
Jsoup 爬虫:轻松搞定动态加载网页内容
一、动态加载网页的原理在深入探讨如何使用 Jsoup 获取动态加载内容之前,我们需要先了解动态加载网页的原理。传统的静态网页内容在服务器响应时已经完整生成,而动态加载的网页则通过 JavaScript 在客户端动态生成内容。这些内容可能通过以下几种方式实现:Ajax 请求:页面初始加载时,只加载基础框架,后续内容...
Jsoup爬虫
1.什么是爬虫技术 爬虫技术(Web scraping)是一种通过自动化程序来访问网页并提取数据的技术。这些程序被称为爬虫(spider)或者网络爬虫(web crawler)。爬虫技术通常用于从网页上抓取大量数据,这些数据可以用于各种用途,例如数据分析、搜索引擎索引、价格比较、内容聚合等 2.了解jsoup jsoup 是一款Java 的HTML解析器,可直接解析...
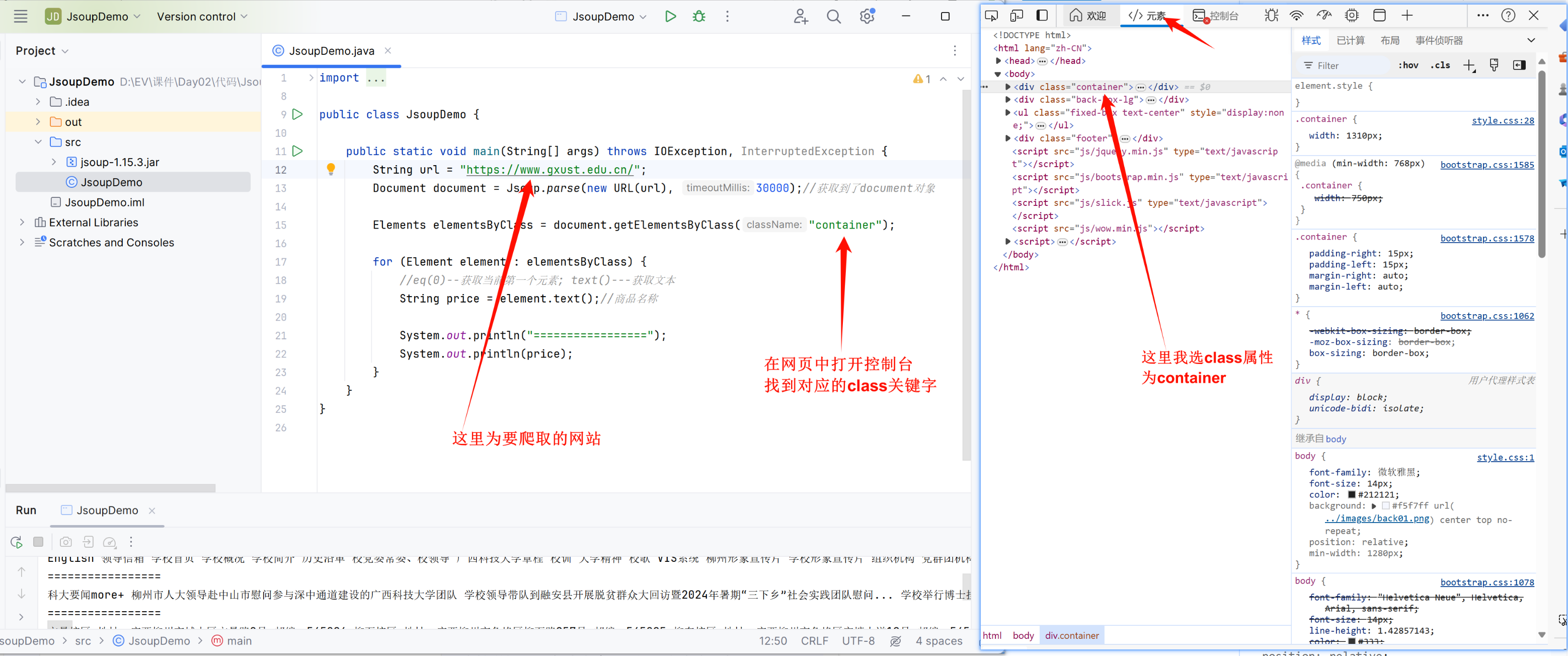
使用Jsoup爬虫
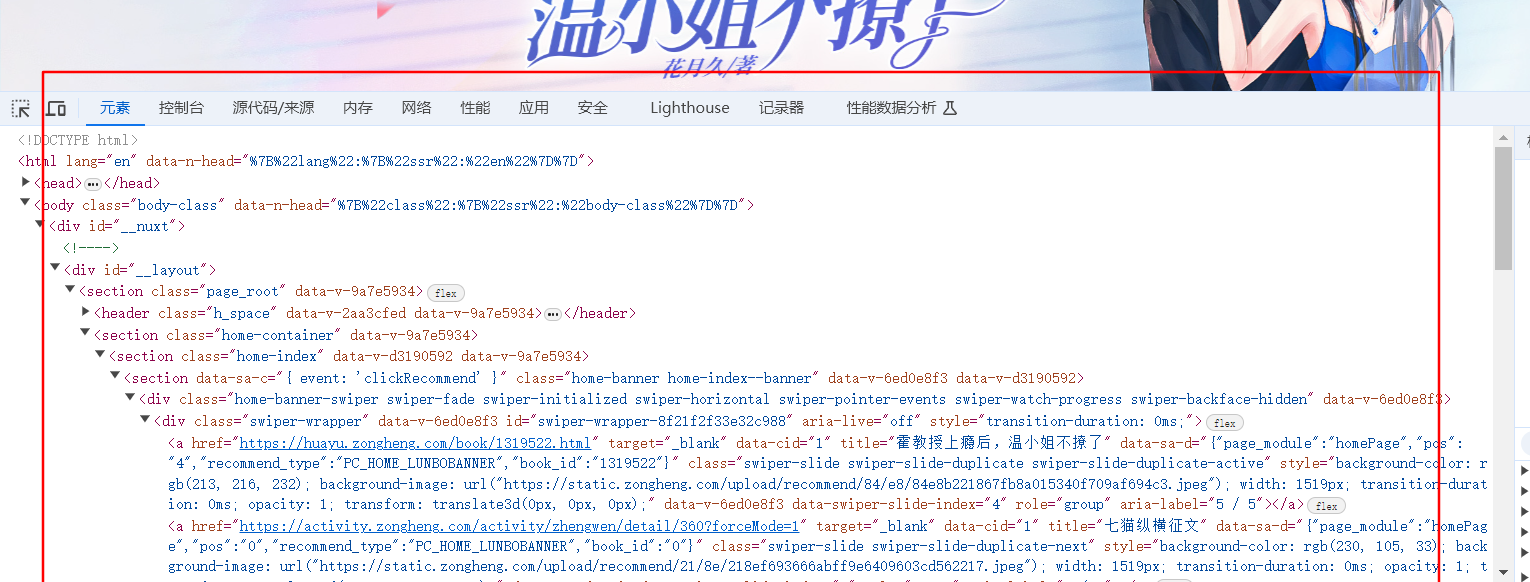
原理分析 当我们尝试访问某一个网站时,这里以一个普通的小说网站为例,此时F12或者右键-检查,可以看到有大量的原始代码返回,这部分我们叫做前端代码 此时,假设我们需要爬取某部分信息,只需要右键检查内容,此时下...
JSoup 爬虫遇到的 404 错误解决方案
在网络爬虫开发中,使用JSoup进行数据抓取是一种常见的方式。然而,当我们尝试使用JSoup来爬虫抓取腾讯新闻网站时,可能会遇到404错误。这种情况可能是由于网站的反面爬虫机制检测到了我们的爬虫行为,从而拒绝了我们的请求。假设我们希望使用JSoup来爬取腾讯新闻的数据,但在实际操作中,我们却遇到404错误。这可能是因为腾讯新闻网站采取了一些反爬虫措施,例如检测请求头中的用户- Agent信息或者....

