
如何通过Flink CDC实时订阅AnalyticDB PostgreSQL的全量和增量数据
AnalyticDB for PostgreSQL提供自研的CDC连接器,基于PostgreSQL的逻辑复制功能实现订阅全量和增量数据,可与Flink无缝集成。该连接器能够高效捕获源表的实时变更数据,支持实时数据同步、流式处理等,助力企业快速响应动态数据需求。本文介绍如何通过阿里云实时计算Flink版CDC实时订阅AnalyticDB for PostgreSQL的全量和增量数据。
如何使用Flink处理表格存储数据
本文为您介绍如何使用Flink计算表格存储(Tablestore)的数据,表格存储中的数据表或时序表均可作为实时计算Flink的源表或结果表进行使用。
Flink-04 Flink Java 3分钟上手 FlinkKafkaConsumer消费Kafka数据 进行计算SingleOutputStreamOperatorDataStreamSource
代码仓库 会同步代码到 GitHub https://github.com/turbo-duck/flink-demo pom.xml 修改pom.xml,需要加入 kafka相关的包,和适配器。 ...
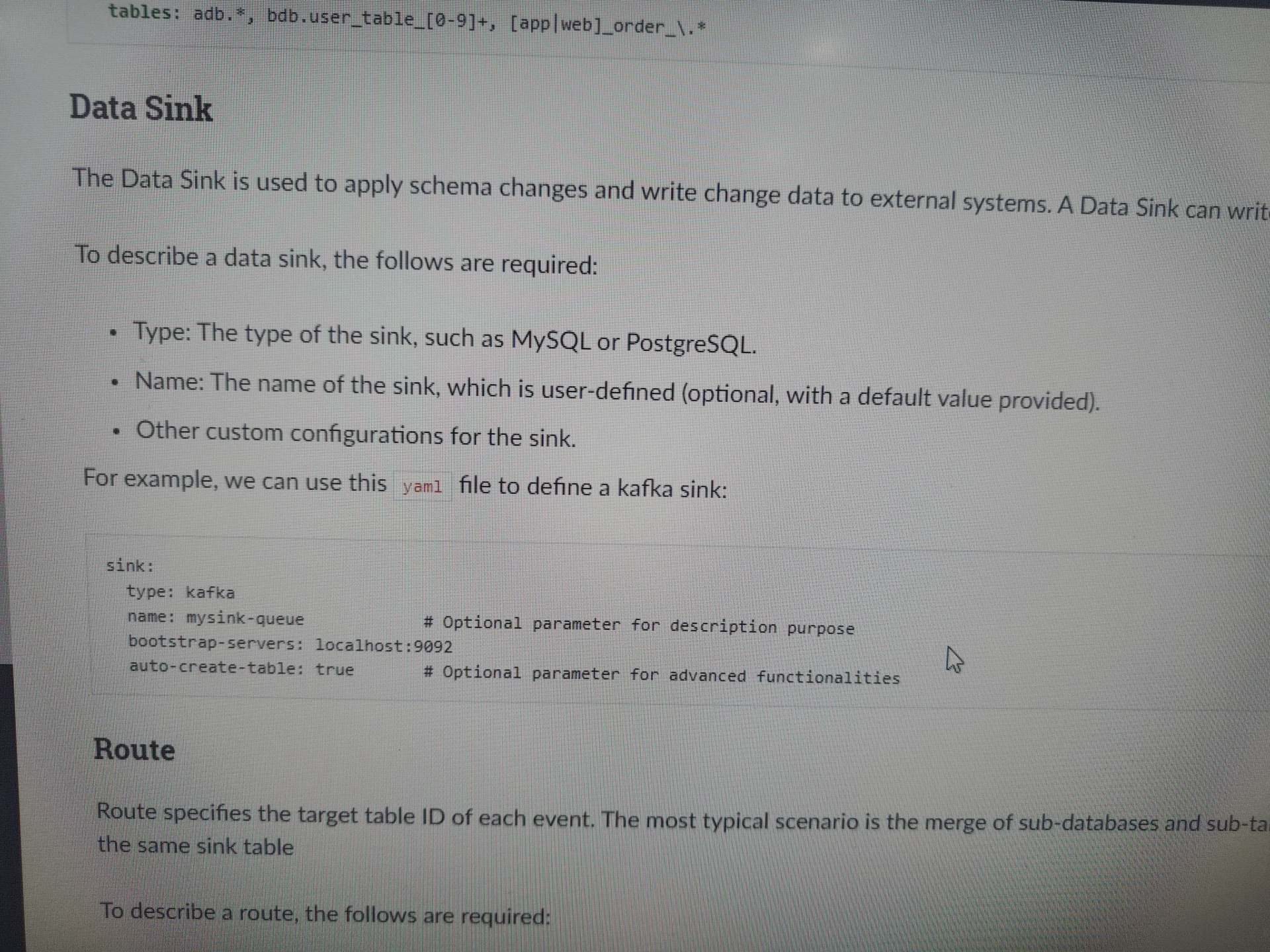
实时计算 Flink版产品使用问题之如何使用Kafka Connector将数据写入到Kafka
问题一:Flink CDC里之前用mysql数据库join比较慢,这种join性能会比较好吗? Flink CDC里之前用mysql数据库join比较慢,所以才改成同步宽表到es,不知道doris,starorcks 这种join性能会比较好吗? 参考答案: Flink CDC 主要用于捕获和处理数据库变更数据流,而不是直接优化JOIN操作。MySQL...
