
基于SQL Server / MySQL进行百万条数据过滤优化方案
基于SQL Server / MySQL进行百万条数据过滤优化方案 在处理大型数据集时,查询优化是确保数据库性能的关键。对于SQL Server和MySQL数据库,优化查询尤其重要,因为它们广泛应用于各种业务场景。本文将介绍在SQL Server和MySQL中对百万级别数据进行过滤查询的优化方案。 一、索引优化 索引是数据库优化的关键。合理使用索引可以显...
Spark SQL诊断优化
云原生数据仓库 AnalyticDB MySQL 版推出Spark SQL诊断功能,若您提交的Spark SQL存在性能问题,您可以根据诊断信息快速定位、分析并解决性能瓶颈问题,优化Spark SQL。本文主要介绍如何进行Spark SQL性能诊断以及性能诊断的示例。
在Flink CDC中,mysql有个150g的数据,全量同步的话,有啥优化点吗?
在Flink CDC中,mysql有个150g的数据,全量同步的话,有啥优化点吗?好几次,一大半了,然后oom了
MySQL数据库——SQL优化(1/3)-介绍、插入数据、主键优化
介绍 SQL优化将分为下面几个部分进行学习: 插入数据 主键优化 order by优化 group by优化 imit优化 count优化 update优化 首先就先来看第一方面, 插入数据 Insert 如果我们需要一次性往数据库表中插入多条记录...
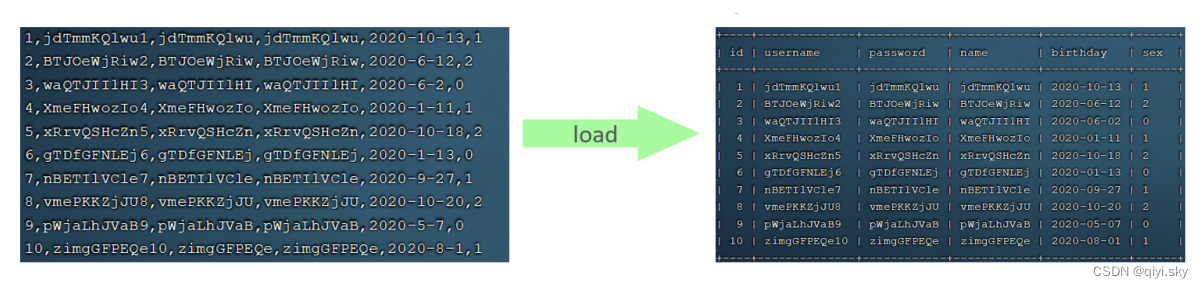
如何使用B-tree并发控制优化机制
PolarDB MySQL版优化了B-tree索引的并发控制机制,有效地提升了高并发读写场景下的性能。本文介绍了B-tree并发控制优化的使用方法和使用该机制的限制和前提条件等内容。
MySQL百万数据深度分页优化思路分析
MySQL百万数据深度分页优化思路分析一、业务背景一般在项目开发中会有很多的统计数据需要进行上报分析,一般在分析过后会在后台展示出来给运营和产品进行分页查看,最常见的一种就是根据日期进行筛选。这种统计数据随着时间的推移数据量会慢慢的变大,达到百万、千万条数据只是时间问题。二、瓶颈再现创建了一张user表,给create_time字段添加了索引。并在该表中添加了100w条数据。我们这里使用limi....
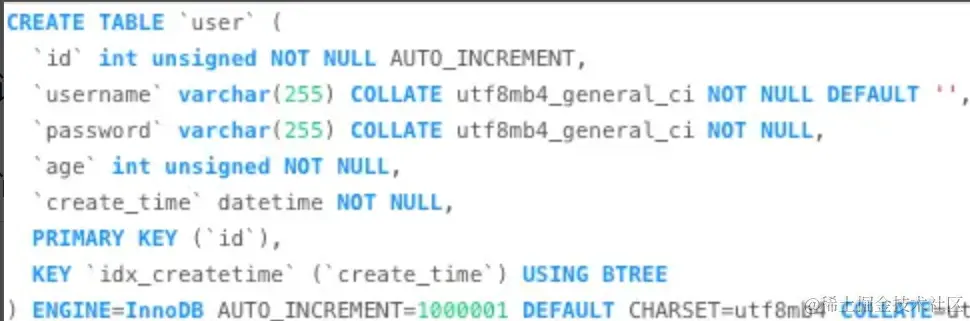
通过Beam排序键进行范围查询或等值筛选_云原生数据仓库 AnalyticDB PostgreSQL版(AnalyticDB for PostgreSQL)
若您经常针对Beam表的某几列进行范围查询或等值筛选时,您可以使用Beam排序键(组合排序键或多维排序键),获得更优的查询性能。
向 MySQL 数据库插入 100w 条数据的优化方案
多线程插入(单表)问:为何对同一个表的插入多线程会比单线程快?同一时间对一个表的写操作不应该是独占的吗?答:在数据里做插入操作的时候,整体时间的分配是这样的:链接耗时 (30%)发送query到服务器 (20%)解析query (20%)插入操作 (10% * 词条数目)插入index (10% * Index的数目)关闭链接 (10%)从这里可以看出来,真正耗时的不是操作,而是链接,解析的过程....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云数据库 RDS MySQL 版优化相关内容
- 云数据库 RDS MySQL 版优化方案
- 云数据库 RDS MySQL 版日志优化
- 云数据库 RDS MySQL 版优化办法
- 云数据库 RDS MySQL 版分页优化
- 云数据库 RDS MySQL 版概述优化
- 云数据库 RDS MySQL 版排序优化
- 云数据库 RDS MySQL 版join优化
- 云数据库 RDS MySQL 版优化原则
- 云数据库 RDS MySQL 版sql优化
- 云数据库 RDS MySQL 版explain优化
- 云数据库 RDS MySQL 版优化实践
- 云数据库 RDS MySQL 版优化应用
- 面试云数据库 RDS MySQL 版优化
- 云数据库 RDS MySQL 版查询优化优化
