
GPU通信互联技术:GPUDirect、NVLink与RDMA
在高性能计算和深度学习领域,GPU的强大计算能力已成为不可或缺的工具。然而,随着模型复杂度和数据量的增加,单个GPU已无法满足需求,多个GPU甚至多台服务器协同工作成为常态。这就要求高效的GPU互联通信技术,以确保数据传输的高带宽和低延迟。本文将详细探讨三种主要的GPU通信互联技术:GPUDirect、NVLink和RDMA。 目录 一、GPUDirect技术 1. 什么...
带你读《弹性计算技术指导及场景应用》——2. 技术改变AI发展:RDMA能优化吗?GDR性能提升方案
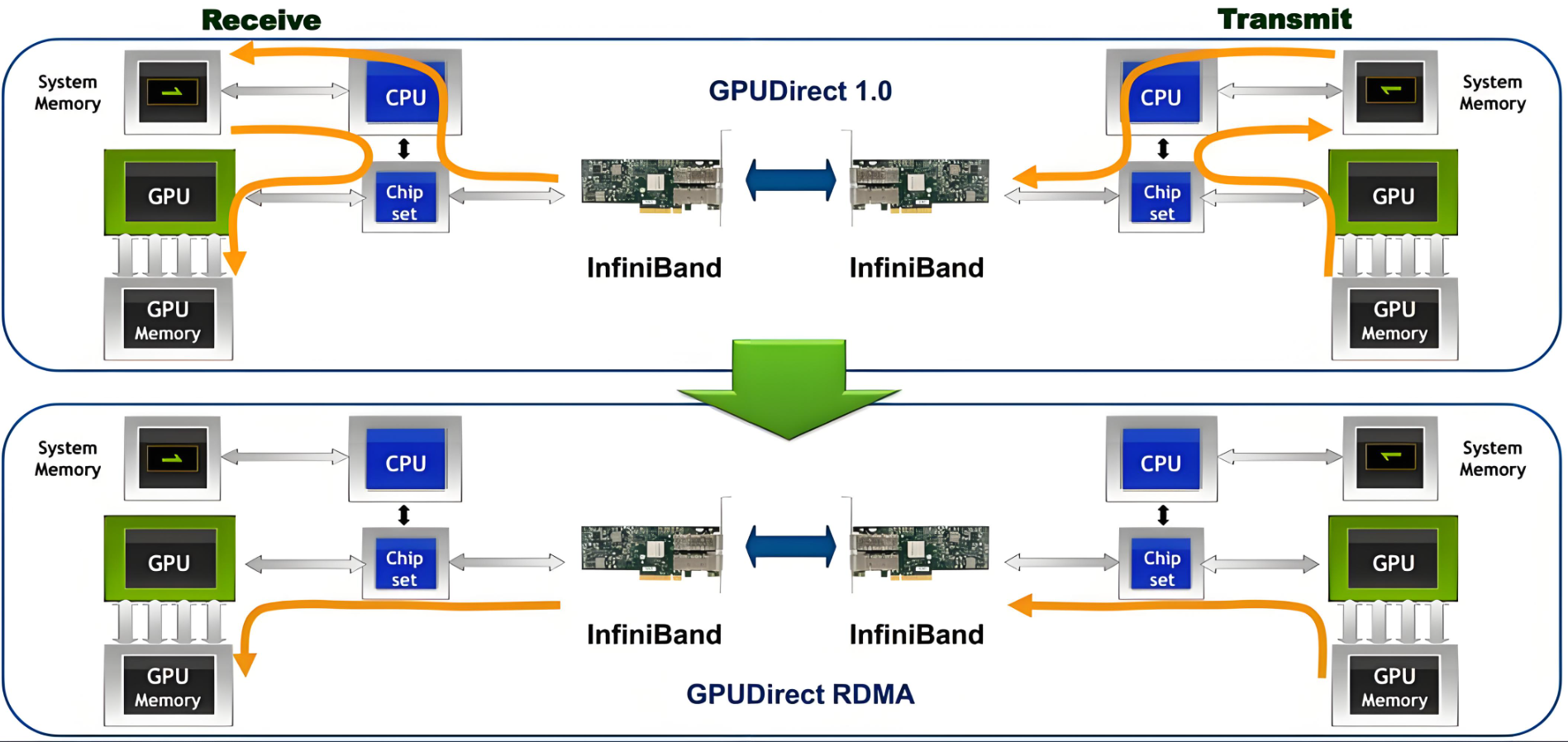
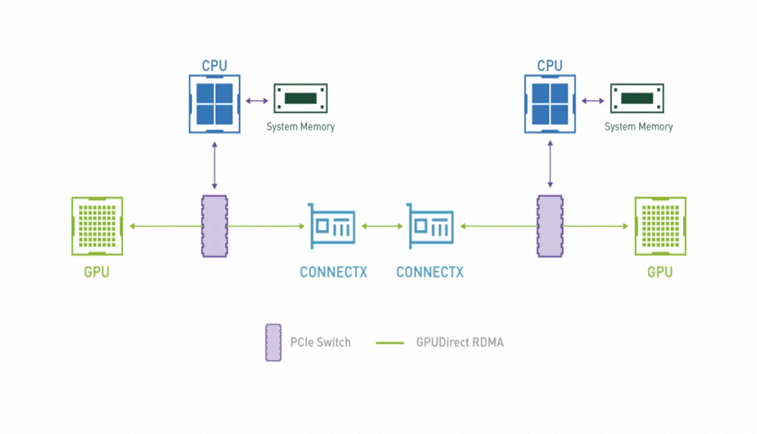
简介:随着人工智能(AI)的迅速发展,越来越多的应用需要巨大的GPU计算资源。GPUDirect RDMA 是 Kepler 级 GPU 和 CUDA 5.0 中引入的一项技术,可以让使用pcie标准的gpu和第三方设备进行直接的数据交换,而不涉及CPU。背景:GPUDirect RDMA 是 Kepler 级 GPU 和 CUDA 5.0 中引入的一项技术,可以让使用pcie标准的gpu和第三....
