
数据湖技术:Hadoop与Spark在大数据处理中的协同作用
数据湖技术:Hadoop与Spark在大数据处理中的协同作用 在大数据时代,数据湖技术以其灵活性和成本效益成为了企业存储和分析大规模异构数据的首选。Hadoop和Spark作为数据湖技术中的两个核心组件,它们在大数据处理中的协同作用至关重要。本文将探讨Hadoop与Spark的最佳实践,以及如何在实际应用中发挥它们的协同效应。 Hadoop...
数据湖技术:Hadoop与Spark在大数据处理中的协同作用
随着大数据技术的不断发展,数据湖作为一种集中式存储和处理海量数据的架构,越来越受到企业的青睐。Hadoop和Spark作为数据湖技术的两大核心组件,在大数据处理中发挥着不可替代的作用。本文将通过最佳实践的形式,详细探讨Hadoop与Spark在大数据处理中的协同作用,并提供具体的示例代码。 Hadoop,作为一个...
Hudi数据湖技术引领大数据新风口(三)解决spark模块依赖冲突
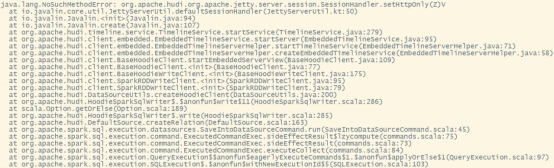
解决spark模块依赖冲突修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。1)修改hudi-spark-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty:vim /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml在382行的位置,修改如....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark系统
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark任务
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark yarn
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注