
K-means聚类算法是机器学习中常用的一种聚类方法,通过将数据集划分为K个簇来简化数据结构
在机器学习领域,聚类分析是一种重要的探索性数据分析方法。K-means 聚类算法是其中一种常用的聚类算法,它简单高效,在许多实际应用中都有广泛的应用。本文将详细介绍 K-means 聚类算法的原理,并展示如何在 Python 中实现该算法。 一、K-means 聚类算法的原理 K-means 聚类算法的基本思想是将数据集划分为 K 个簇&#...
【Python机器学习】K-Means算法对人脸图像进行聚类实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~K-Mean算法,即 K 均值算法,是一种常见的聚类算法。算法会将数据集分为 K 个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”。算法步骤K-Means容易受初始质心的影响;算法简单,容易实现;算法聚类时,容易产生空簇;算法可能收敛到局部最小值。通过聚类可以实现:发现不同用户群体,从而可以实现精准营销;对文档进行划分;社交网络中,....

【python机器学习】K-Means算法详解及给坐标点聚类实战(附源码和数据集 超详细)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~人们在面对大量未知事物时,往往会采取分而治之的策略,即先将事物按照相似性分成多个组,然后按组对事物进行处理。机器学习里的聚类就是用来完成对事物进行分组的任务一、样本处理聚类算法是对样本集按相似性进行分簇,因此,聚类算法能够运行的前提是要有样本集以及能对样本之间的相似性进行比较的方法。样本的相似性差异也称为样本距离,相似性比较称为距离度量。设样本....
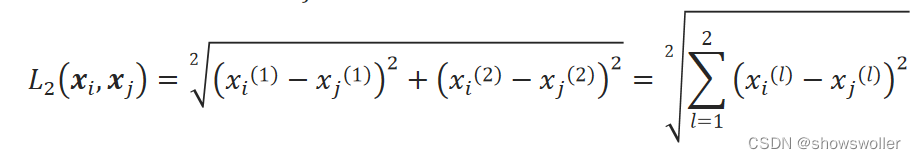
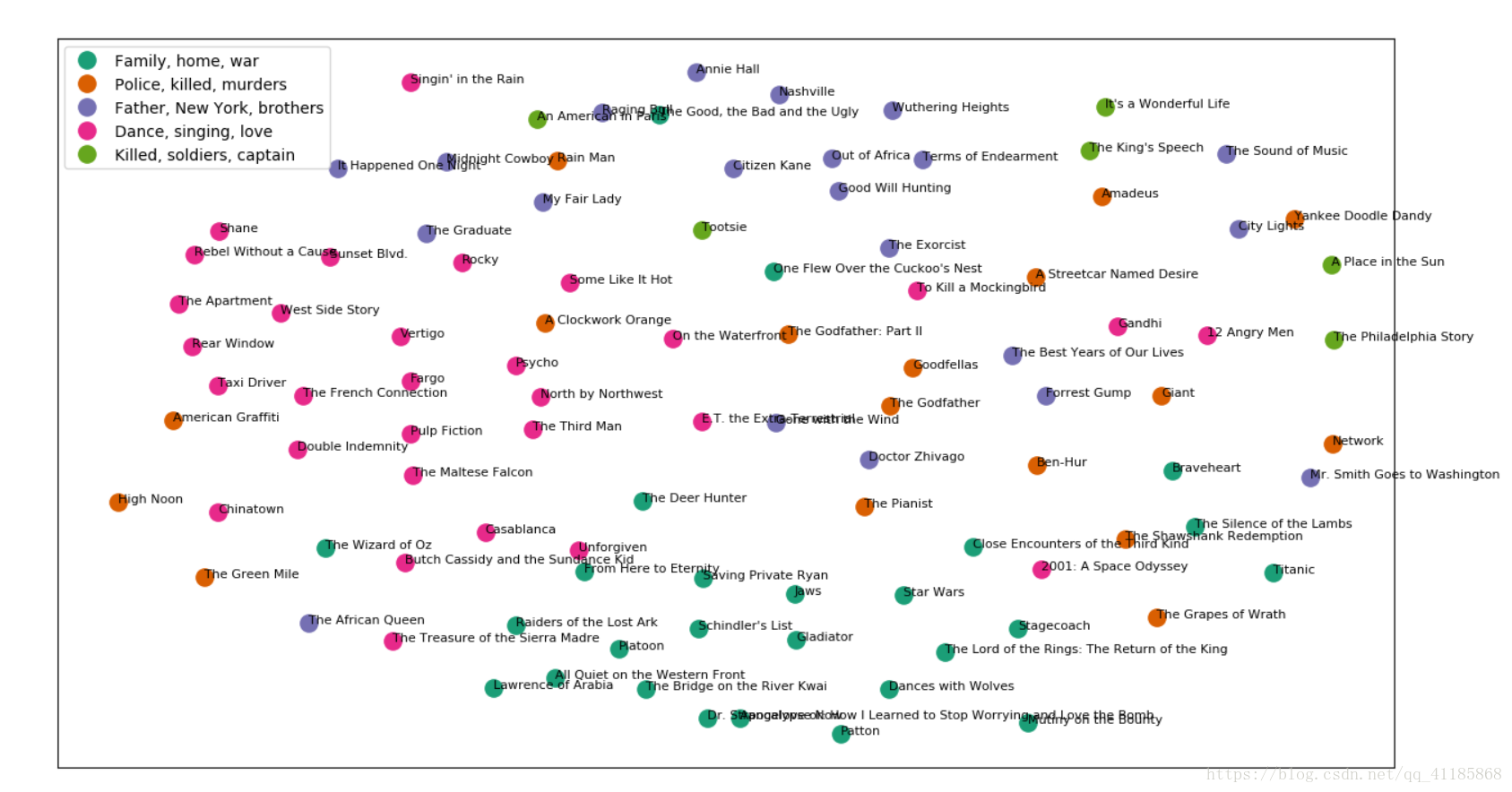
ML之K-means:基于K-means算法利用电影数据集实现对top 100 电影进行文档分类