jsoup爬虫发送get、post请求、解析html、获取json
@[TOC] 1 简介 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据 依赖 <dependency> <groupId>org.jsoup</...
Jsoup,(安卓)强大的爬虫解析工具!
介绍 Jsoup是一个用来处理html文本的java库。它提供了非常方便的API,可以通过dom,css或者类似jquery的方法来提取和操作数据。 嗯,所以他到底是干嘛的呢? 当我们访问一个网站拿到它的html代码的时候,往往我们所需要的一些数据就已经包含在html里,Jsoup就是帮我们把这些我们想要的数据提取出来。还是不够清晰明了?没关系,我们一起来看一个demo。 demo 以解析...
jsoup爬虫获取网页信息? 400 报错
jsoup爬虫获取网页信息? 400 报错 @Leon温陵 你好,想跟你请教个问题:对你分享的虎嗅网抓取代码,狠是受益匪浅,但是我想问你 :“根据虎嗅网文章url的特点,构造请求URI ”,这个如果是新浪新闻,url不固定怎么解决。(也就是怎么样点击进去大的网址,能获取到大网址下边的列表链接信息呢?)
JAVA + jsoup + httpUnit 爬虫报错
String sinaLoginUrl="http://apps.evozi.com/apk-downloader"; WebClient client=new WebClient(); client.getOptions().setCssEnabled(false); client.getOptions().setJavaScriptEnabled(true);//设置成true就报错...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注