
在EMR Serverless Spark中实现HBase读写操作
基于HBase官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接HBase。本文为您介绍在EMR Serverless Spark环境中实现HBase的数据读取和写入操作。
在EMR Serverless Spark中实现MongoDB读写操作
基于MongoDB官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接MongoDB。本文为您介绍在EMR Serverless Spark环境中实现MongoDB的数据读取和写入操作。
用户画像分析案例同步数据-基于新版数据开发和Spark计算资源
本文将介绍如何创建HttpFile和MySQL数据源以访问用户信息和网站日志数据,配置数据同步链路将这些数据同步到在环境准备阶段创建的OSS存储中,并通过创建Spark外表解析OSS中存储的数据。通过查询验证数据同步结果,确认是否完成整个数据同步操作。
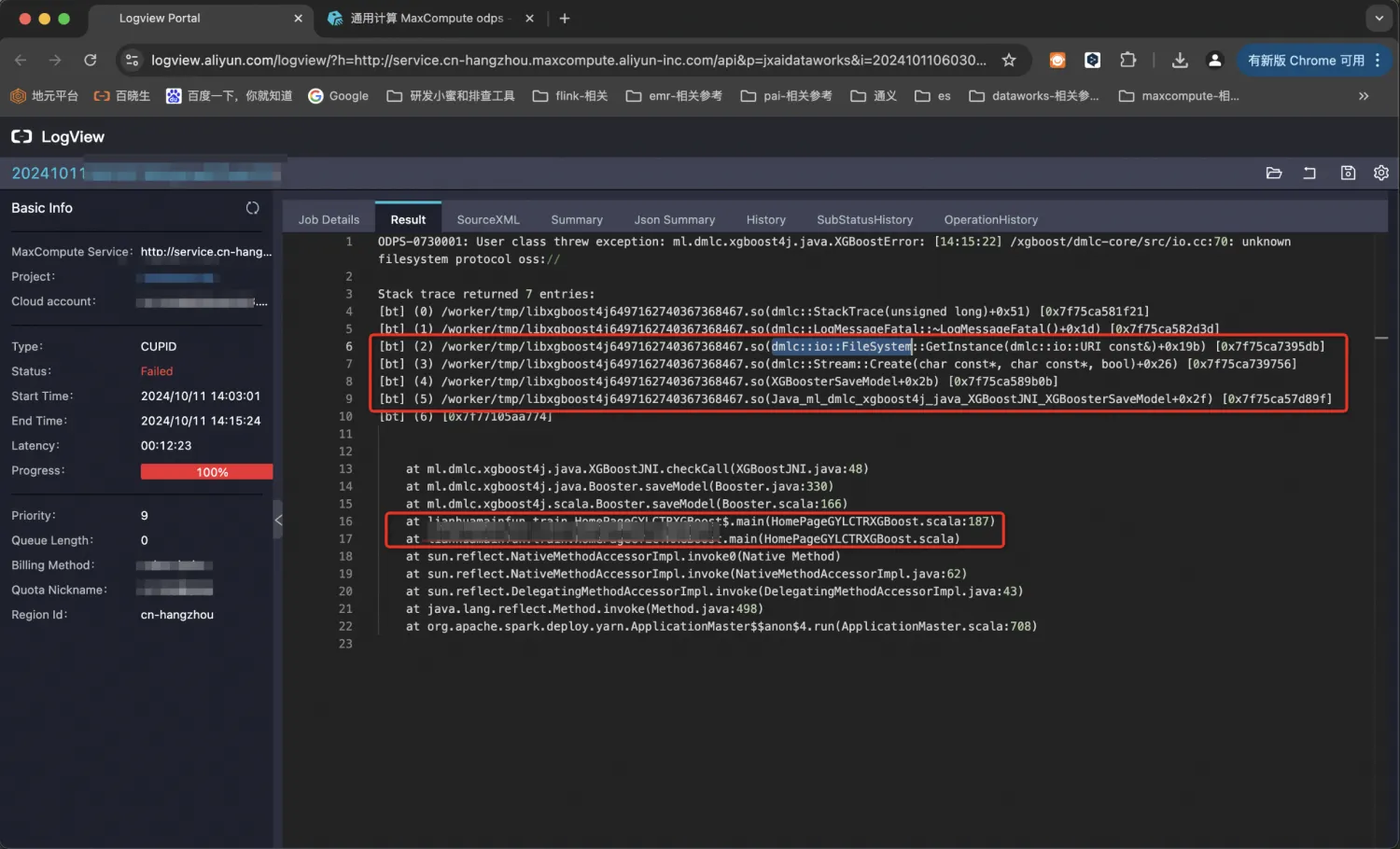
阿里云MaxCompute-XGBoost on Spark 极限梯度提升算法的分布式训练与模型持久化oss的实现与代码浅析
1. XGBoost简介 XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。它在GBDT框架的基础上实现机器学习算法。XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。XGBoost最初是一个研究项目,孵化于Distributed (Deep) Machine Learning Community (DMLC) ,由陈天奇博...
