
【Linux】为什么海量存储选用大文件结构
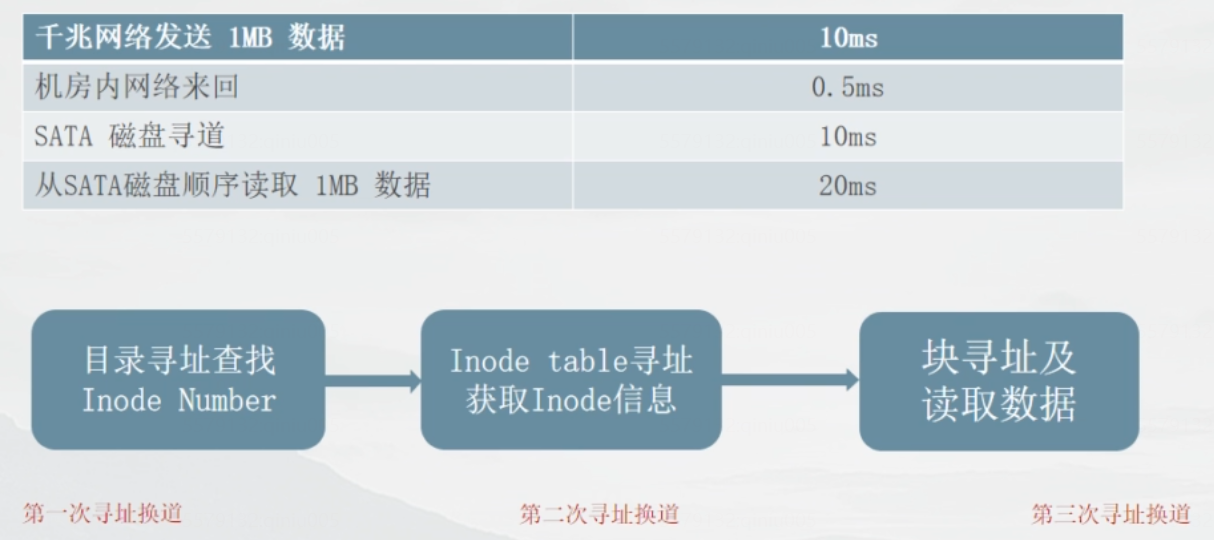
为什么海量存储选用大文件结构大规模的小文件存取,磁头需要频繁的寻道和换道,因此在读取上容易带来较长的延时。频繁的新增删除操作,导致磁盘碎片,降低磁盘利用率和IO读写效率。后面再存文件,优先选取连续的一块区域。前面的小区域就得不到利用,多次删除造成磁盘出现一块一块的小区域。Inode占用大量磁盘空间,降低了缓存的效果。
菜鸟学Linux 第105篇笔记 海量存储解决
菜鸟学Linux 第105篇笔记 海量存储解决 内容总览 大数据带来的挑战 传统存储SAN 分布式存储 多线程与进程执行模式 计算机五大部件变化 分布式系统的难点 分布式文件系统设计目标 分布式事务的模型及规范 CAP, BASE, 集群内数据一致性算法实施过程案例 分布式应用(存储,计算) mogilefs DFS 大数据带来的挑战 数据采集(传感器) ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

Linux宝库