
【计算机视觉 | 目标检测】RegionCLIP: Region-based language-image pretraining
一、提出原因 使用(image-text pairs)图像-文本对数据的对比语言图像预训练模型(Contrastive language-image pretraining,CLIP)在图像分类方面的zero-shot和迁移学习的取得了非常好的结果。但是,直接应用CLIP这样的模型来进行图像区域推理(如目标检测)效果将会不好。主要原因:CLIP只是进行图像整体与文本描述匹配,而不能捕获图像区域.....

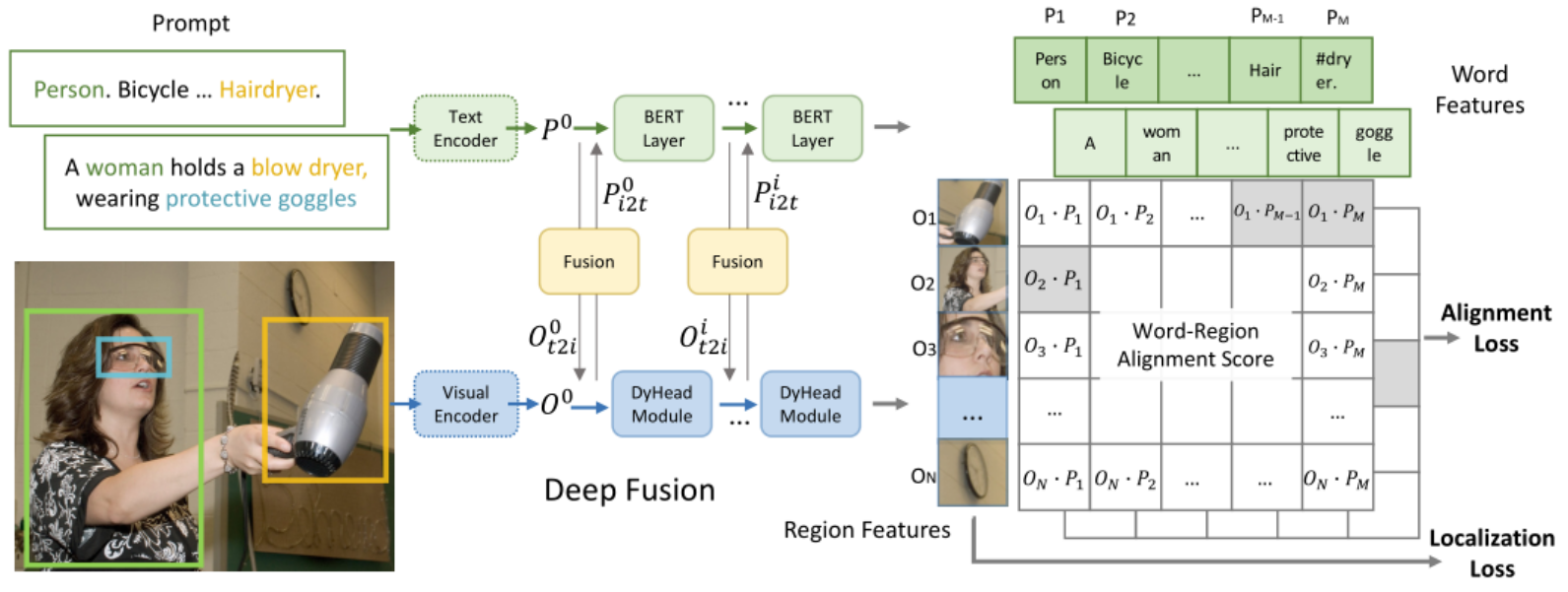
【计算机视觉】Grounded Language-Image Pre-training
一、提出的原因 类似CLIP多模态模型只做到文本图片后融合的对齐,没有图片细粒度的object级别的细粒度语义表征能力 MDETR没有统一目标检测和已有的多模态任务grounding CLIP由于训练集image-text pair比任何已有的anation数据集都包含更丰富的视觉概念,很容易0-shot迁移到下游任务,但是只做文本图片后融合的对齐,由于缺少object级别的细粒度理...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
计算机视觉
包含图像分类、图像生成、人体人脸识别、动作识别、目标分割、视频生成、卡通画、视觉评价、三维视觉等多个领域
+关注