
用户画像分析案例加工数据-基于新版数据开发和StarRocks计算资源
本文为您介绍如何将同步至StarRocks的用户信息表ods_user_info_d_starrocks及访问日志数据ods_raw_log_d_starrocks,通过DataWorks的StarRocks节点加工得到目标用户画像数据,阅读本文后,您可以了解如何通过DataWorks+StarRocks产品组合来计算和分析已同步的数据,完成数仓简单数据加工场景。
用户画像分析案例加工数据-基于新版数据开发和Spark计算资源
本文为您介绍如何用Spark SQL创建外部用户信息表ods_user_info_d_spark以及日志信息表ods_raw_log_d_spark访问存储在私有OSS中的用户与日志数据,通过DataWorks的EMR Spark SQL节点进行加工得到目标用户画像数据,阅读本文后,您可以了解如何通过Spark SQL来计算和分析已同步的数据,完成数仓简单数据加工场景。
用户画像分析案例同步数据-基于新版数据开发和StarRocks计算资源
本教程以MySQL中的用户基本信息ods_user_info_d表和OSS中的网站访问日志数据user_log.txt文件为例,通过数据集成离线同步任务分别同步至StarRocks的ods_user_info_d_starrocks、ods_raw_log_d_starrocks表。旨在介绍如何通过DataWorks数据集成实现异构数据源间的数据同步,完成数仓数据同步操作。
用户画像分析案例同步数据-基于新版数据开发和Spark计算资源
本文将介绍如何创建HttpFile和MySQL数据源以访问用户信息和网站日志数据,配置数据同步链路将这些数据同步到在环境准备阶段创建的OSS存储中,并通过创建Spark外表解析OSS中存储的数据。通过查询验证数据同步结果,确认是否完成整个数据同步操作。
用户画像分析案例环境准备-基于新版数据开发和Spark计算资源
本教程以用户画像为例,在华东2(上海)地域演示如何使用DataWorks完成数据同步、数据加工和质量监控的全流程操作。为了确保您能够顺利完成本教程,您需要准备教程所需的EMR Serverless Spark空间、DataWorks工作空间,并进行相关的环境配置。
Hadoop生态系统概述:构建大数据处理与分析的基石
在当今的大数据时代,Hadoop作为开源的大数据处理框架,已经成为众多企业和组织处理大规模数据集的首选工具。Hadoop生态系统是一个由多个组件组成的复杂系统,旨在提供全面的数据存储、处理和分析能力。本文将深入探讨Hadoop生态系统的核心组件、工作原理、应用场景以及其优势和局限性。 Hadoop生态系统的核心组件 Hadoop Distributed ...
使用Hadoop构建Java大数据分析平台
使用Hadoop构建Java大数据分析平台 1. Hadoop简介 Apache Hadoop是一个开源的分布式存储和计算系统,主要用于存储和处理大规模数据集。它提供了一个分布式文件系统(HDFS)和一个并行计算框架(MapReduce),能够有效地处理海量数据。 2. 构建Hadoop环境 在搭建Java大数据...
探索在云原生环境中构建的大数据驱动的智能应用程序的成功案例,并分析它们的关键要素。
在云原生环境中构建大数据驱动的智能应用程序已经成为许多企业的关键目标。以下是一些成功案例,并分析它们的关键要素:1. Netflix - 个性化推荐引擎关键要素:大数据分析: Netflix收集了大量用户观看历史和行为数据,并使用大数据分析来理解用户兴趣和行为模式。云原生基础设施: Netflix构建了云原生基础设施,使用云计算资源弹性伸缩来满足不断增长的需求。智能算法: Netflix使用机器....