- 优化云数据库 RDS MySQL 版
- 优化云数据库 RDS MySQL 版调优
- 云数据库 RDS MySQL 版协同作战优化
- 云数据库 RDS MySQL 版redis优化
- 云数据库 RDS MySQL 版优化实战
- 云数据库 RDS MySQL 版优化分页
- 云数据库 RDS MySQL 版优化数据统计
- 云数据库 RDS MySQL 版优化实录
- 云数据库 RDS MySQL 版数据量优化
- 云数据库 RDS MySQL 版索引优化数据库
- 日常工作云数据库 RDS MySQL 版优化
- 云数据库 RDS MySQL 版配置优化
- 云数据库 RDS MySQL 版分组分页优化
- 云数据库 RDS MySQL 版子查询优化
- 云数据库 RDS MySQL 版排序分组优化
- 云数据库 RDS MySQL 版分组优化
云数据库 RDS MySQL 版更多优化相关
- 云数据库 RDS MySQL 版优化脚本
- 云数据库 RDS MySQL 版优化cpu
- 云数据库 RDS MySQL 版优化内存
- 云数据库 RDS MySQL 版优化解析
- 云数据库 RDS MySQL 版运维优化
- 云数据库 RDS MySQL 版优化测试
- 云数据库 RDS MySQL 版主从复制优化
- 云数据库 RDS MySQL 版参数优化实践
- 云数据库 RDS MySQL 版子查询优化join
- 云数据库 RDS MySQL 版分析优化
- 云数据库 RDS MySQL 版优化索引
- 云数据库 RDS MySQL 版order优化
- 云数据库 RDS MySQL 版优化配置
- 云数据库 RDS MySQL 版架构优化
- 云数据库 RDS MySQL 版性能优化优化
- 云数据库 RDS MySQL 版优化查询优化
- 云数据库 RDS MySQL 版优化步骤
- 云数据库 RDS MySQL 版内存优化
- 数据库云数据库 RDS MySQL 版优化
- 云数据库 RDS MySQL 版优化学习
- 云数据库 RDS MySQL 版优化explain
- 云数据库 RDS MySQL 版大表优化方案
- 云数据库 RDS MySQL 版系统优化
- 云数据库 RDS MySQL 版硬件优化
- 云数据库 RDS MySQL 版优化器优化
- 云数据库 RDS MySQL 版技术优化
- 云数据库 RDS MySQL 版优化系统
- 云数据库 RDS MySQL 版优化笔记
- 云数据库 RDS MySQL 版优化参数
- 云数据库 RDS MySQL 版性能调优优化
云数据库 RDS MySQL 版您可能感兴趣
- 云数据库 RDS MySQL 版索引
- 云数据库 RDS MySQL 版slave
- 云数据库 RDS MySQL 版定时任务
- 云数据库 RDS MySQL 版数据库连接
- 云数据库 RDS MySQL 版解决方案
- 云数据库 RDS MySQL 版数据库
- 云数据库 RDS MySQL 版char
- 云数据库 RDS MySQL 版groupby
- 云数据库 RDS MySQL 版sql
- 云数据库 RDS MySQL 版类型
- 云数据库 RDS MySQL 版数据
- 云数据库 RDS MySQL 版安装
- 云数据库 RDS MySQL 版同步
- 云数据库 RDS MySQL 版连接
- 云数据库 RDS MySQL 版mysql
- 云数据库 RDS MySQL 版查询
- 云数据库 RDS MySQL 版报错
- 云数据库 RDS MySQL 版配置
- 云数据库 RDS MySQL 版rds
- 云数据库 RDS MySQL 版flink
- 云数据库 RDS MySQL 版cdc
- 云数据库 RDS MySQL 版表
- 云数据库 RDS MySQL 版实例
- 云数据库 RDS MySQL 版备份
- 云数据库 RDS MySQL 版操作
- 云数据库 RDS MySQL 版linux
- 云数据库 RDS MySQL 版polardb
- 云数据库 RDS MySQL 版阿里云
- 云数据库 RDS MySQL 版php
- 云数据库 RDS MySQL 版 sql

