
【Spark】(四)Spark 广播变量和累加器
文章目录一、概述二、广播变量broadcast variable2.1 为什么要将变量定义成广播变量?2.2 广播变量图解2.3 如何定义一个广播变量?2.4 如何还原一个广播变量?2.5 定义广播变量需要的注意点?2.6 注意事项三、累加器3.1 为什么要将一个变量定义为一个累加器?3.2 图解累加器3.3 如何定义一个累加器?3.4 如何还原一个累加器?3.5 注意事项一、概述在spark程....
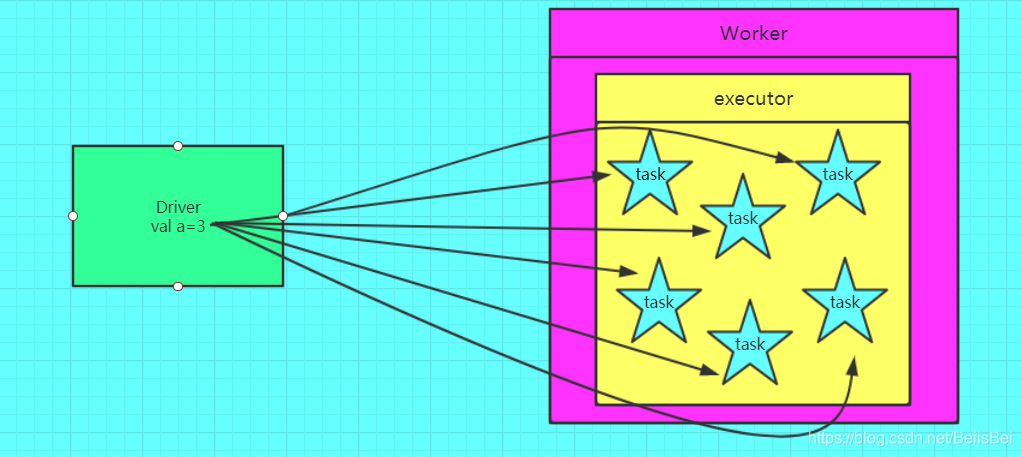
Spark的共享变量(广播变量和累加器)底层实现
Spark一个非常重要的特性就是共享变量。默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中,此时每个task只能操作自己的那份变量副本。如果多个task想要共享某个变量,那么这种方式是做不到的。Spark为此提供了两种共享变量,一种是Broadcast Variable(广播变量),另一种是Accumulator(累加变量)。Broadcast ....
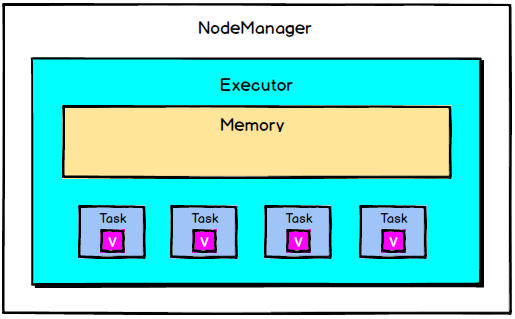
Spark中广播变量详解
【前言:Spark目前提供了两种有限定类型的共享变量:广播变量和累加器,今天主要介绍一下基于Spark2.4版本的广播变量。先前的版本比如Spark2.1之前的广播变量有两种实现:HttpBroadcast和TorrentBroadcast,但是鉴于HttpBroadcast有各种弊端,目前已经舍弃这种实现,本篇文章也主要阐述TorrentBroadcast】 广播变量概述 广播变量是一个只读变....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark Hive
- apache spark安装
- apache spark日志
- apache spark分析
- apache spark应用
- apache spark OSS
- apache spark机制
- apache spark缓存
- apache spark rdd
- apache spark湖仓
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark操作
- apache spark技术
- apache spark yarn
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注