
在Scrapy爬虫中应用Crawlera进行反爬虫策略
在互联网时代,数据成为了企业竞争的关键资源。然而,许多网站为了保护自身数据,会采取各种反爬虫技术来阻止爬虫的访问。Scrapy作为一个强大的爬虫框架,虽然能够高效地抓取网页数据,但在面对复杂的反爬虫机制时,仍然需要额外的工具来增强其反爬能力。Crawlera就是这样一款能够协助Scrapy提升反爬能力的工具。什么...
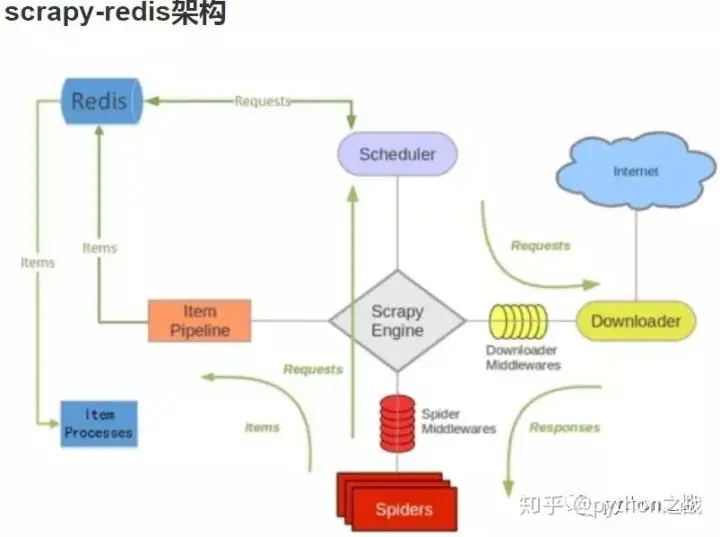
scrapy框架通用爬虫、深度爬虫、分布式爬虫、分布式深度爬虫,源码解析及应用
scrapy框架是爬虫界最为强大的框架,没有之一,它的强大在于它的高可扩展性和低耦合,使使用者能够轻松的实现更改和补充。 其中内置三种爬虫主程序模板,scrapy.Spider、RedisSpider、CrawlSpider、RedisCrawlSpider(深度分布式爬虫)分别为别为一般爬虫、分布式爬虫、深度爬虫提供内部逻辑;下面将从源码和应用来学习, scrapy.Spider 源码: ""....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
爬虫scrapy相关内容
- scrapy框架爬虫
- scrapy爬虫策略
- 爬虫框架scrapy
- 爬虫scrapy框架
- 爬虫scrapy数据
- scrapy爬虫自定义
- 爬虫开发scrapy
- 爬虫scrapy入门
- 爬虫scrapy爬取
- scrapy爬虫爬取数据
- scrapy爬虫数据
- scrapy爬虫爬取
- 配置scrapy爬虫
- 爬虫库scrapy
- 爬虫scrapy豆瓣
- 爬虫scrapy xpath
- 爬虫scrapy安装
- 爬虫scrapy框架爬取
- 爬虫scrapy管理工具
- 爬虫scrapy工具
- 爬虫scrapy功能
- 爬虫scrapy代理
- 爬虫scrapy爬虫框架
- 爬虫scrapy框架安装
- scrapy爬虫项目
- scrapy爬虫调试
- scrapy爬虫教程
- scrapy爬虫实例
- scrapy爬虫报错
- scrapy爬虫不报错
爬虫更多scrapy相关
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注