming简介
- apache spark streaming学习笔记
apache spark更多streaming相关
- 技术apache spark streaming
- apache spark streaming wordcount
- apache spark streaming checkpoint
- apache spark streaming storm
- apache spark streaming框架
- apache spark summit east streaming
- apache spark streaming binlog
- apache spark streaming实时计算
- emr apache spark streaming
- apache spark streaming应用程序
- apache spark streaming方法
- apache spark streaming小文件
- apache spark streaming作用是什么
- apache spark Streaming原理
- apache spark streaming文件典型
- apache spark入门streaming
- apache spark streaming direct
- apache spark summit eu streaming
- apache spark streaming loghub
- apache spark streaming应用
- apache spark streaming作业运行
- apache spark streaming项目实战笔记
- apache spark streaming服务
- apache spark streaming structured
- apache spark streaming sql pv uv统计
- flink相比传统apache spark streaming区别
- apache spark streaming分析
- apache spark streaming运行
- apache spark streaming优化
- apache spark streaming流处理
apache spark您可能感兴趣
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark系统
- apache spark技术
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark SQL
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark yarn
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注