
创建并使用EMR Spark SQL节点
您可以通过创建EMR(E-MapReduce) Spark SQL节点,实现分布式SQL查询引擎处理结构化数据,提高作业的执行效率。
Lindorm Spark SQL节点,Lindorm Spark SQL
DataWorks的Lindorm Spark SQL节点可进行Lindorm Spark SQL任务的开发和周期性调度。本文为您介绍使用Lindorm Spark SQL节点进行任务开发的主要流程。
Spark SQL交互式查询
如果您需要以交互式方式执行Spark SQL,可以指定Spark Interactive型资源组作为执行查询的资源组。资源组的资源量会在指定范围内自动扩缩容,在满足您交互式查询需求的同时还可以降低使用成本。本文为您详细介绍如何通过控制台、Hive JDBC、PyHive、Beeline、DBeaver等客户端工具实现Spark SQL交互式查询。
通过Spark SQL读写SQL Server数据
云原生数据仓库 AnalyticDB MySQL 版支持提交Spark SQL作业,您可以通过View方式访问自建SQL Server数据库或云数据库 RDS SQL Server 版数据库。本文以云数据库 RDS SQL Server 版为例,介绍如何通过Spark SQL访问SQL Server数据。
【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件夹scala,界面如下:6) 将文件夹scala设置成Source Root,界面如下:7) 新建....
Spark SQL实战(08)-整合Hive
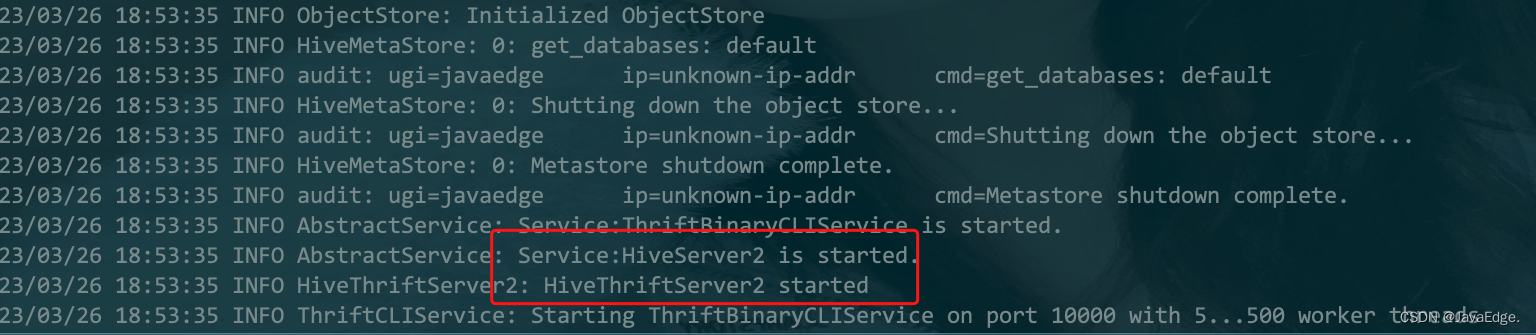
1 整合原理及使用Apache Spark 是一个快速、可扩展的分布式计算引擎,而 Hive 则是一个数据仓库工具,它提供了数据存储和查询功能。在 Spark 中使用 Hive 可以提高数据处理和查询的效率。场景历史原因积累下来的,很多数据原先是采用Hive来进行处理的,现想改用Spark操作数据,须要求Spark能够无缝对接已有的Hive的数据,实现平滑过渡。MetaStoreHive底层的元....
