
基于Delta Table构建近实时增全量一体化链路实践
面对当前日益复杂且对数据时效性要求极高的近实时业务场景,MaxCompute基于Delta Table推出了集大规模存储、高效批量处理和近实时能力于一体的近实时增量一体化架构。本文为您介绍该架构的工作原理及其优势。
高并发近实时增量写入场景的架构设计的基本概念
数据流入Delta Table主要存在近实时增量写入和批量写入两种场景,本文为您介绍高并发近实时增量写入场景的架构设计。
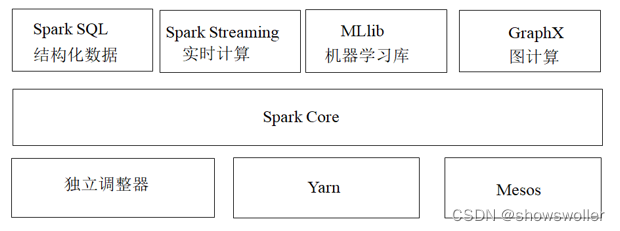
大数据-105 Spark GraphX 基本概述 与 架构基础 概念详解 核心数据结构
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-98 Spark 集群 Spark Streaming 基础概述 架构概念 执行流程 优缺点
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-93 Spark 集群 Spark SQL 概述 基本概念 SparkSQL对比 架构 抽象
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-82 Spark 集群模式启动、集群架构、集群管理器 Spark的HelloWorld + Hadoop + HDFS
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-80 Spark 简要概述 系统架构 部署模式 与Hadoop MapReduce对比
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
架构大数据相关内容
- 大数据架构故障
- 赵渝强大数据架构
- 架构阿里巴巴大数据
- 大数据apache架构
- 大数据druid架构
- 大数据架构索引
- 大数据单机架构
- 大数据概述架构
- 大数据spark概述架构
- 大数据架构流程
- 大数据基本概念架构
- 大数据架构hdfs
- 大数据架构hadoop
- 大数据架构应用场景
- 大数据kafka架构
- 开源大数据引擎架构
- 大数据架构云上
- 大数据引擎架构
- 大数据hadoop架构
- 斗鱼大数据架构
- 大数据架构扩展
- 大数据kappa架构
- 大数据架构实施
- 大数据架构角色
- 数据仓库大数据架构
- 大数据架构最佳实践
- 大数据maxcompute架构
- 大数据hadoop hive架构
- 大数据架构优缺点
- spark大数据架构
架构更多大数据相关
- 大数据平台cdp架构大数据发展趋势
- 大数据分布式文件系统架构
- 大数据数据采集架构
- 大数据架构apache
- 大数据架构目录
- 数据湖大数据lambda架构
- 大数据日志分析架构
- 大数据hbase架构
- 大数据仓库架构
- tablestore大数据架构
- 架构企业大数据大数据
- 大数据数据分析架构
- 大数据风控架构
- 峰会大数据架构
- lambda大数据架构
- maxcompute大数据架构
- 大数据引擎greenplum架构
- 大数据导论架构
- 大数据数据分析架构探究
- teradata大数据架构
- 大数据架构数据平台
- 大数据电商系统架构
- 大数据hdfs hbase架构
- 大数据分布式计算架构
- 阿里巴巴大数据架构
- 大数据架构storm

金融级分布式架构
SOFAStack™(Scalable Open Financial Architecture Stack)是一套用于快速构建金融级分布式架构的中间件,也是在金融场景里锤炼出来的最佳实践。
+关注