
hadoop&spark安装(下)
上一遍文章中其实最主要的就是JAVA环境变量以及hadoop环境变量的设置,这两个设置好了的话,运行hadoop基本上不会出问题。 在hadoop的基础上安装spark好简单。 安装Spark之前需要先安装Hadoop集群,因为之前已经安装了hadoop,所以我直接在之前的hadoop集群上安装spark。 硬件环境: hddcluster1 10.0.0.197 redhat7 hddclus....
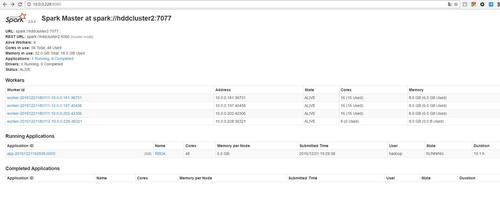
hadoop&spark安装(上)
硬件环境: hddcluster1 10.0.0.197 redhat7 hddcluster2 10.0.0.228 centos7 这台作为master hddcluster3 10.0.0.202 redhat7 hddcluster4 10.0.0.181 centos7 软件环境: 关闭所有防火墙firewall openssh-clients openssh-server ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark系统
- apache spark技术
- apache spark大数据
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark yarn
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注