输出结果实现代码# -*- coding: utf-8 -*-from __future__ import print_functionimport numpy as npimport pandas as pdimport nltkfrom bs4 import BeautifulSoupimport reimport osimport codecsfrom sklearn import fea....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法数据集相关内容
- 算法鸢尾花数据集
- svm算法数据集
- 聚类算法数据集
- 算法数据集源码
- 数据集算法
- 协同过滤算法数据集
- 目标检测算法数据集
- svm数据集算法
- 决策树算法数据集
- 算法iris数据集源码
- 算法决策树数据集
- knn算法数据集
- 数据挖掘算法数据集
- 数据挖掘算法数据集源码
- 决策算法数据集
- kmeans算法数据集
- 线性回归算法数据集
- 算法数据集训练
- 算法数据集验证
- 算法房价数据集
- 数据集apriori算法计算复杂度
- unet算法数据集格式
- ml nb算法数据集
- ml lor算法数据集
- lstm算法数据集
- dl算法数据集训练
- tf框架算法数据集
- dl框架算法数据集
- dl数据集算法回归预测
- ml lor算法数据集分类
算法更多数据集相关
- 算法kaggle数据集
- 算法影评数据集情感分析
- tensorflow框架算法数据集
- 算法数据集回归预测
- 自定义算法数据集
- 数据集算法回归预测
- dl数据集算法
- ml数据集算法
- ml lor数据集算法
- 数据集梯度下降算法
- ml xgboost算法数据集
- cnn算法数据集
- 算法mnist数据集
- 算法boston数据集
- 算法数据集二分类
- ml rf算法数据集
- 算法泰坦尼克数据集
- ml数据集knn算法
- ml回归预测算法数据集
- dl算法mnist数据集
- 算法数据集评估
- ml算法波士顿数据集
- ml算法boston房价数据集
- ml算法数据集回归预测
- 算法平台数据集
- rf算法泰坦尼克号数据集分类
- nb数据集朴素贝叶斯算法
- 算法数据集kaggle
- iris莺尾花数据集算法
- 算法mnist数据集训练

智能引擎技术
AI Online Serving,阿里巴巴集团搜推广算法与工程技术的大本营,大数据深度学习时代的创新主场。
+关注