
如何实现Flink+DLF数据入湖与分析
数据湖构建(DLF)可以结合阿里云实时计算Flink版(Flink VVP),以及Flink CDC相关技术,实现灵活定制化的数据入湖。并利用DLF统一元数据管理、权限管理等能力,实现数据湖多引擎分析、数据湖管理等功能。本文为您介绍Flink+DLF数据湖方案具体步骤。
Flink+DLF数据入湖与分析实践
阿里云实时计算Flink版结合DLF Paimon Catalog,实现Flink作业结果到数据湖的高效写入和元数据同步,支持无缝对接多种计算引擎并优化数据湖管理,本文为您介绍具体的操作流程。
日常节省 30%计算资源:阿里云实时计算 Flink 自动调优实践
摘要:本文整理自阿里云开发工程师,Apache Flink Contributor 钟旭阳,在 Flink Forward Asia 2022 生产实践的分享。本篇内容主要分为四个部分:历史背景框架简介案例介绍未来规划点击查看原文视频 & 演讲PPT一、历史背景批作业在算子实际处理数据时,可以提前感知到要处理的这部分数据有多大。从而可以根据数据量的大小,选择合适的资源处理数据。但流作业是....

Flink RocksDB 状态后端参数调优实践
作者:LittleMagic 截至当前,Flink 作业的状态后端仍然只有 Memory、FileSystem 和 RocksDB 三种可选,且 RocksDB 是状态数据量较大(GB 到 TB 级别)时的唯一选择。RocksDB 的性能发挥非常仰赖调优,如果全部采用默认配置,读写性能有可能会很差。 但是,RocksDB 的配置也是极为复杂的,可调整的参数多达百个,没有放之四海而皆准的优化方案。....
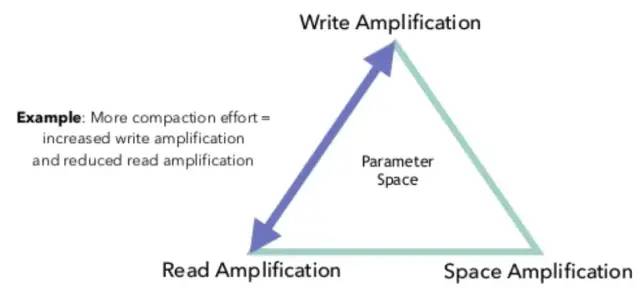
Flink作业问题分析和调优实践
作者:李康 摘要:本文主要分享 Flink 的 CheckPoint 机制、反压机制及 Flink 的内存模型。对这3部分内容的熟悉是调优的前提,文章主要从以下几个部分分享: 原理剖析 性能定位 经典场景调优 内存调优 Checkpoint 机制 1.什么是 checkpoint 简单地说就是 Flink 为了达到容错和 exactly-once 语义的功能,定期把 state 持久化下...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
实时计算 Flink版实践相关内容
- 实时计算 Flink版cep实践
- 实时计算 Flink版实践功能
- 实时计算 Flink版场景实践
- 实践实时计算 Flink版hologres
- 实践实时计算 Flink版github
- 实践实时计算 Flink版
- 实时计算 Flink版分析实践
- 实时计算 Flink版快手实践
- 实时计算 Flink版快手实践window窗口
- 实时计算 Flink版实践窗口
- 实时计算 Flink版实践cumulate
- 实时计算 Flink版sql实践
- onesql olap实践实时计算 Flink版
- 实践实时计算 Flink版数据计算
- 实时计算 Flink版doris实践
- 实时计算 Flink版项目实践
- 实时计算 Flink版数仓实践
- 实时计算 Flink版云原生数仓实践
- 实时计算 Flink版云原生实践
- 实时计算 Flink版大数据实践
- 实时计算 Flink版paimon数仓实践
- 实时计算 Flink版paimon实践
- 实时计算 Flink版构建实践
- 实时计算 Flink版cdc生产实践
- 科技实时计算 Flink版实践
- 实时计算 Flink版平台实践
- 实时计算 Flink版性能优化实践
- 实时计算 Flink版优化实践
- 实时计算 Flink版集成实践
- 实时计算 Flink版数据集成实践
实时计算 Flink版更多实践相关
- 实时计算 Flink版自定义实践
- 实时计算 Flink版环境实践
- 实时计算 Flink版产品实践
- 阿里云实时计算 Flink版hudi实践
- 实时计算 Flink版hudi实践
- 实时计算 Flink版hologres实践
- 实时计算 Flink版实时数据湖实践
- 实时计算 Flink版数据湖实践
- 生产实践实时计算 Flink版
- 小米实时计算 Flink版实践
- 实时计算 Flink版数据分析实践
- 实时计算 Flink版k8s实践
- 云原生实时计算 Flink版实践
- 实时计算 Flink版机器学习实践
- 实时计算 Flink版iceberg实践
- 实时计算 Flink版mongodb实践
- apacheflink案例集(2022版)数据集成实时计算 Flink版实践
- 实时计算 Flink版原理实践
- apacheflink案例集(2022版)实时计算 Flink版实践
- apacheflink案例集(2022版)机器学习实时计算 Flink版实践
- 实时计算 Flink版native实践
- 实时计算 Flink版快手扩展实践
- 实时计算 Flink版实时风控实践
- apacheflink案例集(2022版)实时计算 Flink版平台实践
- 阿里云实时计算 Flink版风控实践
- 实时计算 Flink版大规模实践
- 实时计算 Flink版实践案例
- 实时计算flink版流批一体实践
- 引擎实时计算 Flink版实践
- 实时计算 Flink版移动云实践
实时计算 Flink版您可能感兴趣
- 实时计算 Flink版数据
- 实时计算 Flink版CDC
- 实时计算 Flink版报错
- 实时计算 Flink版oss-hdfs
- 实时计算 Flink版oss
- 实时计算 Flink版HDFS
- 实时计算 Flink版镜像
- 实时计算 Flink版clickhouse
- 实时计算 Flink版etl
- 实时计算 Flink版构建
- 实时计算 Flink版SQL
- 实时计算 Flink版mysql
- 实时计算 Flink版同步
- 实时计算 Flink版任务
- 实时计算 Flink版实时计算
- 实时计算 Flink版flink
- 实时计算 Flink版版本
- 实时计算 Flink版oracle
- 实时计算 Flink版kafka
- 实时计算 Flink版表
- 实时计算 Flink版配置
- 实时计算 Flink版产品
- 实时计算 Flink版Apache
- 实时计算 Flink版设置
- 实时计算 Flink版作业
- 实时计算 Flink版模式
- 实时计算 Flink版数据库
- 实时计算 Flink版运行
- 实时计算 Flink版连接
- 实时计算 Flink版checkpoint
实时计算 Flink
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
+关注