
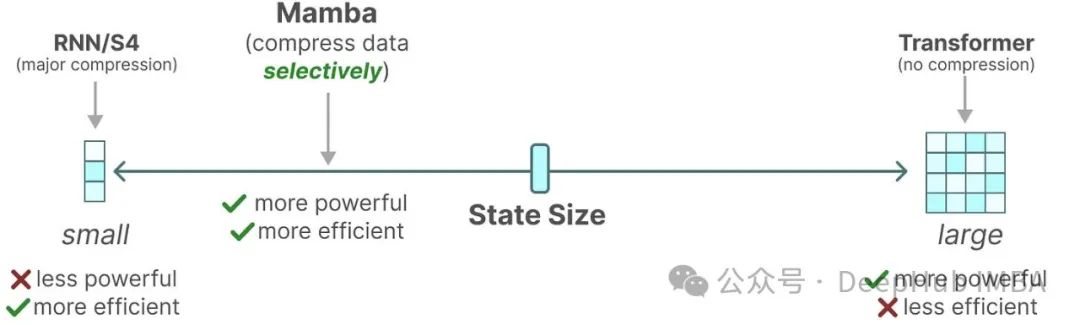
Transformer、RNN和SSM的相似性探究:揭示看似不相关的LLM架构之间的联系
通过探索看似不相关的大语言模型(LLM)架构之间的潜在联系,我们可能为促进不同模型间的思想交流和提高整体效率开辟新的途径。 尽管Mamba等线性循环神经网络(RNN)和状态空间模型(SSM)近来备受关注,Transformer架构仍然是LLM的主要支柱。这种格局可能即将发生变化:像Jamba、Samba和Griffin这样的混合架构展现出了巨大的潜力。这些模型在时间和内存效率方面明显优于Tra.....
彻底改变语言模型:全新架构TTT超越Transformer,ML模型代替RNN隐藏状态
近年来,深度学习领域取得了巨大的进步,其中自然语言处理(NLP)是最为突出的领域之一。然而,尽管取得了这些成功,但当前的模型仍然存在一些局限性,如长上下文建模和计算效率之间的权衡。为了解决这些问题,研究人员提出了一种全新的模型架构,名为Test-Time Training...
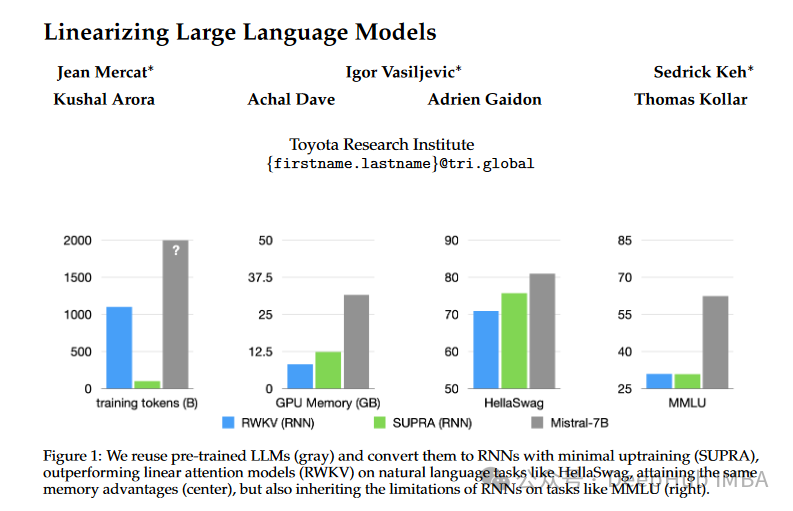
SUPRA:无须额外训练,将Transformer变为高效RNN,推理速度倍增
Transformers 已经确立了自己作为首要模型架构的地位,特别是因为它们在各种任务中的出色表现。但是Transformers 的内存密集型性质和随着词元数量的指数扩展推理成本带来了重大挑战。为了解决这些问题,论文“Linearizing Large Language Models”引入了一种创新的方法,称为UPtraining for Recurrent Attention (SUPRA)....