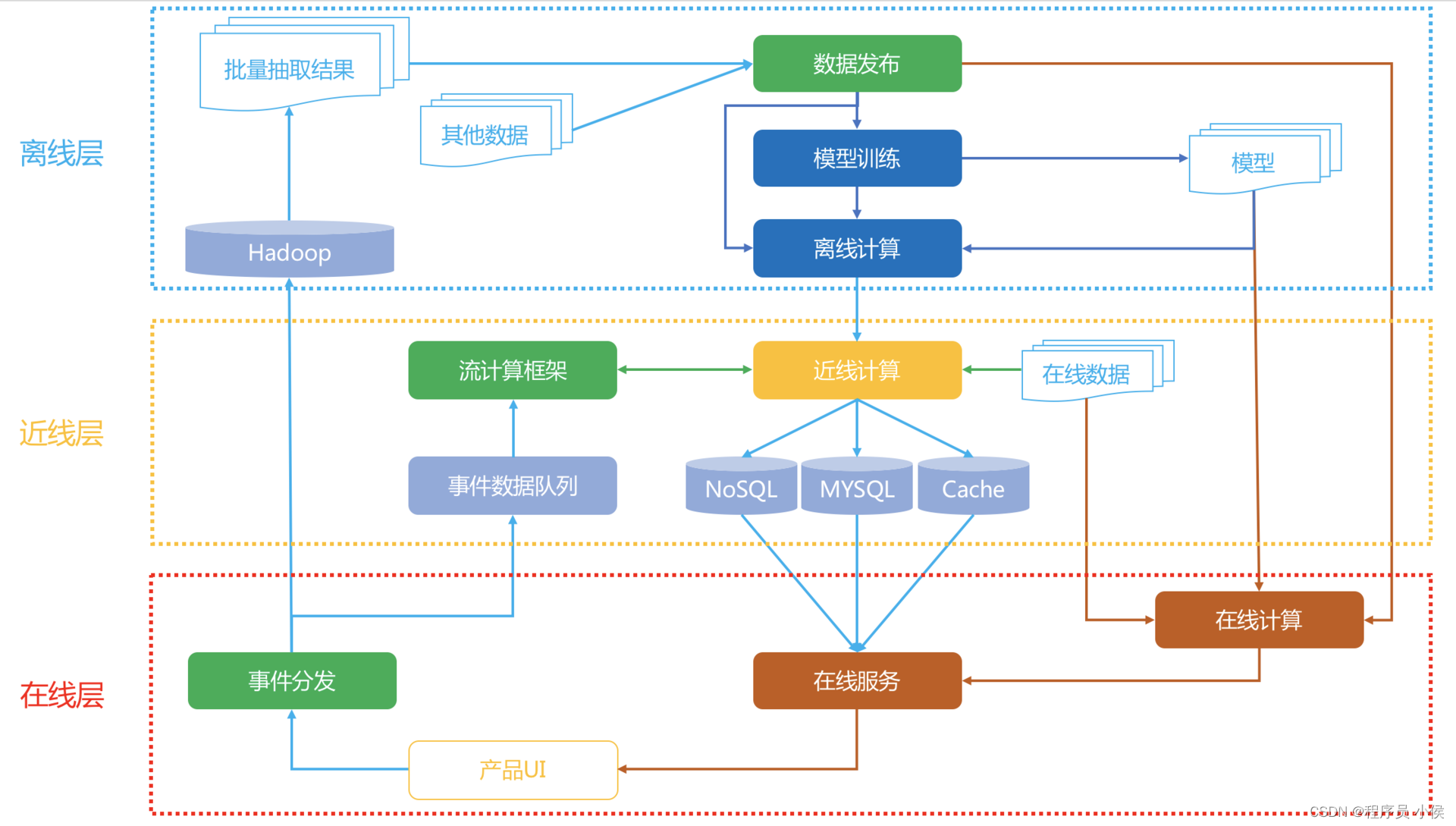
在云原生时代,构建高效的大数据存储与分析平台
在云原生时代,构建高效的大数据存储与分析平台需要综合考虑架构、技术选择和最佳实践。以下是一些方法和策略,可以帮助您构建一个高效的大数据存储与分析平台:1. 选择适当的数据存储技术:根据数据的特性和需求,选择适合的数据存储技术。常见的大数据存储技术包括分布式文件系统(如HDFS)、列式数据库(如Apache HBase)、对象存储(如Amazon S3)、关系数据库等。根据数据访问模式和查询需求,....
