
Kubernetes网络问题排查分享两则(1)——calico特定场景下的网络性能问题
问题一:calico特定场景下的网络性能问题 **问题现象** 最近我们在做kosmos的性能测试,本来是想做一个简单的对比,说明我们kosmos搭建的vxlan网络和calico的集群内的容器网络性能差不多在同一水平,但是测试下来,我们发现kosmos在连通跨集群的容器网络时,表现竟然远远好于calico的集群内容器网络,这令我们非常困惑。 我们先看下集群内的calico容器网络,ipe...

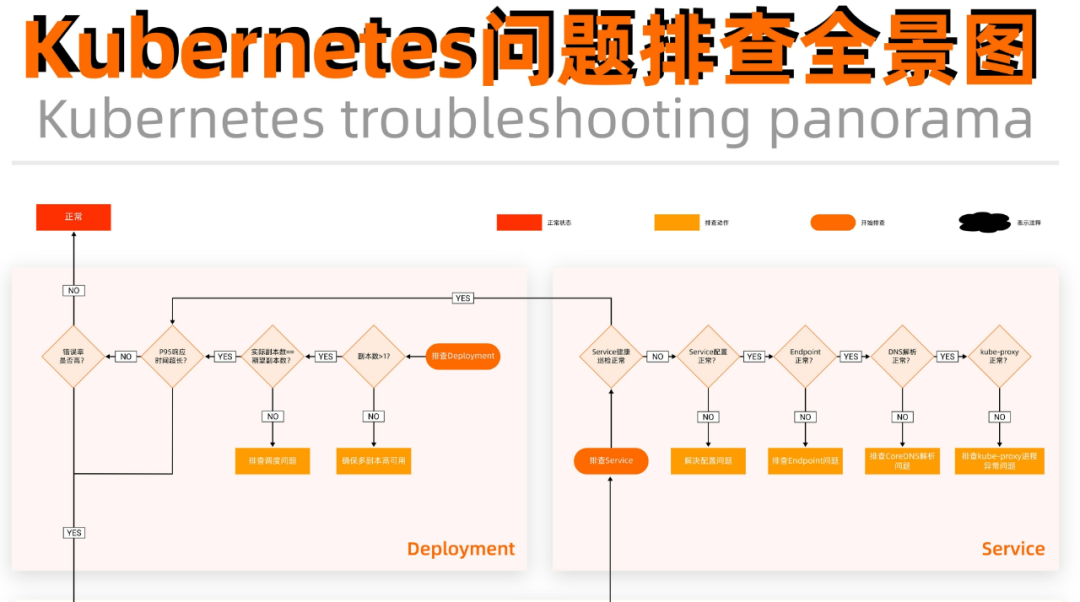
Kubernetes 问题排查全景图
伴随着混沌的微服务架构,多语言和多网络协议混杂。以及下沉的基础设施能力屏蔽实现细节,问题定界越发困难。企业急需一种支持多语言,多通信协议的技术,并在产品层面尽可能覆盖软件栈端到端的可观测性需求。「Kubernetes 问题排查全景图」立足于容器界面和底层操作系统,向上关联应用性能监测的可观测性解决思路。帮助你更有效、更快捷地定位生产环境问题。关注【云原生百宝箱】公众号,快速掌握云原生推荐阅读叮,....
kubernetes dns 解析超时问题排查
事故发起方在客户内网机器环境内部署的 grafana 一直获取不到 prometheus 的数据,导致页面一直展示 no data通过 grafana 页面测试 prometheus 数据源验证了这个问题,grafana 一直链接不上 prometheus 数据源事故处理流程grafana 容器访问 prometheus 的 svc配置 curl-format 获取接口访问时间time_name....
《云原生网络数据面可观测性最佳实践》——四、ACK Net-Exporter 快速上手——3.典型问题排查指南
1) DNS超时相关问题在云原生环境中,DNS服务超时问题会导致服务的访问失败,出现DNS访问超时的常见原因有: ● DNS服务响应的速度较慢,无法在用户程序的超时时间到达前完成一次DNS查询。● 由于发送端的问题,没有顺利或者及时发送DNS Query报文。● 服务端及时响应了报文,但是由于发送端本身的内存不足等问题出现了丢包。 您可以借助以下几个指标来帮助排查偶发的DNS....
