
Python爬虫神器requests库的使用
在现代编程中,网络请求几乎是每个项目不可或缺的一部分。无论是获取数据、发送信息,还是与第三方 API 交互,都会涉及到网络请求。 今天,我们就来详细介绍一下 Python 中的 requests 库,它是一个功能强大、使用方便的 HTTP 请求库。🚀 让我们从基础知识开始,一步步深入了解它的特性和...

构建高效Python爬虫:探索BeautifulSoup与Requests库的协同工作
在当今信息爆炸的时代,互联网上充斥着大量有价值的数据。从在线零售商的价格信息到社交媒体上的舆论趋势,对这些数据的采集和分析可以揭示出许多不为人知的见解。因此,掌握网络爬虫技术对于希望从海量数据中提取有用信息的人士来说至关重要。本文将重点介绍如何使用Python编程语言中的BeautifulSoup和Requests库来构建一个高效且功能强大的网络爬虫。 ...
Python爬虫面试:requests、BeautifulSoup与Scrapy详解
在Python爬虫开发的面试过程中,对requests、BeautifulSoup与Scrapy这三个核心库的理解和应用能力是面试官重点考察的内容。本篇文章将深入浅出地解析这三个工具,探讨面试中常见的问题、易错点及应对策略,并通过代码示例进一步加深理解。 1. requests:网络请求库 常见问题: 如何处理HTTP状态码异常? 如何处理代理设置、cookies管理及session...

Python爬虫requests库详解#3
使用 requests 上一节中,我们了解了 urllib 的基本用法,但是其中确实有不方便的地方,比如处理网页验证和 Cookies 时,需要写 Opener 和 Handler 来处理。为了更加方便地实现这些操作,就有了更为强大的库 requests,有了它,Cookies、登录验证、代理设置等操作都不是事儿。 接下来,让我们领略一下它的强大之处吧。 基本...

Python 爬虫(二):Requests 库
所谓爬虫就是模拟客户端发送网络请求,获取网络响应,并按照一定的规则解析获取的数据并保存的程序。要说 Python 的爬虫必然绕不过 Requests 库。 1 简介 对于 Requests 库,官方文档是这么说的: Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。警告:非专...

python爬虫库之Requests
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更简洁方便。所以今天我们来重点了解下这个库。 Requests是唯一的一个非转基因的 Python HTTP 库,Requests 继承了urllib2的所有特性。Requests支持HTTP连接保.....

