
Spark Shuffle过程详细分析
在MapReduce中shuffle和Spark的shuffle的过程有一些区别。这里做一下具体的介绍。 Mapreduce的shuffle过程图解 Spark shuffle过程图解 注意:spark shuffle过程中没有分区和排序的过程,而且存储结果存储在内存中,所以速度要比mapreduce要快很多。 先就到这里吧,图解的说明应该比较清晰了。有问题欢迎留言 本文转自 Chin...
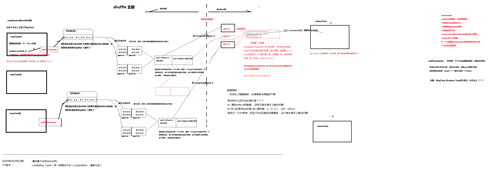
Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle。。。相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量。相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuffle过程进行了优化。 那么我们从RDD的iterator方法开始: 我们可以看到,它调用了cacheManager的getOrCompute方法,如果分区任务第一次执行还没有缓存....
Spark shuffle详细过程
有许多场景下,我们需要进行跨服务器的数据整合,比如两个表之间,通过Id进行join操作,你必须确保所有具有相同id的数据整合到相同的块文件中。那么我们先说一下mapreduce的shuffle过程。 Mapreduce的shuffle的计算过程是在executor中划分mapper与reducer。Spark的Shuffling中有两个重要的压缩参数。spark.shuffle.co...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark更多shuffle相关
- apache spark shuffle机制
- apache spark shuffle ess
- apache spark shuffle service
- apache spark remote shuffle
- apache spark核心shuffle
- apache spark shuffle调优
- apache spark shuffle write
- hadoop apache spark shuffle
- hadoop apache spark shuffle差异
- apache spark shuffle优化
- apache spark技术内幕shuffle
- hadoop apache spark shuffle过程
- apache spark based shuffle
- apache spark shuffle过程分析
- apache spark社区直播Shuffle优化
- apache spark sort shuffle
- apache spark shuffle模块
- apache spark技术内幕Shuffle详解
apache spark您可能感兴趣
- apache spark安装
- apache spark日志
- apache spark分析
- apache spark应用
- apache spark OSS
- apache spark机制
- apache spark缓存
- apache spark rdd
- apache spark湖仓
- apache spark lakehouse
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark操作
- apache spark技术
- apache spark yarn
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注