Spark SQL实战(07)-Data Sources
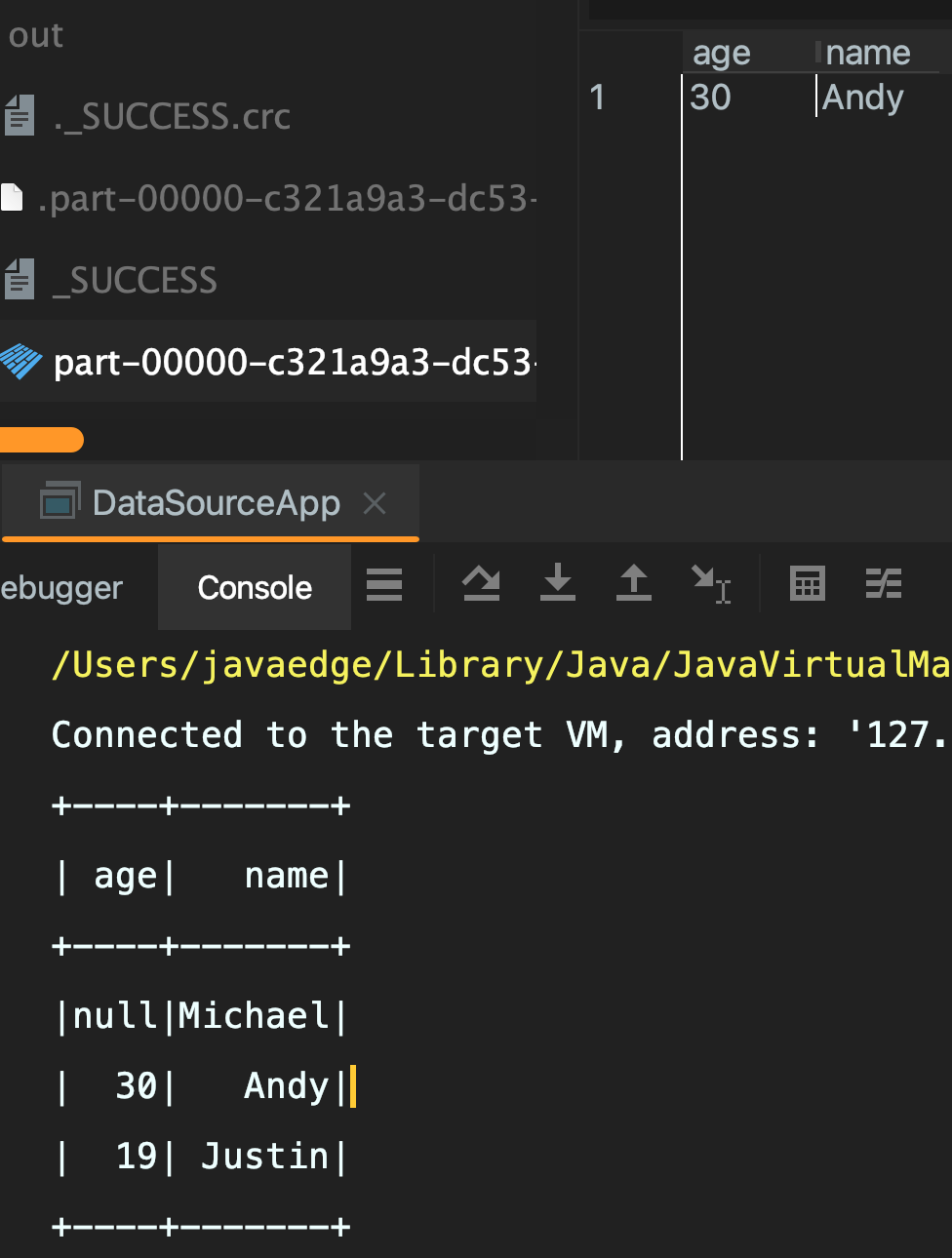
1 概述Spark SQL通过DataFrame接口支持对多种数据源进行操作。DataFrame可使用关系型变换进行操作,也可用于创建临时视图。将DataFrame注册为临时视图可以让你对其数据运行SQL查询。本节介绍使用Spark数据源加载和保存数据的一般方法,并进一步介绍可用于内置数据源的特定选项。数据源关键操作:loadsave2 大数据作业基本流程input 业务逻辑 output不管是....
