
大数据Spark Standalone集群 2
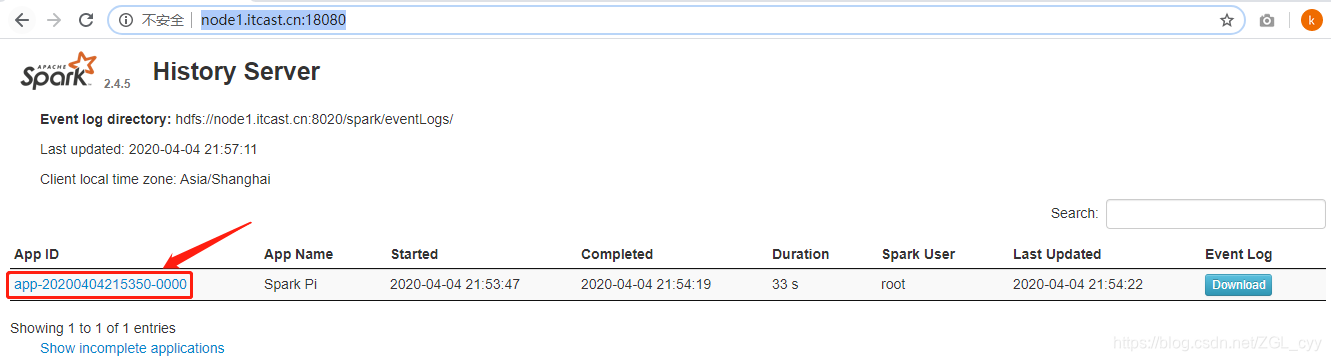
3 Spark 应用架构登录到Spark HistoryServer历史服务器WEB UI界面,点击刚刚运行圆周率PI程序:查看应用运行状况:切换到【Executors】Tab页面:从图中可以看到Spark Application运行到集群上时,由两部分组成:Driver Program和Executors。第一、Driver Program相当于AppMaster,整个应用管理者,负责应用中所....
大数据Spark Standalone集群 1
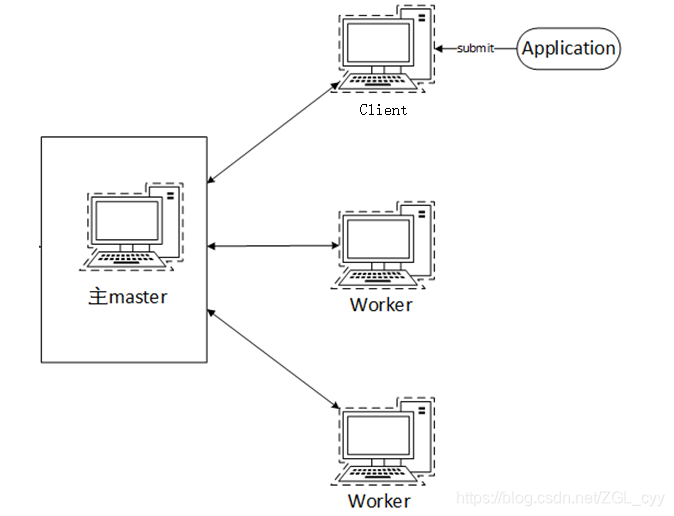
1 Standalone 架构Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭 建多机器集群,用于实际的大数据处理。Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集....
大数据分享Spark任务和集群启动流程
大数据分享Spark任务和集群启动流程 大数据分享Spark任务和集群启动流程,Spark集群启动流程1.调用start-all.sh脚本,开始启动Master2.Master启动以后,preStart方法调用了一个定时器,定时检查超时的Worker后删除3.启动脚本会解析slaves配置文件,找到启动Worker的相应节点.开始启动Worker4.Worker服务启动后开始调用preStart....
Hadoop大数据平台实战(05):深入Spark Cluster集群模式YARN vs Mesos vs Standalone vs K8s
Spark可以以分布式集群架构模式运行,如果我们不熟Spark Cluster,这个时候需要集群管理器帮助我们管理Spark 集群。 集群管理器根据需要为所有工作节点提供资源,操作所有节点。负责管理和协调集群节点的程序一般叫做:Cluster Manager,集群管理器。目前搭建Spark 集群,可以的选择包括Standalone,YARN,Mesos,K8s,这么多工具,在部署Spark集群时....
《Spark与Hadoop大数据分析》——2.4 安装 Hadoop 和 Spark 集群
2.4 安装 Hadoop 和 Spark 集群 在安装 Hadoop和Spark之前,让我们来了解一下 Hadoop和Spark的版本。在 Cloudera、Hortonworks和MapR这所有三种流行的Hadoop发行版中,Spark都是作为服务提供的。在本书编写的时候,最新的Hadoop和Spark版本分别是2.7.2和2.0。但是,Hadoop发行版里可能是一个较低版本的Spark,这....
