
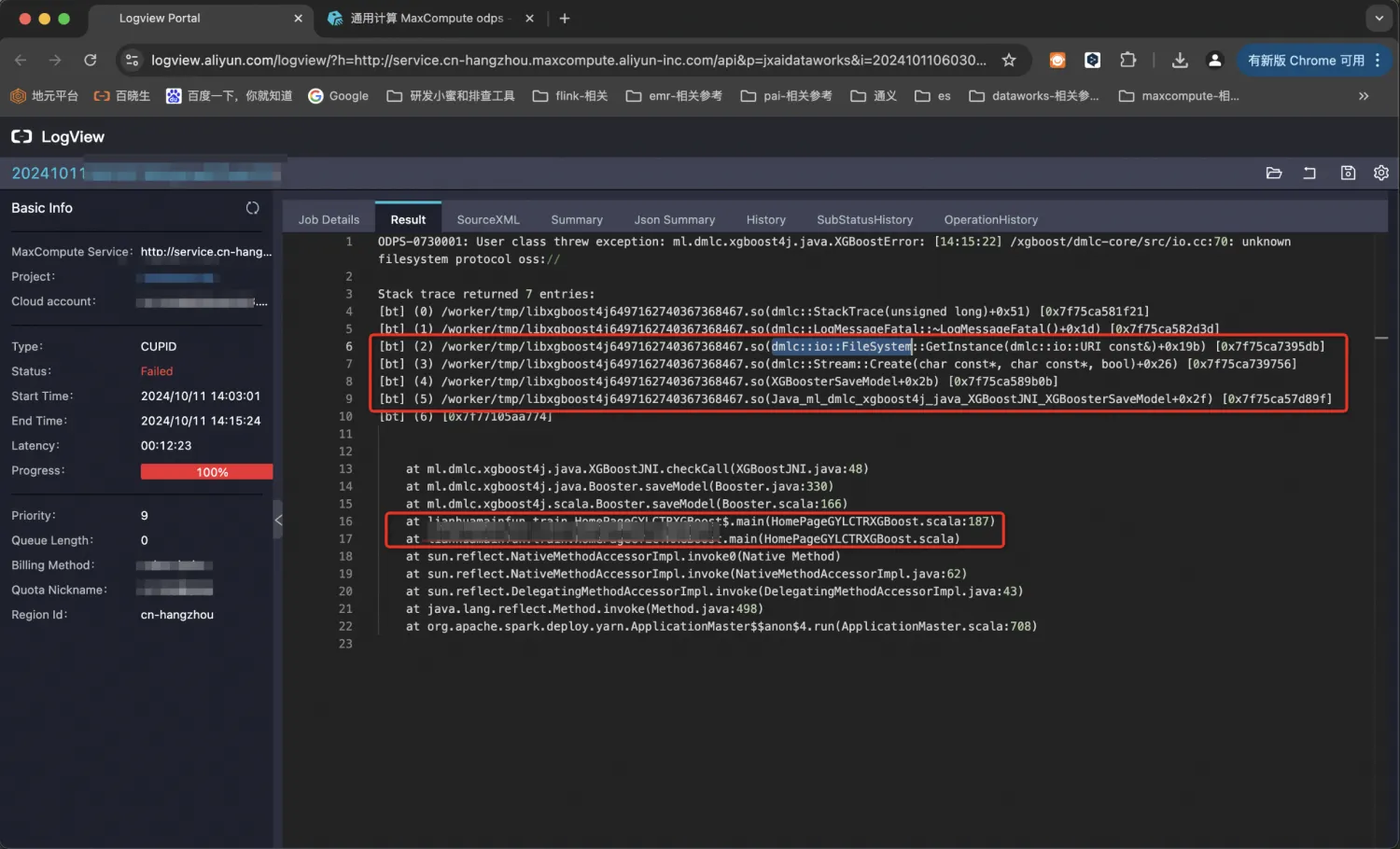
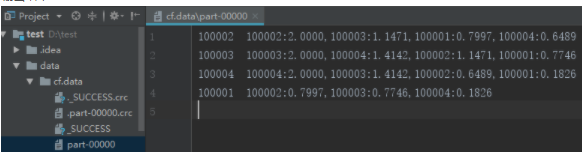
阿里云MaxCompute-XGBoost on Spark 极限梯度提升算法的分布式训练与模型持久化oss的实现与代码浅析
1. XGBoost简介 XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。它在GBDT框架的基础上实现机器学习算法。XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。XGBoost最初是一个研究项目,孵化于Distributed (Deep) Machine Learning Community (DMLC) ,由陈天奇博...
大数据-106 Spark Graph X 计算学习 案例:1图的基本计算、2连通图算法、3寻找相同的用户
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