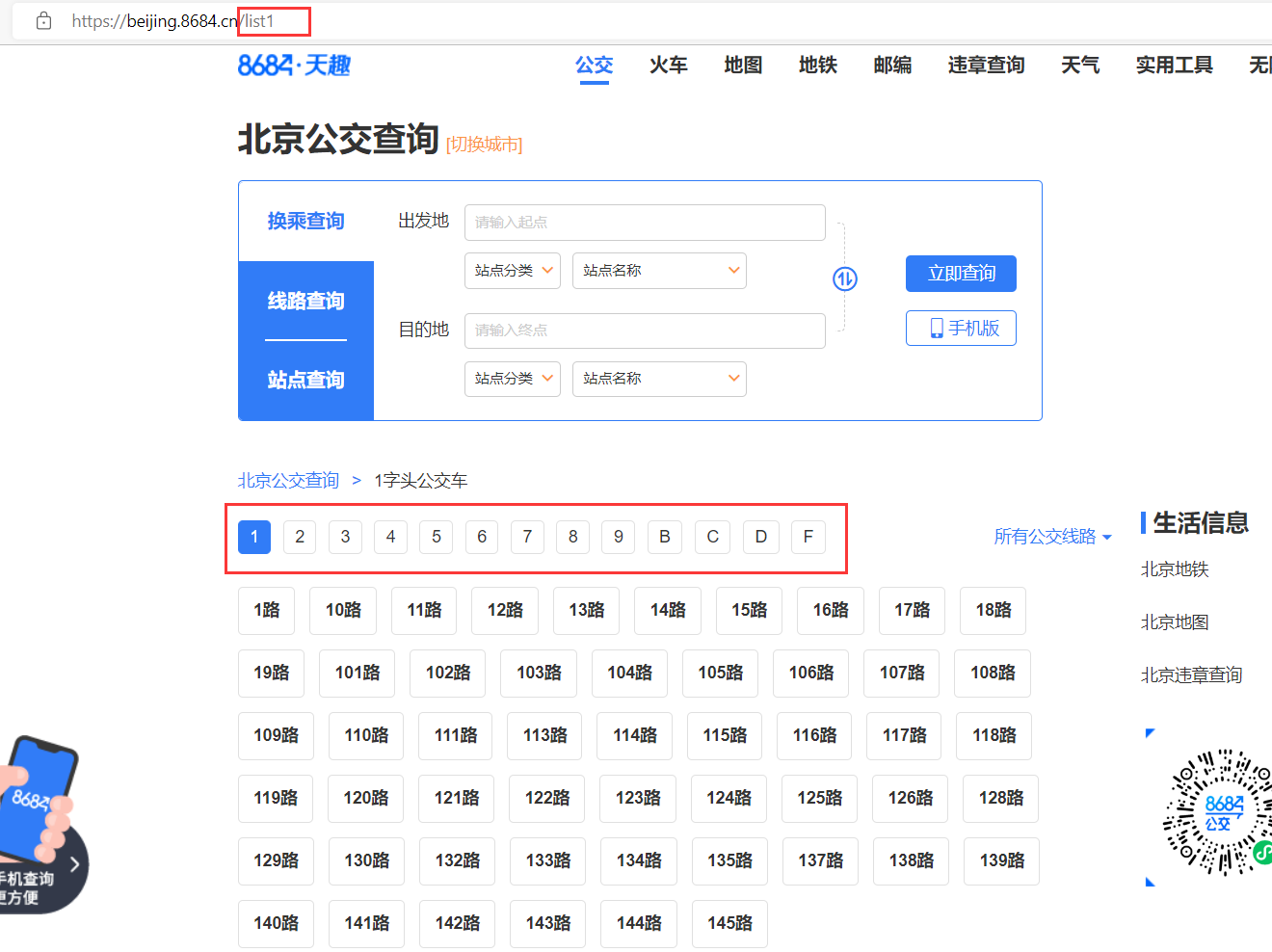
「Python」爬虫实战-北京公交线路信息爬取(requests+bs4)
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第4天, 点击查看活动详情公交线路爬取使用requests爬取北京公交线路信息,目标网址为https://beijing.8684.cn/。爬取的具体信息为公交线路名称、公交的运营范围、运行时间、参考票价、公交所属的公司以及服务热线、公交来回线路的途径站点。考虑到现代技术与日俱进,反爬措施层数不穷,故可以考虑构建用户代...
Python爬虫:splash+requests简单示例
说明:render是get方式execute是post方式renderimport requests def splash_render(url): splash_url = "http://localhost:8050/render.html" args = { "url": url, "timeout": 5, "image":...
Python爬虫:使用requests库下载大文件
当使用requests的get下载大文件/数据时,建议使用使用stream模式。当把get函数的stream参数设置成False时,它会立即开始下载文件并放到内存中,如果文件过大,有可能导致内存不足。当把get函数的stream参数设置成True时,它不会立即开始下载,当你使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。需要注意一点:文件没有下载之前,它也需....
Python爬虫:requests库基本使用
requests 基于urlib库pip install requests用于http测试的网站:http://httpbin.org/需要导入的模块import requests from requests.models import Response简单测试def foo1(): response = requests.get("http://www.baidu.com") ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Python requests相关内容
- Python requests post请求
- Python requests请求参数
- requests Python
- Python requests post
- Python Requests库
- Python requests接口自动化
- Python requests http
- Python requests httpx
- Python requests会话
- Python requests超时
- Python requests性能
- Python网络请求requests
- Python requests库网络
- Python网络请求requests urllib
- Python requests urllib
- Python http requests
- Python beautifulsoup requests
- Python requests get
- 函数计算Python requests
- Python requests代理
- Python requests入门
- Python module named requests
- Python requests库数据
- Python udf requests
- Python requests scrapy
- Python requests beautifulsoup
- Python requests抓取
- Python requests cookie
- Python requests基本使用urllib区别
- Python requests基本使用