
面向长文本的多模型协作摘要架构:多LLM文本摘要方法
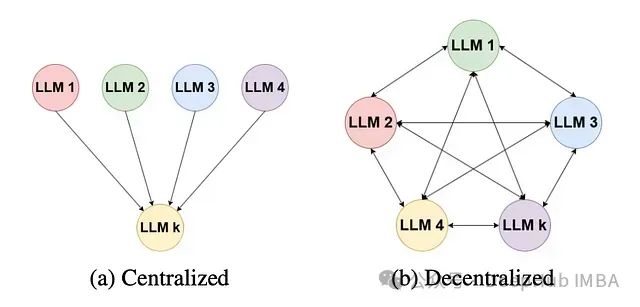
多LLM摘要框架在每轮对话中包含两个基本步骤:生成和评估。这些步骤在多LLM分散式摘要和集中式摘要中有所不同。在两种策略中,k个不同的LLM都会生成多样化的文本摘要。然而在评估阶段,多LLM集中式摘要方法使用单个LLM来评估摘要并选择最佳摘要,而分散式多LLM摘要则使用k个LLM进行评估。 论文提出的方法旨在处理长文本文档输入,这类文档可能包含数万字,通常超出大多数标准LLM的上下文窗口限制,.....
LVM-文本区域过滤组件说明
LVM-文本区域过滤(DLC)组件主要用于过滤文本过多的视频(仅支持处理MP4格式的视频)数据。该功能特别适用于视频编辑和内容审核场景,帮助用户自动识别并处理视频中包含过多文本的片段,从而提高工作效率。
MemLong: 基于记忆增强检索的长文本LLM生成方法
本文将介绍MemLong,这是一种创新的长文本语言模型生成方法。MemLong通过整合外部检索器来增强模型处理长上下文的能力,从而显著提升了大型语言模型(LLM)在长文本处理任务中的表现。 核心概念 MemLong的设计理念主要包括以下几点: 高效扩展LLM上下文窗口的轻量级方法。 利用不可训练的外部记忆库存储历史上下文和知识。 通过检索相关的块级键值(K-V)对来增强模型输入。 适用...
如何使用LLM智能问答版SDK进行文本向量化及切片向量化
配置环境变量配置环境变量ALIBABA_CLOUD_ACCESS_KEY_ID和ALIBABA_CLOUD_ACCESS_KEY_SECRET。ALIBABA_CLOUD_ACCESS_KEY_IDALIBABA_CLOUD_ACCESS_KEY_SECRET重要阿里云账号AccessKey拥有所有...
LLM-文本标准化组件说明
LLM-文本标准化(DLC)组件主要用于将文本Unicode标准化以及繁体转简体。输入的OSS数据文件(JSONL格式,示例)需符合:每一行是一个合法的JSON对象,文件由多行JSON对象组成,整个文件本身不是合法的JSON对象。
如何使用文本向量化模型服务
描述:只进行文本向量化描述请求语法POST /v3/openapi/apps/{app_group_identity}/actions/knowledge-embedding注:app_group_identity表示应用名称。注请求参数EmbeddingDoc参数名参数类型描述备注contentS...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。