
在EMR Serverless Spark中实现HBase读写操作
基于HBase官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接HBase。本文为您介绍在EMR Serverless Spark环境中实现HBase的数据读取和写入操作。
在EMR Serverless Spark中实现MongoDB读写操作
基于MongoDB官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接MongoDB。本文为您介绍在EMR Serverless Spark环境中实现MongoDB的数据读取和写入操作。
在EMR Serverless Spark中实现Doris读写操作
基于Apache Doris官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接Doris。本文为您介绍在EMR Serverless Spark环境中实现Doris的数据读取和写入操作。
在EMR Serverless Spark中实现StarRocks读写操作
StarRocks官方提供了Spark Connector用于Spark和StarRocks之间的数据读写,Serverless Spark可以在开发时添加对应的配置连接StarRocks。本文为您介绍在EMR Serverless Spark中实现StarRocks的读取和写入操作。
读写MaxCompute数据
在PAI子产品(DLC或DSW)中,您可以通过阿里云MaxCompute提供的PyODPS或人工智能平台PAI自主研发的paiio,实现MaxCompute数据的读写操作。针对不同的应用场景,您可以选择合适的MaxCompute数据读取方式。
模拟IDC spark读写MaxCompute实践
一、背景1、背景信息 现有湖仓一体架构是以 MaxCompute 为中心读写 Hadoop 集群数据,有些线下 IDC 场景,客户不愿意对公网暴露集群内部信息,需要从 Hadoop 集群发起访问云上的数据。本文以 EMR (云上 Hadoop)方式模拟本地 Hadoop 集群访问 MaxCompute数据。2、基本架构二、搭建开发环境1、EM....
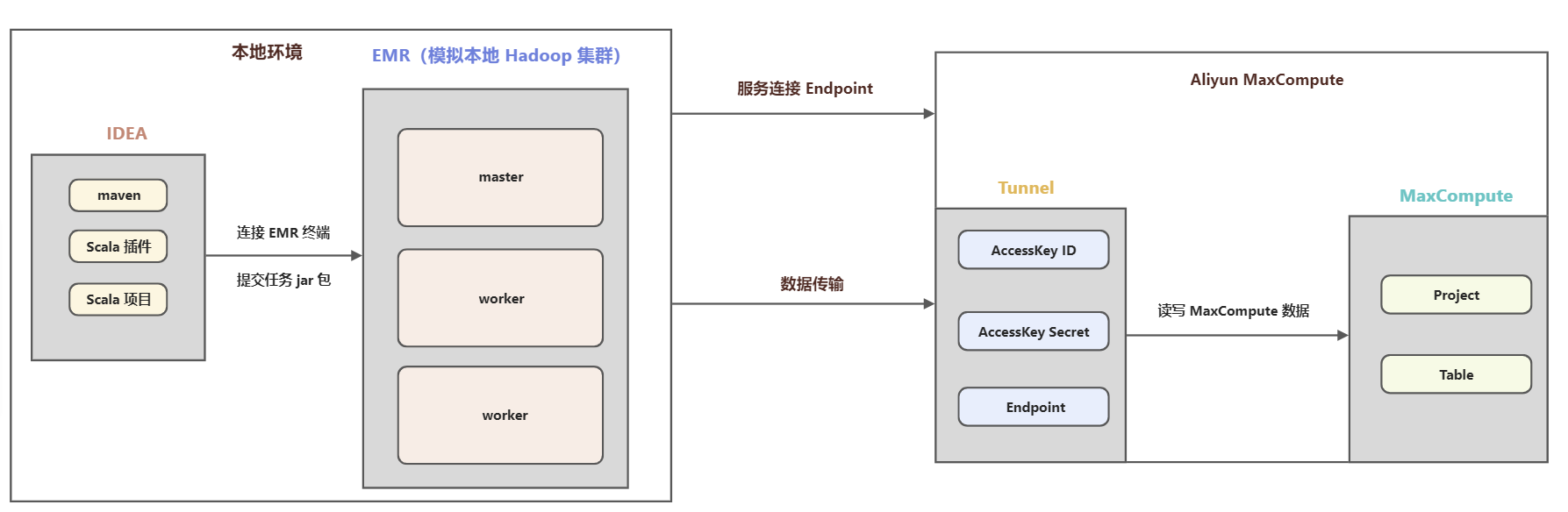
E-MapReduce中Spark 2.x读写MaxCompute数据
最新的aliyun-emapreduce-sdk将MaxCompute数据以DataSource的方式接入Spark 2.x,用户可以使用类似Spark 2.x中读写json/parquet/csv的方式来访问MaxCompute. 0. DataSource a) DataSource提供了一种插件式的外部数据接入SparkSQL的方式,数据源只要实现相应的DataSource API即可以整....
读写MaxCompute时,抛出java.lang.RuntimeException.Parse r
读写MaxCompute时,抛出java.lang.RuntimeException.Parse response failed: ‘…’?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute决策
- 云原生大数据计算服务 MaxCompute契机
- 云原生大数据计算服务 MaxCompute企业
- 云原生大数据计算服务 MaxCompute版本
- 云原生大数据计算服务 MaxCompute挖掘
- 云原生大数据计算服务 MaxCompute机器学习
- 云原生大数据计算服务 MaxCompute方法论
- 云原生大数据计算服务 MaxCompute项目
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute脚本
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注