
商汤、清华、复旦等开源百亿级多模态数据集,可训练类GPT-4o模型
近日,商汤科技、清华大学、复旦大学等机构联合开源了一个名为OmniCorpus的多模态数据集,其规模达到了惊人的百亿级。这一数据集的发布,有望为训练类似GPT-4级别的大型多模态模型提供有力支持。 OmniCorpus数据集由多个图像和文本组成,以自然文档的形式排列,这种图像-文本交错的数据形式与互联网数据的呈现方式相一致&#...
魔搭上新啦! 智源千万级指令微调数据集Infinity-Instruct,Llama3.1仅微调即可接近GPT-4
指令微调是引导语言模型落地、构建高性能对话模型的关键一步。针对目前开源的指令数据集质量低、覆盖领域少、数据信息不透明等问题,智源研究院在今年6月推出了千万级指令微调数据集Infinity Instruct。Infinity Instruct在 Huggingface等平台发布后,快速到达了Huggingface Dataset的Trending第一,且吸引大量基于Infinity Instruc....

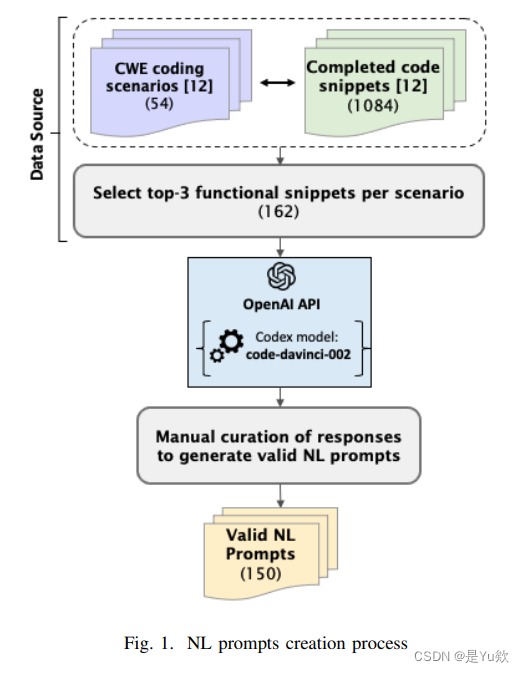
22LLMSecEval数据集及其在评估大模型代码安全中的应用:GPT3和Codex根据LLMSecEval的提示生成代码和代码补全,CodeQL进行安全评估【网安AIGC专题11.22】
写在最前面本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。李元鸿同学分享了LLMSecEval: A Dataset of Natural Language Prompts for Security Evaluations《LLMSecEval:用于评估大模型代码安全的自然语言提示数据集》分享时的PPT简洁大方,重点突出LLMSecEval数据集及其在评估大型语言模型....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。