大数据-83 Spark 集群 RDD编程简介 RDD特点 Spark编程模型介绍
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

【大数据技术Hadoop+Spark】HBase数据模型、Shell操作、Java API示例程序讲解(附源码 超详细)
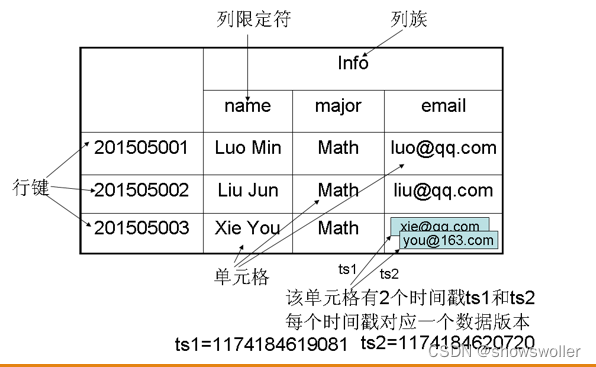
一、HBase数据模型HBase分布式数据库的数据存储在行列式的表格中,它是一个多维度的映射模型,其数据模型如下所示。表的索引是行键,列族,列限定符和时间戳,表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,列族支持动态扩展,可以很轻松的添加一个列族或者列,无须预先定义列的数量及数据类型,所有列均以字符串形式存储RowKey表示行键,每个HBase表中只能有一个行键,它在HBas....
【大数据技术Hadoop+Spark】Hive数据仓库架构、优缺点、数据模型介绍(图文解释 超详细)
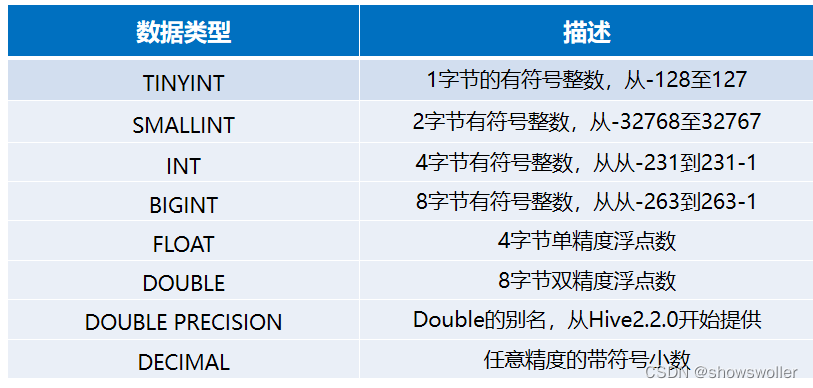
一、Hive简介Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook开发团队想设计一种使用SQL语言对日志数据查询分析的工具,而Hive就诞生于此,只要懂SQL语言,....