利用 Rainbond 云原生平台简化 Kubernetes 业务问题排查
Kubernetes 已经成为了云原生时代基础设施的事实标准,越来越多的应用系统在 Kubernetes 环境中运行。Kubernetes 已经依靠其强大的自动化运维能力解决了业务系统的大多数运行维护问题,然而还是要有一些状况是需要运维人员去手动处理的。那么和传统运维相比,面向 Kubernetes 解决业务运维问题是否有一些基本思路,是否可以借助其他工具简化排查流程,就是今天探讨的主题。业务问....
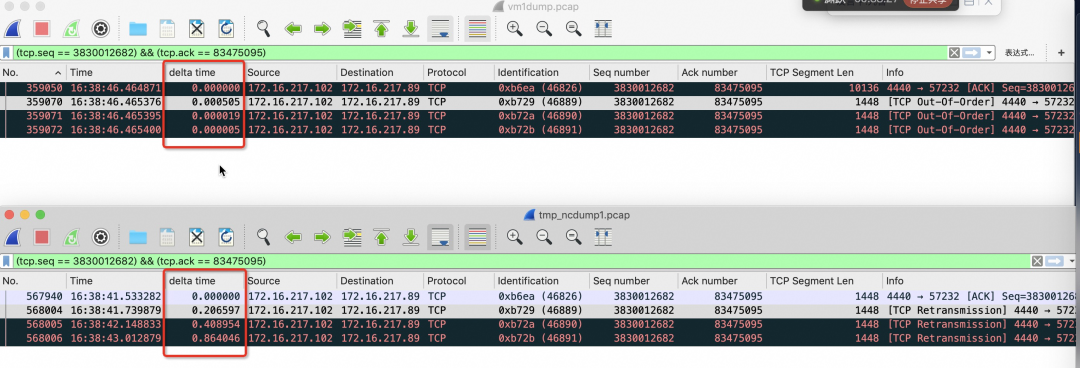
ACK Net Exporter 与 sysAK 出击:一次深水区的网络疑难问题排查经历
作者:谢石、碎牙不久前的一个周五的晚上,某客户A用户体验提升群正处在一片平静中,突然,一条简短的消息出现,打破了这种祥和:“我们在ACK上创建的集群,网络经常有几百毫秒的延迟。"偶发,延迟,几百毫秒。这三个关键字迅速集中了我们紧张的神经,来活儿了, 说时迟,那时快,我们马上就进入到了客户的问题攻坚群。问题的排查过程常规手段初露锋芒客户通过钉钉群反馈之前已经进行了基本的排查,具体的现象如下:不同的....
【JVM故障问题排查心得】「内存诊断系列」Docker容器经常被kill掉,k8s中该节点的pod也被驱赶,怎么分析?
背景介绍最近的docker容器经常被kill掉,k8s中该节点的pod也被驱赶。我有一个在主机中运行的Docker容器(也有在同一主机中运行的其他容器)。该Docker容器中的应用程序将会计算数据和流式处理,这可能会消耗大量内存。该容器会不时退出。我怀疑这是由于内存不足,但不是很确定。我需要找到根本原因的方法。那么有什么方法可以知道这个集装箱的死亡发生了什么?容器层级判断检测提到docker l....

