
Python 原生爬虫教程:京东商品详情页面数据API
一、引言在电商领域,商品信息的获取对于商家、开发者以及消费者都具有重要意义。对于商家来说,他们需要了解竞争对手的商品详情,以便优化自身的产品策略;开发者则希望通过调用商品详情 API 来构建电商相关的应用程序,如比价网站、商品推荐系统等;消费者在购物过程中,也期望能够快速准确地获取商品的详细信息。京...
Python 原生爬虫教程:京东商品列表页面数据API
一、引言在电商大数据分析和应用开发的场景中,获取商品信息是基础且关键的一环。京东作为国内知名的电商平台,拥有海量丰富的商品资源。京东商品列表 API 为开发者、商家以及数据研究人员提供了便捷获取京东平台商品数据的途径。通过调用该 API,能够获取到诸如商品名称、价格、销量、库存等多种维度的信息,这些数据可用于市场调研、竞品分析、个性化推荐系...
python爬虫示例,获取主页面链接,次级页面链接通过主页面元素获取从而避免js生成变动的值,保存数据分批次避免数据丢失
# -*- coding: utf-8 -*-# import scrapyimportpandasaspdfrommathimportceilimportreimportrequestsimportrefrombs4importBeautifulSoupfromopenpyxlimportWorkbookfromopenpyxlimportload_workbook# from cve_det....
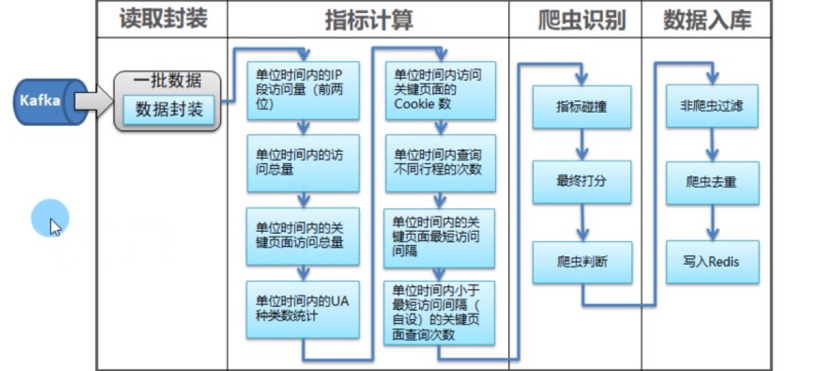
爬虫识别-关键页面数据读取|学习笔记
开发者学堂课程【大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop 框架搭建)第五阶段:爬虫识别-关键页面数据读取】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/673/detail/11691爬虫识别-关键页面数据读取 目录:一、指标计算二、需求三、设计四、代码&a...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注