【大数据技术Hadoop+Spark】MapReduce概要、思想、编程模型组件、工作原理详解(超详细)
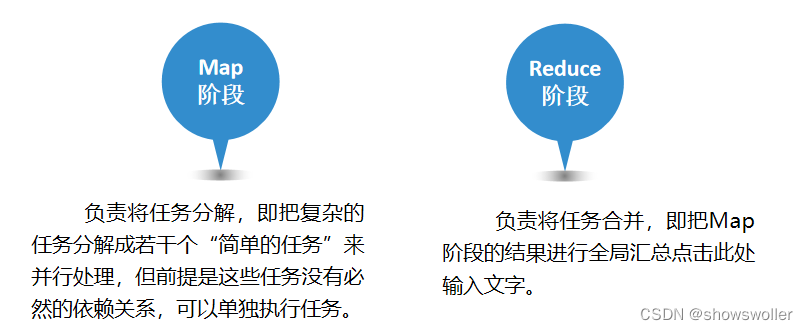
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。一、MapReduce核心思想MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxComputespark相关内容
- 云原生大数据计算服务 MaxCompute spark hbase
- spark云原生大数据计算服务 MaxCompute
- 开源spark云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark代码
- 云原生大数据计算服务 MaxCompute spark graphx
- 云原生大数据计算服务 MaxCompute spark redis
- 云原生大数据计算服务 MaxCompute spark学习
- 云原生大数据计算服务 MaxCompute spark scala
- 云原生大数据计算服务 MaxCompute spark计算
- 云原生大数据计算服务 MaxCompute spark案例
- 云原生大数据计算服务 MaxCompute spark集群文件
- 云原生大数据计算服务 MaxCompute spark dstream
- 云原生大数据计算服务 MaxCompute spark优缺点
- 云原生大数据计算服务 MaxCompute spark集群
- 云原生大数据计算服务 MaxCompute spark集群scala
- 云原生大数据计算服务 MaxCompute spark自定义
- 云原生大数据计算服务 MaxCompute spark streaming dstream
- 云原生大数据计算服务 MaxCompute spark数据源
- 云原生大数据计算服务 MaxCompute spark文件
- 云原生大数据计算服务 MaxCompute spark集群案例
- 云原生大数据计算服务 MaxCompute spark dataset
- 云原生大数据计算服务 MaxCompute spark优化
- 云原生大数据计算服务 MaxCompute spark rdd持久化
- 云原生大数据计算服务 MaxCompute spark容错机制
- 云原生大数据计算服务 MaxCompute spark依赖
- 云原生大数据计算服务 MaxCompute spark wordcount
- 云原生大数据计算服务 MaxCompute spark集群模式
- 云原生大数据计算服务 MaxCompute spark编译
- 云原生大数据计算服务 MaxCompute spark hdfs
- 云原生大数据计算服务 MaxCompute spark安装配置
云原生大数据计算服务 MaxCompute更多spark相关
- 云原生大数据计算服务 MaxCompute spark环境配置
- 云原生大数据计算服务 MaxCompute spark环境
- 云原生大数据计算服务 MaxCompute spark部署模式
- dataworks spark节点云原生大数据计算服务 MaxCompute
- spark访问云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark访问
- 云原生大数据计算服务 MaxCompute spark节点
- 云原生大数据计算服务 MaxCompute spark性能
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute spark standalone模式
- 云原生大数据计算服务 MaxCompute spark资源
- 云原生大数据计算服务 MaxCompute spark模式
- 云原生大数据计算服务 MaxCompute框架spark
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute spark运行
- 云原生大数据计算服务 MaxCompute spark实战
- 云原生大数据计算服务 MaxCompute spark sql
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute spark引擎
- 云原生大数据计算服务 MaxCompute hive spark
- 云原生大数据计算服务 MaxCompute学习spark
- 云原生大数据计算服务 MaxCompute spark访问oss
- 云原生大数据计算服务 MaxCompute spark概念
- 云原生大数据计算服务 MaxCompute spark mc
- 云原生大数据计算服务 MaxCompute spark实战源码
- 云原生大数据计算服务 MaxCompute引擎spark
- 云原生大数据计算服务 MaxCompute spark dataframe
- 数据计算云原生大数据计算服务 MaxCompute spark节点
- spark云原生大数据计算服务 MaxCompute引擎
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute ai
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute点燃
- 云原生大数据计算服务 MaxCompute智能电商
- 云原生大数据计算服务 MaxCompute购物
- 云原生大数据计算服务 MaxCompute算法
- 云原生大数据计算服务 MaxCompute脏数据
- 云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute潜能
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注