Spark中的机器学习库MLlib是什么?请解释其作用和常用算法。
Spark中的机器学习库MLlib是什么?请解释其作用和常用算法。Spark中的机器学习库MLlib是一个用于大规模数据处理的机器学习库。它提供了一组丰富的机器学习算法和工具,可以用于数据预处理、特征提取、模型训练和评估等任务。MLlib是基于Spark的分布式计算引擎构建的,可以处理大规模数据集,并利用分布式计算的优势来加速机器学习任务的执行。MLlib的作用是为开发人员和数据科学家提供一个高....
大数据Spark MLlib推荐算法
1 相似度算法无论是基于用户还是基于商品的推荐,都是需要找到相似的用户或者商品,才能做推荐,所以,相似度算法就变得非常重要了。常见的相似度算法有:欧几里德距离算法(Euclidean Distance)皮尔逊相似度算法(Pearson Correlation Coefficient)基于夹角余弦相似度算法(Consine Similarity)基于Tanimoto系数相似度(Tanimoto C....

ALS算法 java spark rdd简单实现
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.m....
Java编写的Spark ALS协同过滤推荐算法的源代码能共享一下
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.m....

Spark实现协同过滤CF算法实践
Spark编写Scala实现CF算法UI矩阵–>II矩阵–>排序package spark.example import org.apache.spark._ import SparkContext._ import scala.collection.mutable.ArrayBuffer import scala.math._ object CollaborativeFilteri....
【Spark MLlib】(六)协同过滤 (Collaborative Filtering) 算法分析
文章目录一、协同过滤1.1 概念1.2 分类二、矩阵分解2.1 显式矩阵分解2.2 隐式矩阵分解(关联因子分确定,可能随时会变化)2.3 最小二乘法(Alternating Least Squares ALS):解决矩阵分解的最优化方法三、Spark MLlib中ALS算法的应用一、协同过滤1.1 概念协同过滤是一种借助"集体计算"的途径。它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜....

基于Spark的机器学习实践 (九) - 聚类算法
0 相关源码1 k-平均算法(k-means clustering)概述1.1 回顾无监督学习◆ 分类、回归都属于监督学习◆ 无监督学习是不需要用户去指定标签的◆ 而我们看到的分类、回归算法都需要用户输入的训练数据集中给定一个个明确的y值1.2 k-平均算法与无监督学习◆ k-平均算法是无监督学习的一种◆ 它不需要人为指定一个因变量,即标签y ,而是由程序自己发现,给出类别y◆ 除此之外,无监督....
汇量科技在Spark上 构建推荐算法Pipeline的实践
内容简要:一、关于汇量科技二、一个典型的推荐算法实验流程三、问题和挑战四、在Spark上构建推荐算法Pipeline 一、关于汇量科技(Mobvista)汇量科技是:• 一站式的移动广告服务和数据统计分析服务;• 日均千亿次的在线广告个性化匹配;• 全流量 DNN 模型排序;• 构建了一站式机器学习平台MindAlpha。 二、一个典型的推荐算法实验流....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark训练
- apache spark特征
- apache spark实战
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark yarn
- apache spark技术
- apache spark操作
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注