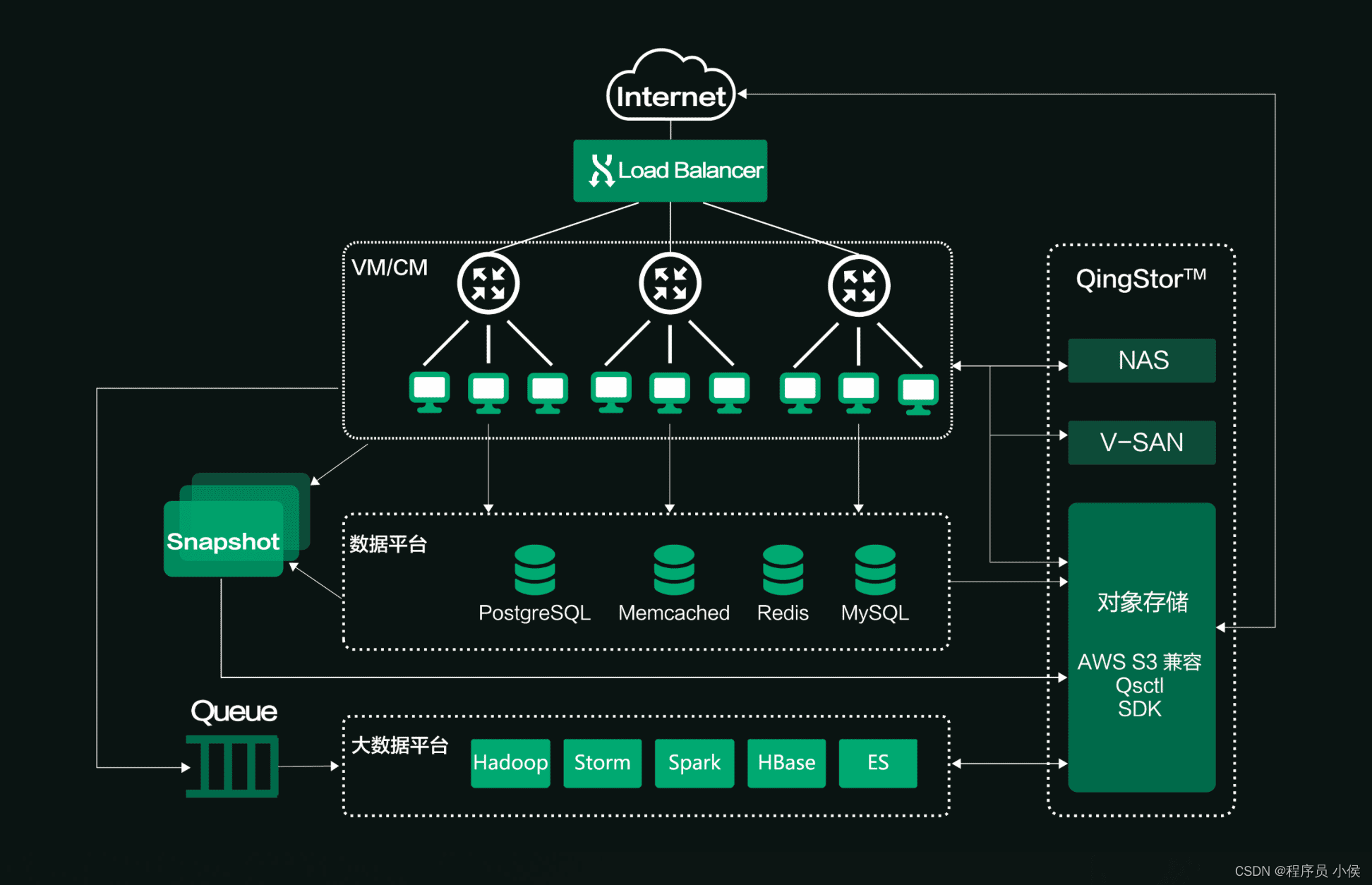
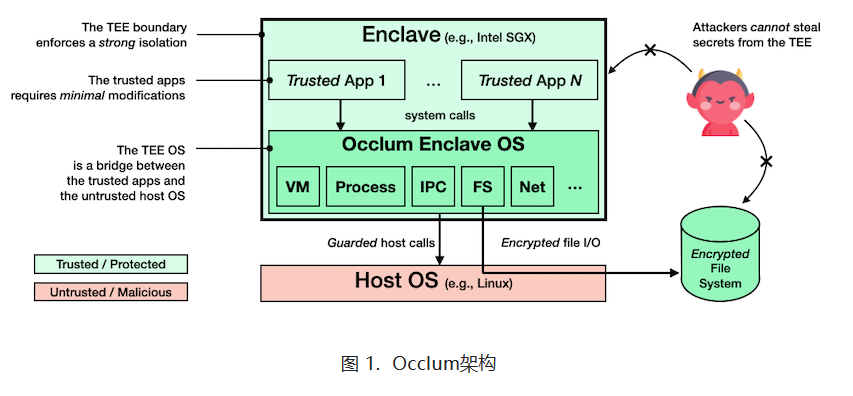
重磅解读:基于Occlum和BigDL构建端到端的安全分布式Spark大数据分析方案
如何在AI和大数据应用中保护数据的安全和隐私是一个现实挑战。本文介绍了基于英特尔SGX的隐私保护机器学习方案。方案应用了蚂蚁集团发起的开源TEE操作系统Occlum,英特尔开源的BigDL PPML,支持端到端的安全分布式大数据分析(例如Spark)和AI应用。该方案已上线到Occlum 1.0 版本中(历时四年打磨,可信执行环境开源操作系统Occlum v1.0正式发布!)作为示例,文章展示了....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute分析相关内容
- 云原生大数据计算服务 MaxCompute分析数据
- 云原生大数据计算服务 MaxCompute分析实践
- 云原生大数据计算服务 MaxCompute分析应用
- 云原生大数据计算服务 MaxCompute分析原理
- 云原生大数据计算服务 MaxCompute分析机器学习
- 云原生大数据计算服务 MaxCompute分析挖掘
- 云原生大数据计算服务 MaxCompute分析商业价值
- 机器学习云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute分析智能决策
- 云原生大数据计算服务 MaxCompute分析智能
- 云原生大数据计算服务 MaxCompute分析引擎
- 云原生大数据计算服务 MaxCompute分析决策
- 用户画像分析云原生大数据计算服务 MaxCompute
- 分析云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute分析解决方案
- 云原生大数据计算服务 MaxCompute分析平台
- spark云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute分析技术
- 云原生大数据计算服务 MaxCompute可视化分析
- 云原生大数据计算服务 MaxCompute数据处理分析
- 云原生大数据计算服务 MaxCompute分析企业决策
- 云原生大数据计算服务 MaxCompute分析技术决策
- 云原生大数据计算服务 MaxCompute分析企业
- 云原生大数据计算服务 MaxCompute教育分析
- 企业级云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute kafka分析
- 云原生大数据计算服务 MaxCompute案例分析
- 云原生大数据计算服务 MaxCompute分析存储
- 云原生大数据计算服务 MaxCompute分析性能
