
基于ACK多机分布式部署DeepSeek满血版推理部署实战
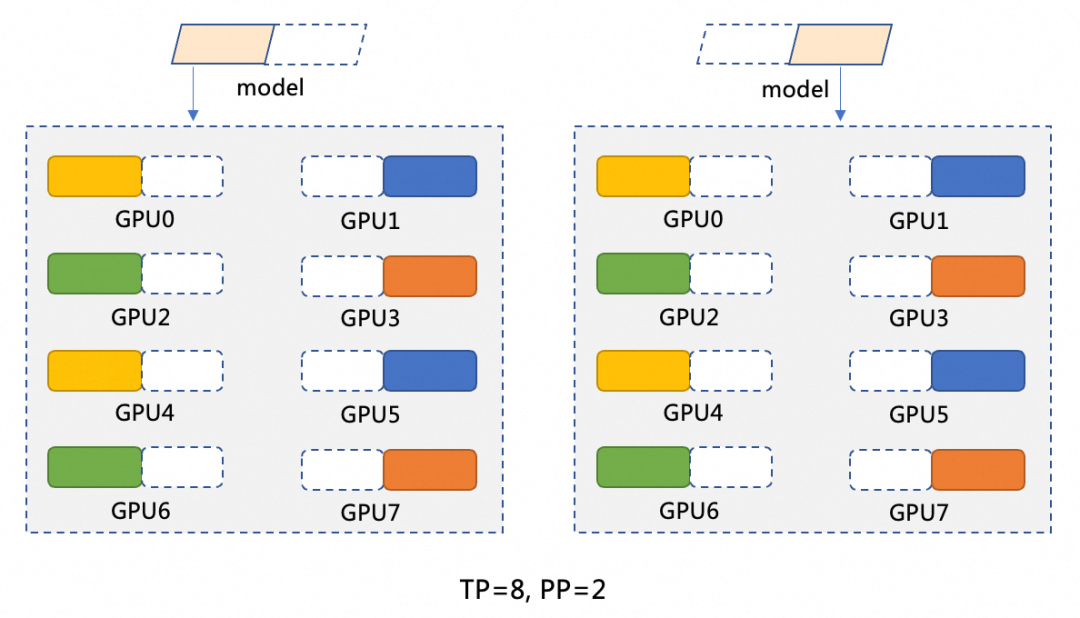
本文深入解析基于阿里云容器服务ACK的DeepSeek-R1-671B大模型分布式推理实战方案。针对该千亿参数模型(671B)单卡显存不足的挑战,提出混合并行策略(Pipeline Parallelism=2 + Tensor Parallelism=8),结合阿里云Arena工具,实现在2台ecs.ebmgn8v.48xlarge(8*96GB)节点上的高效分布式部署。进一步演示如何将部署于AC...
在ACK Edge集群中部署混合云LLM弹性推理
为解决混合云场景下部署LLM推理业务时,流量的不均衡带来的数据中心GPU资源分配问题,ACK Edge集群提供了一套混合云LLM弹性推理解决方案,帮您统一管理云上和云下的GPU资源,低峰期优先使用云下数据中心资源,高峰期资源不足时快速启用云上资源。该方案帮您显著降低LLM推理服务运营成本,动态调整并灵活利用资源,保障服务稳定性,避免资源闲置。
基于Knative部署vLLM推理应用
传统的基于GPU利用率的弹性伸缩策略无法准确反映大模型推理服务的实际负载情况,即使GPU利用率达到了100%,也不一定表明系统正处在高负荷运行状态。Knative提供的自动扩缩容机制KPA(Knative Pod Autoscaler)能够根据QPS或RPS来调整资源分配,更直接地反映推理服务的性能表现。本文以Qwen-7B-Chat-Int8模型、GPU类型为V100卡为例,介绍如何在Knati...
ACK Gateway with AI Extension:大模型推理的模型灰度实践
【阅读原文】戳:ACK Gateway with AI Extension:大模型推理的模型灰度实践 ACK Gateway with AI Extension组件专为LLM推理场景设计,支持四层/七层流量路由,并提供基于模型服务器负载智能感知的负载均衡能力。此外,通过InferencePool和InferenceModel自定义资源(CRD),可以灵活定义推理服务的...

ACK Gateway with AI Extension:面向Kubernetes大模型推理的智能路由实践
【阅读原文】戳:ACK Gateway with AI Extension:面向Kubernetes大模型推理的智能路由实践 在当今大语言模型(LLM)推理场景中,Kubernetes已经成为LLM推理服务部署不可获取的基础设施,但在LLM流量管理方面、由于LLM推理服务和推理流量的特殊性,传统的负载均衡和路由调度算法已难以满足该类服务的高性能、高可靠性需求。阿里云容...

使用容器服务ACK快速部署QwQ-32B模型并实现推理智能路由
【阅读原文】戳:使用容器服务ACK快速部署QwQ-32B模型并实现推理智能路由 背景介绍 1. QwQ-32B模型 阿里云最新发布的QwQ-32B模型,通过强化学习大幅度提升了模型推理能力。QwQ-32B模型拥有320亿参数,其性能可以与DeepSeek-R1 671B媲美。模型数学代码等核心指标(...

大道至简-基于ACK的Deepseek满血版分布式推理部署实战
本文是基于阿里云容器服务产品ACK,部署Deepseek大语言模型推理服务系列文章的第二篇。将介绍如何在Kubernetes管理的GPU集群中,快速部署多机分布式Deepseek-R1 671B(“满血版”)推理服务。并集成Dify应用,构建一个简单的Deepseek问答助手。关于如何在ACK部署Deepseek“蒸馏版”模型推理服务,可以参考本系列第一篇文章《基于ACK的DeepSeek蒸馏模....
大道至简-基于ACK的Deepseek满血版分布式推理部署实战
【阅读原文】戳:大道至简-基于ACK的Deepseek满血版分布式推理部署实战 本文是基于阿里云容器服务产品ACK,部署Deepseek大语言模型推理服务系列文章的第二篇。将介绍如何在Kubernetes管理的GPU集群中,快速部署多机分布式Deepseek-R1 671B(“满血版”)推理服务。并集成Dify应用,构建一个简单的Deepseek问答助手。关于如何在A...

AI模型推理服务在Knative中最佳配置实践
Knative和AI结合提供了快速部署、高弹性和低成本的技术优势,适用于需要频繁调整计算资源的AI应用场景,例如模型推理等。您可以通过Knative Pod部署AI模型推理任务,配置自动扩缩容、灵活分配GPU资源等功能,提高AI推理服务能力和GPU资源利用率。
使用 NVIDIA NIM 在阿里云容器服务(ACK)中加速 LLM 推理
大语言模型(LLM)是近年来发展迅猛并且激动人心的热点话题,引入了许多新场景,满足了各行各业的需求。随着开源模型能力的不断增强,越来越多的企业开始尝试在生产环境中部署开源模型,将 AI 模型接入到现有的基础设施,优化系统延迟和吞吐量,完善监控和安全等方面。然而要在生产环境中部署这一套模型推理服务过程复杂且耗时。为了简化流程,帮助企业客户加速部署生成式 AI 模型,本文结合 **NVIDIA NI....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
容器服务Kubernetes版推理相关内容
容器服务Kubernetes版您可能感兴趣
- 容器服务Kubernetes版报错
- 容器服务Kubernetes版部署
- 容器服务Kubernetes版大模型
- 容器服务Kubernetes版ai
- 容器服务Kubernetes版gateway
- 容器服务Kubernetes版灰度
- 容器服务Kubernetes版模型
- 容器服务Kubernetes版实践
- 容器服务Kubernetes版api
- 容器服务Kubernetes版服务器
- 容器服务Kubernetes版集群
- 容器服务Kubernetes版容器
- 容器服务Kubernetes版pod
- 容器服务Kubernetes版应用
- 容器服务Kubernetes版云原生
- 容器服务Kubernetes版服务
- 容器服务Kubernetes版阿里云
- 容器服务Kubernetes版 Pod
- 容器服务Kubernetes版docker
- 容器服务Kubernetes版k8s
- 容器服务Kubernetes版 Docker
- 容器服务Kubernetes版节点
- 容器服务Kubernetes版安装
- 容器服务Kubernetes版 K8S
- 容器服务Kubernetes版配置
- 容器服务Kubernetes版架构
- 容器服务Kubernetes版kubernetes
- 容器服务Kubernetes版网络
- 容器服务Kubernetes版资源
- 容器服务Kubernetes版 kubernetes

