
DataWorks中EMR Serverless Spark版本的用户画像分析的加工数据阶段
本文为您介绍如何用Spark SQL创建外部用户信息表ods_user_info_d_spark以及日志信息表ods_raw_log_d_spark访问存储在私有OSS中的用户与日志数据,通过DataWorks的EMR Spark SQL节点进行加工得到目标用户画像数据,阅读本文后,您可以了解如何通过Spark SQL来计算和分析已同步的数据,完成数仓简单数据加工场景。
订阅Serverless Spark工作流系统事件通知
EMR Serverless Spark已接入云监控平台,您可以通过事件订阅对重要的事件设置定制化的报警通知,让您及时了解事件的发生与进展,帮助您实时掌握事件动态,便于您在业务故障时快速分析并定位问题。
集成第三方调度系统时需要进行的配置要点
DataWorks的开放平台为您提供OpenEvent、OpenAPI等开放能力,您可通过开放平台将第三方调度系统集成到DataWorks的调度系列中,将三方调度系统的任务嵌入DataWorks的业务流程中。本文以一个示例为您介绍集成第三方调度系统时需要进行的配置要点。
阿里巴巴飞天大数据架构体系与Hadoop生态系统的深度融合:构建高效、可扩展的数据处理平台
引言在当今大数据时代,数据已成为企业最重要的资产之一。如何高效地处理、存储和分析海量数据,成为企业提升竞争力的关键。阿里巴巴飞天大数据架构体系与Hadoop生态系统作为业界领先的大数据解决方案,以其高效、可扩展和可靠的特点,被广泛应用于各行各业。本文将深入探讨阿里巴巴飞天大数据架构体系与Hadoop生态系统的深度融合,从架构设...
Fuxi2.0—飞天大数据平台调度系统全面升级,首次亮相2019双十一
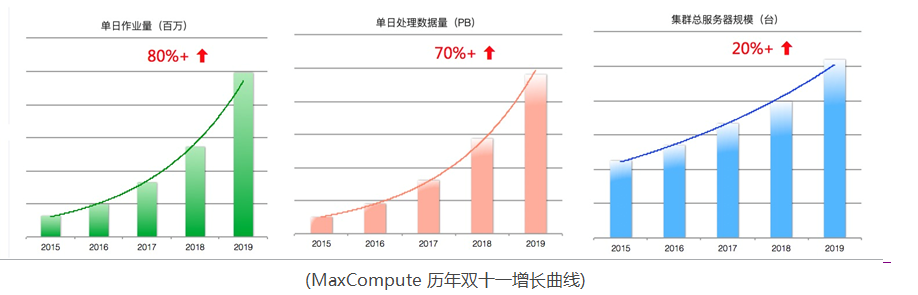
伏羲(Fuxi)是十年前创立飞天平台时的三大服务之一(分布式存储 Pangu,分布式计算 ODPS,分布式调度 Fuxi),当时的设计初衷是为了解决大规模分布式资源的调度问题(本质上是多目标的最优匹配问题)。 随着阿里经济体和阿里云业务需求(尤其是双十一)的不断丰富,伏羲的内涵也不断扩大,从单一的资源调度器(对标开源系统的YARN)扩展成大数据的核心调度服务,覆盖数据调度(Data Placem....
阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台、云梯2、MaxCompute、实时计算到底是什么,和自建Hadoop平台有什么区别。 先说Hadoop 什么是Hadoop?Hadoop是一个开源、高可靠、可扩展的分布式大数据计算框架系统,主要用来解决海量数据的存储、分析、分布式资源调度等。Hadoop最大的优点就是能够提供并行计算,充分利用集群的威力进行高速运算和存储。 Hadoop的核心有两大板块:HDFS和M....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute系统相关内容
- 云原生大数据计算服务 MaxCompute系统解决方案
- polardb-x云原生大数据计算服务 MaxCompute系统
- 大数据云原生大数据计算服务 MaxCompute系统
- 数据计算云原生大数据计算服务 MaxCompute系统
- 云原生大数据计算服务 MaxCompute构建系统
- 云原生大数据计算服务 MaxCompute构建noxmobi全球化营销系统
- 云原生大数据计算服务 MaxCompute架构系统
- 云原生大数据计算服务 MaxCompute开源系统
- 插件云原生大数据计算服务 MaxCompute系统
- 阿里巴巴云原生大数据计算服务 MaxCompute系统
- 云原生大数据计算服务 MaxCompute系统融合
- 云原生大数据计算服务 MaxCompute系统环境
- 云原生大数据计算服务 MaxCompute系统配置
- 教程云原生大数据计算服务 MaxCompute系统
- 云原生大数据计算服务 MaxCompute系统概述
- 云原生大数据计算服务 MaxCompute资源系统
- 云原生大数据计算服务 MaxCompute数据处理系统
- 云原生大数据计算服务 MaxCompute系统论文
- 云原生大数据计算服务 MaxCompute系统源码
- 云原生大数据计算服务 MaxCompute系统框架
- 云原生大数据计算服务 MaxCompute网站系统
- 云原生大数据计算服务 MaxCompute集群系统
- 云原生大数据计算服务 MaxCompute系统hdfs
- 云原生大数据计算服务 MaxCompute采集系统
- 云原生大数据计算服务 MaxCompute可视化系统
- 开源云原生大数据计算服务 MaxCompute系统
- 云原生大数据计算服务 MaxCompute系统软件
- 云原生大数据计算服务 MaxCompute系统部署
- 云原生大数据计算服务 MaxCompute营销系统
- 作业云原生大数据计算服务 MaxCompute系统
云原生大数据计算服务 MaxCompute更多系统相关
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute样本
- 云原生大数据计算服务 MaxCompute训练
- 云原生大数据计算服务 MaxCompute特征
- 云原生大数据计算服务 MaxCompute实战
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute工程
- 云原生大数据计算服务 MaxCompute设备管理
- 云原生大数据计算服务 MaxCompute智能教育
- 云原生大数据计算服务 MaxCompute实验
- 云原生大数据计算服务 MaxCompute配置
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps