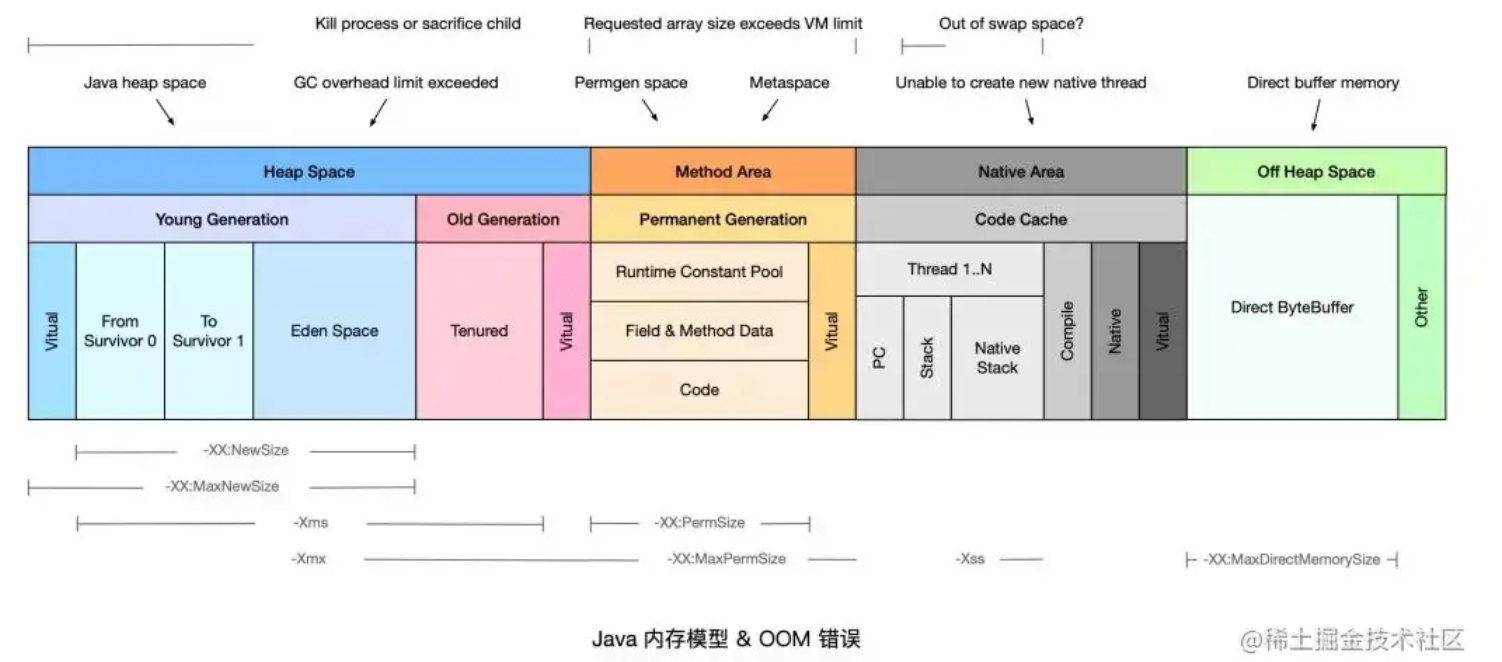
【JVM故障问题排查心得】「内存诊断系列」JVM内存与Kubernetes中pod的内存、容器的内存不一致所引发的OOMKilled问题总结(下)
承接上文之前文章根据《【JVM故障问题排查心得】「内存诊断系列」JVM内存与Kubernetes中pod的内存、容器的内存不一致所引发的OOMKilled问题总结(上)》我们知道了如何进行设置和控制对应的堆内存和容器内存的之间的关系,所以防止JVM的堆内存超过了容器内存,导致容器出现OOMKilled的情况。但是在整个JVM进程体系而言,不仅仅只包含了Heap堆内存,其实还有其他相关的内存存储空....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
容器服务Kubernetes版问题排查相关内容
容器服务Kubernetes版您可能感兴趣
- 容器服务Kubernetes版抓取
- 容器服务Kubernetes版aks
- 容器服务Kubernetes版目标
- 容器服务Kubernetes版pod
- 容器服务Kubernetes版包
- 容器服务Kubernetes版方法
- 容器服务Kubernetes版网络
- 容器服务Kubernetes版节点
- 容器服务Kubernetes版推理
- 容器服务Kubernetes版智能
- 容器服务Kubernetes版集群
- 容器服务Kubernetes版部署
- 容器服务Kubernetes版容器
- 容器服务Kubernetes版应用
- 容器服务Kubernetes版云原生
- 容器服务Kubernetes版服务
- 容器服务Kubernetes版阿里云
- 容器服务Kubernetes版 Pod
- 容器服务Kubernetes版docker
- 容器服务Kubernetes版k8s
- 容器服务Kubernetes版 Docker
- 容器服务Kubernetes版安装
- 容器服务Kubernetes版 K8S
- 容器服务Kubernetes版实践
- 容器服务Kubernetes版配置
- 容器服务Kubernetes版架构
- 容器服务Kubernetes版kubernetes
- 容器服务Kubernetes版资源
- 容器服务Kubernetes版 kubernetes
- 容器服务Kubernetes版实战