实时计算 Flink版产品使用问题之处理Kafka数据顺序时,怎么确保事件的顺序性
问题一:Flink CDC里从kafka消费的时候顺序会乱,这时候就无法区分顺序了,这种情况有办法处理吗? Flink CDC里从kafka消费的时候顺序会乱,这时候就无法区分顺序了,这种情况有办法处理吗?flink开窗排序可以解决,但遇到两个操作时间在同一时刻的咋办呢,有其它字段可以作标识区分吗?flink cdc到kafka是顺序的,但如果其中一条消息出现失败后重试,不会出现顺序问题...
flink kafka debezium-json读取更新的数据,没有op 怎么获取op为u的数据?
flink kafka debezium-json读取更新的数据,数据格式和官网提供的不一样没有op 为u的数据 怎么才能获取op为u的数据
flink SQL处理Kafka数据,json数据是数组的,建表结构该怎么写?[{},{}]。?
flink SQL处理Kafka数据,json数据是数组的,建表结构该怎么写?[{},{}]。这种的有人处理过这种格式的吗
哪位老师帮忙看一下,flink 1.13 消费kafka数据不消费数据也不报错?
哪位老师帮忙看一下,flink 1.13 消费kafka数据不消费数据也不报错?
在Flink CDC中,发到kafka下游再处理数据还是用算子处理完直接写到目标库里面?
在Flink CDC中,发到kafka下游再处理数据还是用算子处理完直接写到目标库里面?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
实时计算 Flink版数据相关内容
- 实时计算 Flink版实时同步oracle数据
- 实时计算 Flink版实时同步数据
- 实时计算 Flink版hive同步数据
- 实时计算 Flink版数据栈实践
- 实时计算 Flink版数据实践
- 实时计算 Flink版数据报错
- 实时计算 Flink版hdfs数据
- 实时计算 Flink版oss数据
- 实时计算 Flink版数据权限
- 实时计算 Flink版oracle数据权限
- 实时计算 Flink版同步oracle数据
- 实时计算 Flink版同步数据
- 集成实时计算 Flink版数据
- 实时计算 Flink版mysql数据变动
- 实时计算 Flink版数据变动
- 实时计算 Flink版mysql数据
- 实时计算 Flink版cdc mysql数据
- 实时计算 Flink版产品doris数据
- 实时计算 Flink版同步数据字段
- 实时计算 Flink版产品同步数据
- 实时计算 Flink版同步数据数据
- 实时计算 Flink版oracle同步数据
- 实时计算 Flink版doris数据
- 实时计算 Flink版mysql设置数据
- 实时计算 Flink版mysql字段数据
- 实时计算 Flink版设置捕获数据
- 实时计算 Flink版字段变更数据
- 实时计算 Flink版捕获变更数据
- 实时计算 Flink版mysql变更数据
- 实时计算 Flink版设置数据
实时计算 Flink版更多数据相关
- 实时计算 Flink版捕获数据
- 实时计算 Flink版字段数据
- 实时计算 Flink版变更数据
- 实时计算 Flink版数据排查
- 实时计算 Flink版数据背压
- 数据产品实时计算 Flink版
- 实时计算 Flink版方案数据
- 实时计算 Flink版kafka数据计算
- 实时计算 Flink版抽取oracle数据
- 实时计算 Flink版任务数据
- 实时计算 Flink版产品数据
- 实时计算 Flink版全量数据
- 实时计算 Flink版增量数据
- 实时计算 Flink版采集数据
- 实时计算 Flink版同步数据库
- 实时计算 Flink版数据kafka
- 实时计算 Flink版库数据
- 实时计算 Flink版报错数据
- 实时计算 Flink版数据配置
- 实时计算 Flink版数据字段
- 实时计算 Flink版cdc sql数据
- 实时计算 Flink版数据任务
- 实时计算 Flink版sink数据
- 实时计算 Flink版数据doris
- 实时计算 Flink版数据变更
- 实时计算 Flink版数据增量
- 实时计算 Flink版sqlserver数据
- 实时计算 Flink版监听数据
- 实时计算 Flink版日志数据
- 实时计算 Flink版窗口数据
实时计算 Flink版您可能感兴趣
- 实时计算 Flink版时空
- 实时计算 Flink版湖仓
- 实时计算 Flink版starrocks
- 实时计算 Flink版实践
- 实时计算 Flink版空间
- 实时计算 Flink版TaskManager
- 实时计算 Flink版文件
- 实时计算 Flink版checkpoint
- 实时计算 Flink版编译
- 实时计算 Flink版架构
- 实时计算 Flink版CDC
- 实时计算 Flink版SQL
- 实时计算 Flink版mysql
- 实时计算 Flink版报错
- 实时计算 Flink版同步
- 实时计算 Flink版任务
- 实时计算 Flink版flink
- 实时计算 Flink版实时计算
- 实时计算 Flink版版本
- 实时计算 Flink版oracle
- 实时计算 Flink版kafka
- 实时计算 Flink版表
- 实时计算 Flink版配置
- 实时计算 Flink版产品
- 实时计算 Flink版Apache
- 实时计算 Flink版设置
- 实时计算 Flink版作业
- 实时计算 Flink版模式
- 实时计算 Flink版数据库
- 实时计算 Flink版运行
