
Spark Conf自定义参数列表
Serverless Spark支持多个内置特有参数,您可以查阅这些参数的名称、描述及其使用场景,以便灵活配置任务运行环境并优化任务执行。
变量管理
使用变量可以有效降低重复编写相同值的工作量,从而提升配置管理的效率。通过变量的复用,可以在SQL开发、批任务开发及工作流等场景中简化代码的维护和调整,进而提高开发效率。本文将为您详细介绍如何创建变量及其在不同场景下的具体使用方法。
读写HBase
基于HBase官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接HBase。本文为您介绍在EMR Serverless Spark环境中实现HBase的数据读取和写入操作。
通过Job Committer保证Mapreduce/Spark任务数据一致性
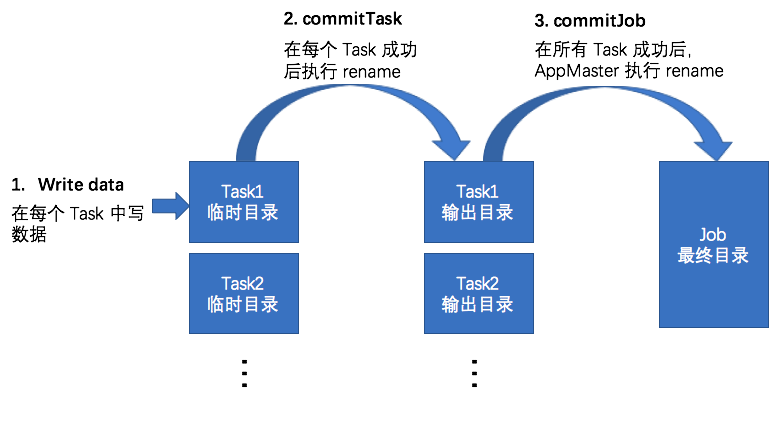
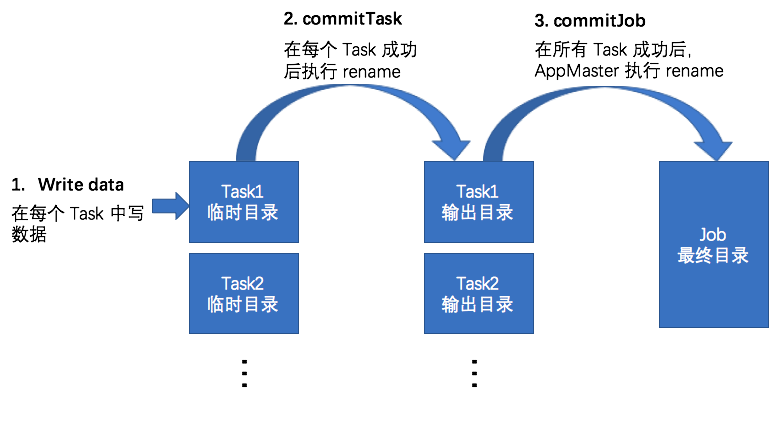
作者:李呈祥,花名司麟,阿里云智能EMR团队高级技术专家,Apache Hive Committer, Apache Flink Committer,目前主要专注于EMR产品中开源计算引擎的优化工作。 并发地向目标存储系统写数据是分布式任务的一个天然特性,通过在节点/进程/线程等级别的并发写数据,充分利用集群的磁盘和网络带宽,实现高容量吞吐。并发写数据的一个主要需要解决的问题就是如何保证数据一.....
通过Job Committer保证Mapreduce/Spark任务数据一致性
并发地向目标存储系统写数据是分布式任务的一个天然特性,通过在节点/进程/线程等级别的并发写数据,充分利用集群的磁盘和网络带宽,实现高容量吞吐。并发写数据的一个主要需要解决的问题就是如何保证数据一致性的问题,具体来说,需要解决下面列出的各个问题: 在分布式任务写数据的过程中,如何保证中间数据对外不可见。 在分布式任务正常完成后,保证所有的结果数据同时对外可见。 在分布式任务失败时,所有结果数据对.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark系统
- apache spark技术
- apache spark大数据
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark yarn
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注