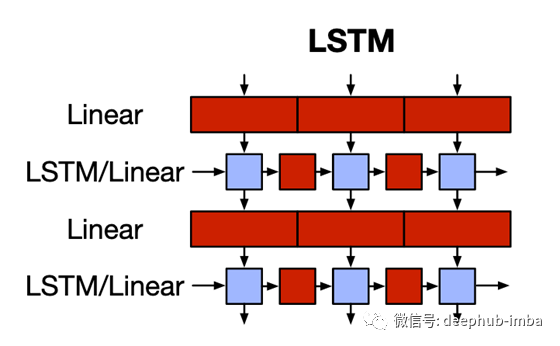
Transformer相比RNN和LSTM有哪些优势?
Transformer 是一种基于自注意力机制的深度学习模型,相较于 RNN 和 LSTM,它具有以下优势:1. **并行计算**:RNN 和 LSTM 需要顺序处理序列数据,因此很难进行并行计算。而 Transformer 的自注意力机制允许同时处理整个序列,从而可以充分利用 GPU 的并行计算能力,大大提高模型训练和推理的速度。2. **长距离依赖**:在长序列中,RNN 和 LSTM 容易....
RWKV项目原作解读:在Transformer时代重塑RNN
机器之心最新一期线上分享邀请到了新加坡国立大学博士侯皓文,现 RWKV Foundation 成员,为大家分享他们团队的开源项目 RWKV。Transformer 已经彻底改变了几乎所有自然语言处理(NLP)任务,但其在序列长度上的内存和计算复杂度呈二次方增长。相比之下,循环神经网络(RNN)在内存和计算需求上呈线性扩展,但由于并行化和可扩展性的限制,难以达到 Transformer 相同的性能....

在Transformer时代重塑RNN,RWKV将非Transformer架构扩展到数百亿参数
机器之心编辑部Transformer 模型在几乎所有自然语言处理(NLP)任务中都带来了革命,但其在序列长度上的内存和计算复杂性呈二次方增长。相比之下,循环神经网络(RNNs)在内存和计算需求上呈线性增长,但由于并行化和可扩展性的限制,很难达到与 Transformer 相同的性能水平。本文提出了一种新颖的模型架构,Receptance Weighted Key Value(RWKV),将 Tr....

Transformer的潜在竞争对手QRNN论文解读,训练更快的RNN
使用递归神经网络(RNN)序列建模业务已有很长时间了。但是RNN很慢因为他们一次处理一个令牌无法并行化处理。此外,循环体系结构增加了完整序列的固定长度编码向量的限制。为了克服这些问题,诸如CNN-LSTM,Transformer,QRNNs之类的架构蓬勃发展。在本文中,我们将讨论论文“拟递归神经网络”(https://arxiv.org/abs/1611.01576)中提出的QRNN模型。从本质....
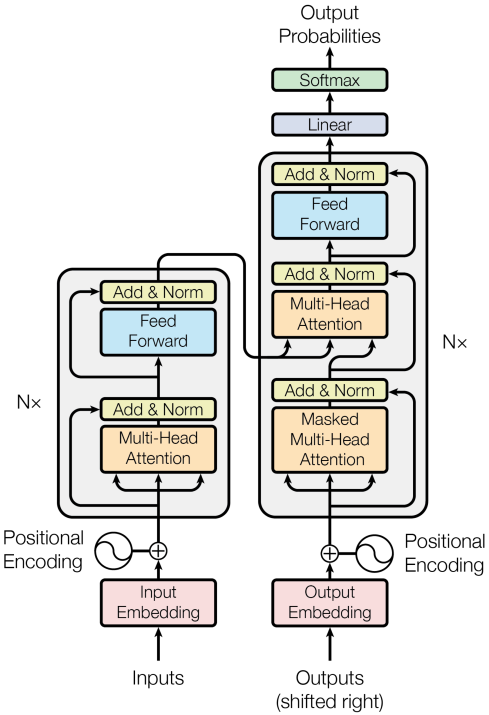
9_Transformer Model:Attention without RNN
一、Transformer ModelTransformer由Attention和self-Attention层组成Transformer 模型完全基于AttentionAttention原本是用在RNN上的,这节课把RNN去掉,只保留AttentionOriginal paper: Vaswani et al. Attention Is All You Need. In NIPS, 2017.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。