
融合AMD与NVIDIA GPU集群的MLOps:异构计算环境中的分布式训练架构实践
在深度学习的背景下,NVIDIA的CUDA与AMD的ROCm框架缺乏有效的互操作性,导致基础设施资源利用率显著降低。随着模型规模不断扩大而预算约束日益严格,2-3年更换一次GPU的传统方式已不具可持续性。但是Pytorch的最近几次的更新可以有效利用异构计算集群,实现对所有可用GPU资源的充分调度,不受制于供应商限制。 本文将深入探讨如何混合AMD/NVIDIA GPU集群以支持PyTorch分....

SQL调优的方法和实践案例
本文介绍了SQL调优的方法和实践案例。找出需要调优的慢SQL后,可以先通过EXPLAIN查看执行计划,然后通过如下方法进行优化:对表结构进行优化以便下推更多计算至存储层MySQL、适当增加索引、优化执行计划和增加并行度。
深度解析 Uno Platform 离线状态处理技巧:从网络检测到本地存储同步,全方位提升跨平台应用在无网环境下的用户体验与数据管理策略
处理离线状态下的用户体验是任何现代应用开发中不可或缺的一部分。当用户在网络连接不稳定或完全断开的情况下使用应用时,仍能提供良好的用户体验至关重要。Uno Platform 作为一个强大的跨平台框架,为开发者提供了多种手段来应对这一挑战。本文将通过一个具体的案例——在线笔记应用——来探讨如何在 Uno Platform 中优雅地处理离线状态,并提供示例代码...
分布式训练在TensorFlow中的全面应用指南:掌握多机多卡配置与实践技巧,让大规模数据集训练变得轻而易举,大幅提升模型训练效率与性能
分布式训练是解决大规模数据集训练问题的有效手段,尤其在深度学习领域,模型复杂度和数据量的增加使得单机训练变得不切实际。TensorFlow 提供了强大的分布式训练支持,使得开发者能够利用多台机器的计算资源来加速模型训练。本文将以最佳实践的形式,详细介绍如何在 TensorFlow 中实施分布式训练,并通过具体示例代码展示其实现...
【AI大模型】分布式训练:深入探索与实践优化
在人工智能的浩瀚宇宙中,AI大模型以其惊人的性能和广泛的应用前景,正引领着技术创新的浪潮。然而,随着模型参数的指数级增长,传统的单机训练方式已难以满足需求。分布式训练作为应对这一挑战的关键技术,正逐渐成为AI研发中的标配。本文将深入探讨分布式训练的核心原理、技术细节、面临的挑战以及优化策略,并拓展一些相关的前沿知识点。 一、分布式训练的核心原理 分布式训练的核心在于将大规模的数据...
分布式训练:大规模AI模型的实践与挑战
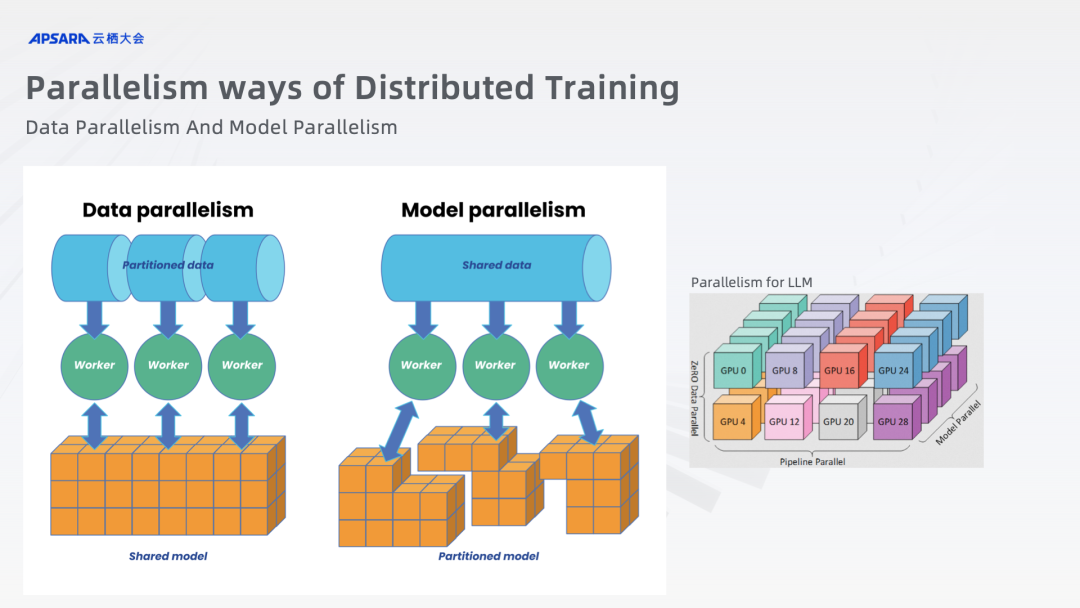
1. 引言 分布式训练允许数据科学家和工程师在多个计算节点上并行执行模型训练,从而显著加快训练速度。这种方法对于处理大规模数据集尤其重要,因为单个计算设备往往无法满足内存和计算资源的需求。 2. 分布式训练的基础 2.1 数据并行 vs. 模型并行 数据并行:每个GPU或节点上运行相同模型的不同实例,并在不同的数据子集上进行训练。模型并行&...
偏分析场景如何实践和优化
PolarDB-X是一款以TP为主的HTAP数据库,也支持一定场景的分析需求。而典型的分析场景一般有以下几类特征:PolarDB-X少量的写或者更新请求,大多数是读请求;每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列;大多数查询都是比较复杂的查询,查询的并发不会很大,但单个查询需要高吞吐...
阿里云 ACK 云原生 AI 套件中的分布式弹性训练实践
作者:霍智鑫众所周知,随着时间的推移,算力成为了 AI 行业演进一个不可或缺的因素。在数据量日益庞大、模型体量不断增加的今天,企业对分布式算力和模型训练效率的需求成为了首要的任务。如何更好的、更高效率的以及更具性价比的利用算力,使用更低的成本来训练不断的迭代 AI 模型,变成了迫切需要解决的问题。而分布式训练的演进很好的体现了 AI 模型发展的过程。Distributed Training分布式....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
分布式更多实践相关
产品推荐

阿里云分布式应用服务
企业级分布式应用服务 EDAS(Enterprise Distributed Application Service)是应用全生命周期管理和监控的一站式PaaS平台,支持部署于 Kubernetes/ECS,无侵入支持Java/Go/Python/PHP/.NetCore 等多语言应用的发布运行和服务治理 ,Java支持Spring Cloud、Apache Dubbo近五年所有版本,多语言应用一键开启Service Mesh。
+关注