《Spark大数据处理:技术、应用与性能优化》——2.2 Spark集群初试
本节书摘来自华章计算机《Spark大数据处理:技术、应用与性能优化》一书中的第2章,第2.2节,作者:高彦杰 更多章节内容可以访问云栖社区“华章计算机”公众号查看。 2.2 Spark集群初试 假设已经按照上述步骤配置完成Spark集群,可以通过两种方式运行Spark中的样例。下面以Spark项目中的SparkPi为例,可以用以下方式执行样例。1)以./run-example的方式执行用户可以按....
《Spark大数据处理:技术、应用与性能优化》——第2章 Spark集群的安装与部署2.1 Spark的安装与部署
本节书摘来自华章计算机《Spark大数据处理:技术、应用与性能优化》一书中的第2章,第2.1节,作者:高彦杰 更多章节内容可以访问云栖社区“华章计算机”公众号查看。 第2章 Spark集群的安装与部署 Spark的安装简便,用户可以在官网上下载到最新的软件包。Spark最早是为了在Linux平台上使用而开发的,在生产环境中也是部署在Linux平台上,但是Spark在UNIX、Windwos和Ma....
《Spark与Hadoop大数据分析》一一2.4 安装 Hadoop 和 Spark 集群
本节书摘来自华章计算机《Spark与Hadoop大数据分析》一书中的第2章,第2.4节,作者:文卡特·安卡姆(Venkat Ankam) 更多章节内容可以访问云栖社区“华章计算机”公众号查看。 2.4 安装 Hadoop 和 Spark 集群 在安装 Hadoop和Spark之前,让我们来了解一下 Hadoop和Spark的版本。在 Cloudera、Hortonworks和MapR这所有三种流....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxComputespark相关内容
- 云原生大数据计算服务 MaxCompute spark hbase
- spark云原生大数据计算服务 MaxCompute
- 开源spark云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark模型
- 云原生大数据计算服务 MaxCompute spark代码
- 云原生大数据计算服务 MaxCompute spark graphx
- 云原生大数据计算服务 MaxCompute spark redis
- 云原生大数据计算服务 MaxCompute spark学习
- 云原生大数据计算服务 MaxCompute spark scala
- 云原生大数据计算服务 MaxCompute spark计算
- 云原生大数据计算服务 MaxCompute spark案例
- 云原生大数据计算服务 MaxCompute spark集群文件
- 云原生大数据计算服务 MaxCompute spark dstream
- 云原生大数据计算服务 MaxCompute spark优缺点
- 云原生大数据计算服务 MaxCompute spark集群scala
- 云原生大数据计算服务 MaxCompute spark自定义
- 云原生大数据计算服务 MaxCompute spark streaming dstream
- 云原生大数据计算服务 MaxCompute spark数据源
- 云原生大数据计算服务 MaxCompute spark文件
- 云原生大数据计算服务 MaxCompute spark集群案例
- 云原生大数据计算服务 MaxCompute spark dataset
- 云原生大数据计算服务 MaxCompute spark优化
- 云原生大数据计算服务 MaxCompute spark rdd持久化
- 云原生大数据计算服务 MaxCompute spark容错机制
- 云原生大数据计算服务 MaxCompute spark依赖
- 云原生大数据计算服务 MaxCompute spark wordcount
- 云原生大数据计算服务 MaxCompute spark集群模式
- 云原生大数据计算服务 MaxCompute spark编译
- 云原生大数据计算服务 MaxCompute spark hdfs
- 云原生大数据计算服务 MaxCompute spark安装配置
云原生大数据计算服务 MaxCompute更多spark相关
- 云原生大数据计算服务 MaxCompute spark环境配置
- 云原生大数据计算服务 MaxCompute spark环境
- 云原生大数据计算服务 MaxCompute spark部署模式
- dataworks spark节点云原生大数据计算服务 MaxCompute
- spark访问云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark访问
- 云原生大数据计算服务 MaxCompute spark节点
- 云原生大数据计算服务 MaxCompute spark性能
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute spark standalone模式
- 云原生大数据计算服务 MaxCompute spark资源
- 云原生大数据计算服务 MaxCompute spark模式
- 云原生大数据计算服务 MaxCompute框架spark
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute spark运行
- 云原生大数据计算服务 MaxCompute spark实战
- 云原生大数据计算服务 MaxCompute spark sql
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute spark引擎
- 云原生大数据计算服务 MaxCompute hive spark
- 云原生大数据计算服务 MaxCompute学习spark
- 云原生大数据计算服务 MaxCompute spark访问oss
- 云原生大数据计算服务 MaxCompute spark概念
- 云原生大数据计算服务 MaxCompute spark mc
- 云原生大数据计算服务 MaxCompute spark实战源码
- 云原生大数据计算服务 MaxCompute引擎spark
- 云原生大数据计算服务 MaxCompute spark dataframe
- 数据计算云原生大数据计算服务 MaxCompute spark节点
- spark云原生大数据计算服务 MaxCompute引擎
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute交通
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute流量
- 云原生大数据计算服务 MaxCompute聚簇
- 云原生大数据计算服务 MaxCompute pb
- 云原生大数据计算服务 MaxCompute shuffle
- 云原生大数据计算服务 MaxCompute cu
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute功能
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute分区
- 云原生大数据计算服务 MaxCompute项目