技术改变AI发展:RDMA能优化吗?GDR性能提升方案(GPU底层技术系列二)
背景GPUDirect RDMA 是 Kepler 级 GPU 和 CUDA 5.0 中引入的一项技术,可以让使用pcie标准的gpu和第三方设备进行直接的数据交换,而不涉及CPU。传统上,当数据需要在 GPU 和另一个设备之间传输时,数据必须通过 CPU,从而导致潜在的瓶颈并增加延迟。使用 GPUDirect,网络适配器和存储驱动器可以直接读写 GPU 内存,减少不必要的内存消耗,减少 CPU....
Nvidia_Mellanox_CX5和6DX系列网卡_RDMA_RoCE_无损和有损_DCQCN拥塞控制等技术简介-一文入门RDMA和RoCE有损无损
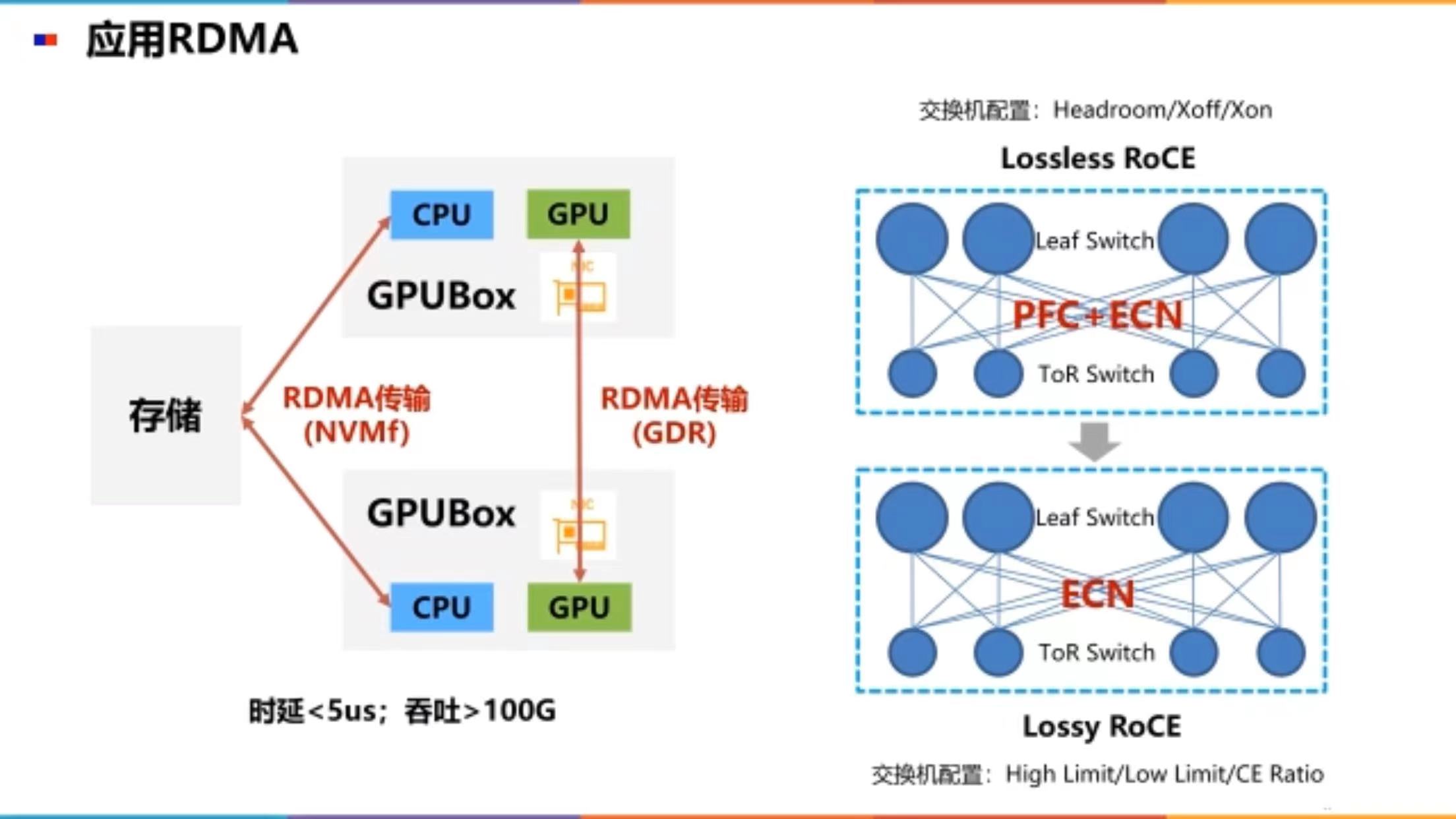
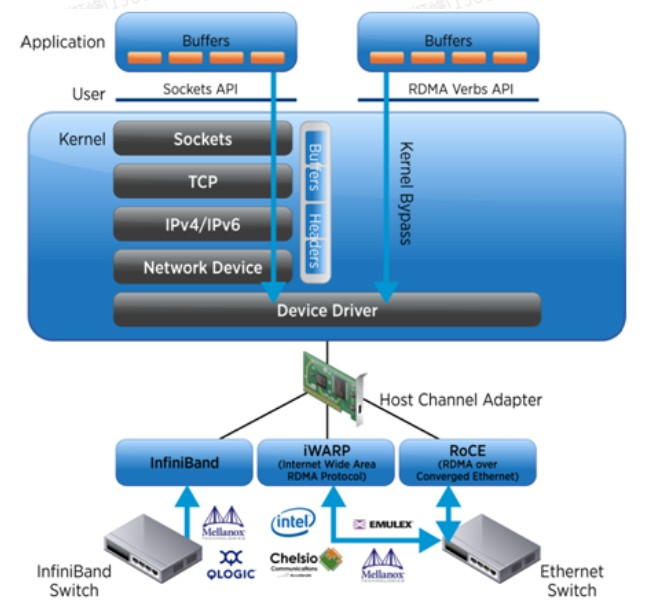
简介随着互联网, 人工智能等兴起, 跨机通信对带宽和时延都提出了更高的要求, RDMA技术也不断迭代演进, 如: RoCE(RDMA融合以太网)协议, 从RoCEv1 -> RoCEv2, 以及IB协议, Mellanox的RDMA网卡cx4, cx5, cx6/cx6DX, cx7等, 本文主要基于CX5和CX6DX对RoCE技术进行简介, 一文入门RDMA和RoCE有损及无损关键技术术....
关于远程直接内存访问技术 RDMA 的高性能架构设计介绍
传统以太网方案存在系统调用消耗大量时间、增加数据传输延时、对 CPU 造成很重的负担三个缺点,而 RDMA 技术可以解决以上三个缺点。那 RDMA 究竟是什么?它的方案的设计思路是什么?浪潮信息驱动工程师刘伟带大家深入理解 RDMA 技术的基本原理,交流在工程上的设计思路。 1.RDMA技术的优点、基础知识和设计思路 RDMA 和传统网络方案的比较...

浅析GPU通信技术(下)-GPUDirect RDMA
目录 浅析GPU通信技术(上)-GPUDirect P2P 浅析GPU通信技术(中)-NVLink 浅析GPU通信技术(下)-GPUDirect RDMA 1. 背景 前两篇文章我们介绍的GPUDirect P2P和NVLink技术可以大大提升GPU服务器单机的GPU通信性能,当前深度学习模型越来越复杂,计算数据量暴增,对于大规模深度学习训练...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
开发与运维
集结各类场景实战经验,助你开发运维畅行无忧
+关注