基础大模型 vs 应用大模型
基础大模型:定义:基础大模型(如GPT-3、BERT、T5等)是通过大量通用数据集训练得到的预训练模型。这些模型通常具有很强的泛化能力,可以在多种任务上表现出色。训练数据:基础大模型的训练数据通常来自互联网、书籍、新闻、维基百科等多种来源,包含了大量的文本数据。特点:基础大模型通常具有...

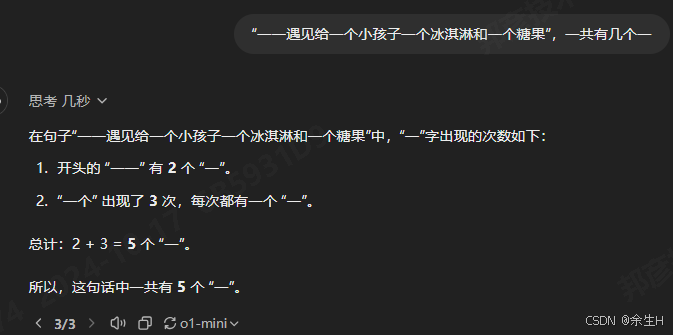
前端大模型应用笔记(五):大模型基础能力大比拼-计数篇-通义千文 vs 文心一言 vs 智谱 vs 讯飞vsGPT
在大语言模型(LLM)不断涌现的时代,如何评估这些国产大模型的逻辑推理能力,尤其是在处理基础计数问题上的表现,成为了一个备受关注的话题。随着越来越多的国产大模型进入市场,比较它们在不同任务中的表现尤为重要。本文聚焦于计数这一基础能力,对通义千文、文心一言、智谱以及讯飞的多个版本进行了对比测试,探索它们在处理简单逻辑题时的表现,并特别考察了推理链(Chain-of-Thought,COT)方法的必....
通用大模型VS垂直大模型
在人工智能领域,关于通用大模型VS垂直大模型,在选择上我并不倾向于任何一方,而是会根据实际的场景来选择具体的大模型。 通用大模型 通用大模型是指那些设计用来处理多种任务和数据类型的大型人工智能模型。它们通常在大规模的多领域数据集上进行训练,以学习到广泛的知识和技能,从而具备跨领域的泛化能力。通用大模型通常参数量巨大,在百万到数十亿级别,这使得它们能够捕捉和学习数据中的复杂模式和细...
通用大模型VS垂直大模型对比
通用大模型和垂直大模型的区分主要在于它们的设计目的、应用范围、训练数据、优化目标和使用场景。以下是一些关键点,用以区分这两种模型: 设计目的: 通用大模型:设计用于处理多种类型的任务,不特定于某一领域。 垂直大模型:专为某一特定领域或任务设计,以满足该领域的特定需求。 ...
通用大模型VS垂直大模型,你倾向于哪一方?
在当今人工智能领域,通用大模型与垂直大模型的交锋无疑是技术前沿的一大焦点。一方是拥有广阔适用范围、能够跨领域理解与生成的通用大模型,另一方则是深耕特定行业、提供专业精度的垂直大模型。面对不同应用场景的个性化需求与规模化效率的双重考量,你更倾向于哪一方,来开辟AI技术应用的新天地呢?结合真实经历谈谈你的看法~ 本期奖品:截止2024年7月23日24时,参与本期话题讨论,将会选出 4 个优质回答获得....
《百炼成金-大金融模型新篇章》––05.问题3:“大模型vs越来越大的模型”,模型sIzE的军备竞赛
本文来源于阿里云社区电子书《百炼成金-大金融模型新篇章》 问题 3: “大模型 vs 越来越大的模型”,模型 size 的军备竞赛 OpenAI 的研究者在 2020 年发现,大语言模型也遵循着规模定律(ScalingLaw),模型参数数量的增加常常被看作是提高模型性能的一个关键因素。这导致了一种被业界戏称为“模型参数的军备竞赛”的现象,即科研机构和科技公司不...
《百炼成金-大金融模型新篇章》––07.问题5:“杀手级通用大模型vs百花齐放专属大模型”,企业级AI应用的价值自证?
本文来源于阿里云社区电子书《百炼成金-大金融模型新篇章》 问题 5: “杀手级通用大模型 vs 百花齐放专属大模型”,企业级 AI 应用的价值自证? 企业在利用大模型进行业务升级改造时,选择使用一个杀手级通用大模型,还是百花齐放的专属大模型,取决于您具体的业务需求、战略目标和资源限制。无论选择哪种模式,都会面临挑战和价值自证。 杀手级通用大模...
《百炼成金-大金融模型新篇章》––08.问题6:“大模型广泛应用vs应用安全隐患”,大模型面临的安全挑战
本文来源于阿里云社区电子书《百炼成金-大金融模型新篇章》 问题 6: “大模型广泛应用 vs 应用安全隐患”,大模型面临的安全挑战 随着大模型深入应用,一些因大模型关联引发的安全问题让大家重视起来,如大规模数据采集和应用带来的个人隐私泄露和滥用的问题,大模型生成内容可能带有的偏见歧视、违法违规、科技伦理类问题,以及利用大模型强大能力用于欺诈等恶意应用场景的问题...
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL] Text-to-SQL(或者Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,NL)问题,转化为在关系型数据库中可以执行的结构化询语言(Structu.....
![NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]](https://ucc.alicdn.com/fnj5anauszhew_20240410_230ba39d3fa54e0cac91da7f7a3e06b5.jpeg)
深夜测评:讯飞星火大模型vs FuncGPT (慧函数),到底哪家强?
作为一名程序员,我们可能在多种情况下需要找出两个List中的重复元素。以下是一些常见的应用场景: 数据清理:如果你有两个来自不同源的列表,可能含有重复数据,找出这些重复元素可以帮助你清理数据,提高数据的准确性和质量。 数据合并:当你需要将两个列表合并成一个时,找出并处理重复元素是必要的...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