Spark SQL实战(06)-RDD与DataFrame的互操作
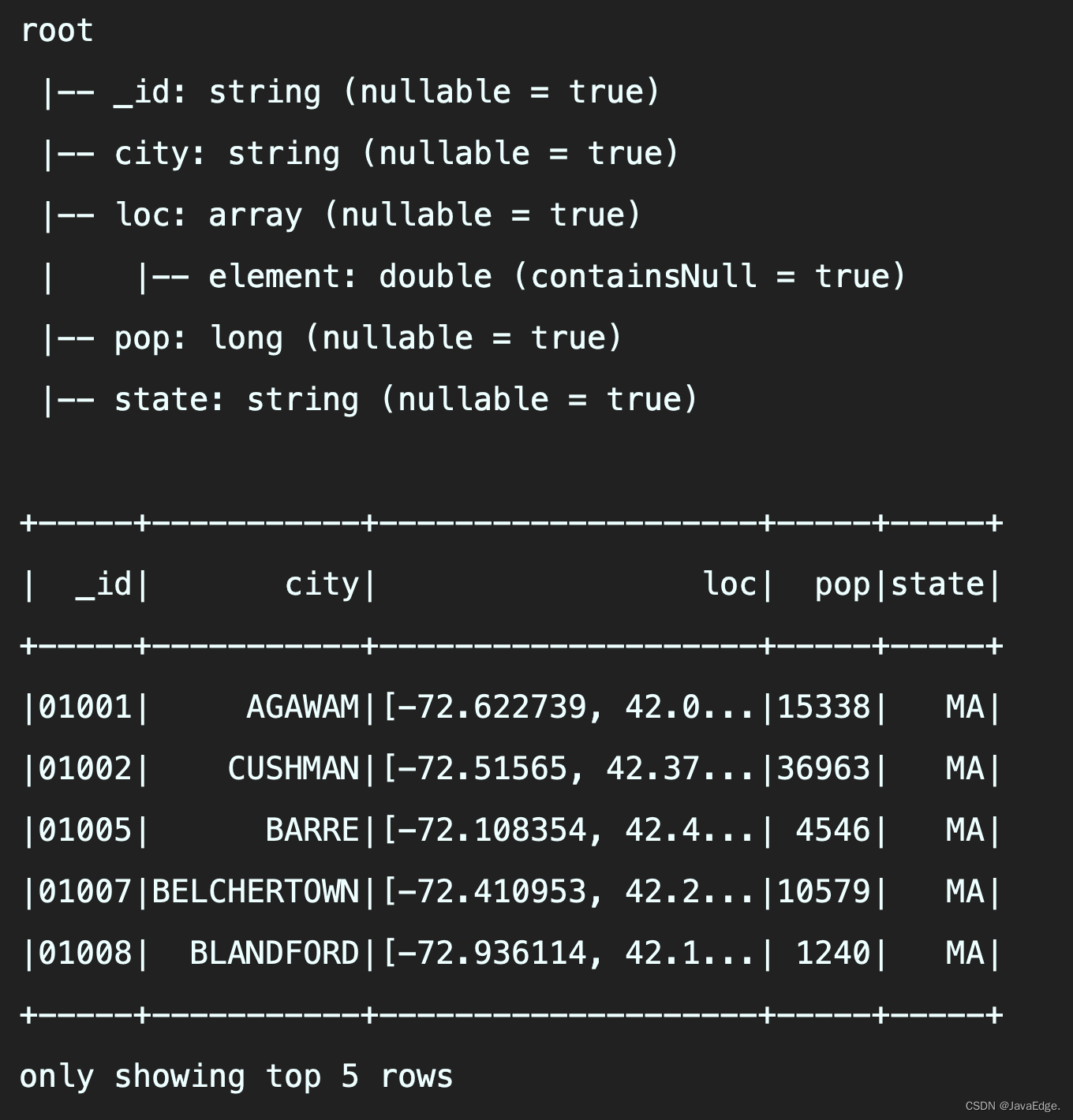
val spark = SparkSession.builder() .master("local").appName("DatasetApp") .getOrCreate()Spark SQL支持两种不同方法将现有RDD转换为DataFrame:1 反射推断包含特定对象类型的 RDD 的schema。这种基于反射的方法可以使代码更简洁,在编写 Spark 应用程序时已知....
Spark SQL实战(04)-API编程之DataFrame
1 SparkSessionSpark Core: SparkContextSpark SQL: 难道就没有SparkContext?2.x之后统一的package com.javaedge.bigdata.chapter04import org.apache.spark.sql.{DataFrame, SparkSession}object SparkSessionApp { de....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark更多sql相关
- apache spark sql引擎优化
- apache spark sql引擎
- apache spark SQL DataFrame
- apache spark SQL数据源
- 大数据apache spark sql dataframe
- apache spark sql概述
- apache spark sql库
- apache spark sql访问
- apache spark sql代码
- apache spark sql运行
- 跨库apache spark sql
- maxcompute apache spark sql
- apache spark SQL深入学习
- apache spark sql编程
- 任务编排apache spark sql
- apache spark sql hive
- emr apache spark sql
- apache spark sql cli
- apache spark sql运行大规模基因组工作流
- apache spark SQL程序设计
- apache spark sql jdbc server
apache spark您可能感兴趣
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark系统
- apache spark技术
- apache spark大数据
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark yarn
- apache spark操作
- apache spark程序
- apache spark报错
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注