- 分析云原生大数据计算服务 MaxCompute价值
云原生大数据计算服务 MaxCompute更多分析相关
- 云原生大数据计算服务 MaxCompute分析优化
- 云原生大数据计算服务 MaxCompute分析案例
- 云原生大数据计算服务 MaxCompute分析角色
- 云原生大数据计算服务 MaxCompute分析实战
- 云原生大数据计算服务 MaxCompute分析查询
- 云原生大数据计算服务 MaxCompute分析扩展
- 云原生大数据计算服务 MaxCompute分析基石
- 系统云原生大数据计算服务 MaxCompute分析
- hadoop云原生大数据计算服务 MaxCompute分析
- flume云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute分析架构
- 云原生大数据计算服务 MaxCompute技术分析
- 云原生大数据计算服务 MaxCompute原理信息分析
- 云原生大数据计算服务 MaxCompute分析spark
- 云原生大数据计算服务 MaxCompute分析最佳实践
- 云原生大数据计算服务 MaxCompute分析方法
- 云原生大数据计算服务 MaxCompute分析模型
- 云原生大数据计算服务 MaxCompute交互式分析
- 云原生大数据计算服务 MaxCompute存储分析
- 实战云原生大数据计算服务 MaxCompute分析
- 阿里分析云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute分析服务
- 数据可视化云原生大数据计算服务 MaxCompute分析
- 技术云原生大数据计算服务 MaxCompute分析
- 产品云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute分析研究
- 云原生大数据计算服务 MaxCompute分析挖掘技术
- 开源云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute分析方案
- 云原生大数据计算服务 MaxCompute分析驱动
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute电子
- 云原生大数据计算服务 MaxCompute伦理
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute决策
- 云原生大数据计算服务 MaxCompute契机
- 云原生大数据计算服务 MaxCompute企业
- 云原生大数据计算服务 MaxCompute版本
- 云原生大数据计算服务 MaxCompute挖掘
- 云原生大数据计算服务 MaxCompute机器学习
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目
