
使用Hadoop命令操作OSS/OSS-HDFS
在使用阿里云EMR Serverless Spark的Notebook时,您可以通过Hadoop命令直接访问OSS或OSS-HDFS数据源。本文将详细介绍如何通过Hadoop命令操作OSS/OSS-HDFS。
如何通过ES-Hadoop实现Spark读写阿里云Elasticsearch数据
Spark是一种通用的大数据计算框架,拥有Hadoop MapReduce所具有的计算优点,能够通过内存缓存数据为大型数据集提供快速的迭代功能。与MapReduce相比,减少了中间数据读取磁盘的过程,进而提高了处理能力。本文介绍如何通过ES-Hadoop实现Hadoop的Spark服务读写阿里云Elasticsearch数据。
【大数据技术Hadoop+Spark】Hive基础SQL语法DDL、DML、DQL讲解及演示(附SQL语句)
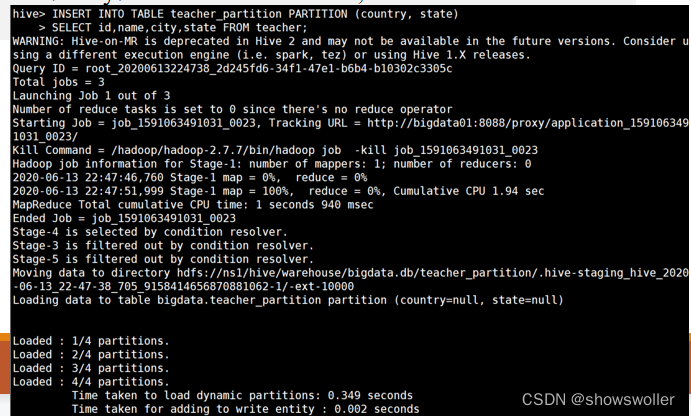
Hive基础SQL语法1:DDL操作DDL是数据定义语言,与关系数据库操作相似,创建数据库CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name显示数据库SHOW databases;查看数据库详情DESC DATABASE|SCHEMA database_name切换数据库USE database_name修改数据库ALTER (DATABAS....
【大数据技术Hadoop+Spark】Hive数据仓库架构、优缺点、数据模型介绍(图文解释 超详细)
一、Hive简介Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook开发团队想设计一种使用SQL语言对日志数据查询分析的工具,而Hive就诞生于此,只要懂SQL语言,....
如何在EMR的Hadoop集群中运行Spark作业对接DataHub数据_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文介绍如何在E-MapReduce的Hadoop集群,运行Spark作业消费DataHub数据、统计数据个数并打印出来。
HADOOP MapReduce 处理 Spark 抽取的 Hive 数据【解决方案一】
开端:今天咱先说问题,经过几天测试题的练习,我们有从某题库中找到了新题型,并且成功把我们干趴下,昨天今天就干了一件事,站起来。沙问题?java mapeduce 清洗 hive 中的数据 ,清晰之后将driver代码 进行截图提交。坑号1: spark之前抽取的数据是.parquet格式的, 对 mapreduce 不太友好,我决定从新抽取, 还是用spark技术,换一种文件格式坑号2....
【Hadoop Summit Tokyo 2016】利用电力公司智能电表数据比较Spark SQL与Hive
本讲义出自Yusuke Furuyama与Yang Xie在Hadoop Summit Tokyo 2016上的演讲,主要分享了对于电力公司智能电表数据的数据分析案例,并分享了利用MapReduce与Spark 1.6进行计算的性能比较情况,并对于Spark 2.0的进化情况进行了分享。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop spark相关内容
- hadoop spark大数据处理
- 数据湖hadoop spark
- 技术hadoop spark
- spark模式hadoop
- 大数据spark hadoop
- spark部署hadoop
- spark hadoop mapreduce
- spark hadoop wordcount单词计数实例
- 大数据技术hadoop spark
- maxcompute spark hadoop
- hadoop spark flink
- 分布式hadoop spark
- hadoop spark数据处理
- spark hadoop分布式
- hadoop hive spark
- hadoop spark数据
- hadoop spark组件
- hadoop spark概念
- hadoop spark安装
- hadoop spark实战源码
- hadoop spark原理
- hadoop spark hbase
- 云计算hadoop spark
- spark hadoop pdf
- hadoop spark异同
- spark编译hadoop
- spark hadoop scala
- hadoop spark hive数据
- storm spark hadoop
- spark hadoop框架
hadoop更多spark相关
- hadoop zookeeper spark
- hadoop spark步骤
- hadoop spark分布式
- hadoop spark standalone
- hadoop实战spark
- hadoop spark案例
- hadoop概念学习spark
- hadoop summit tokyo apache spark
- spark summit hadoop
- spark hadoop参数
- spark与hadoop大数据分析hadoop spark
- hadoop学习spark
- hadoop storm spark
- hadoop ha spark
- hadoop spark mesos
- hadoop大数据平台spark
- hadoop summit tokyo spark扩展
- hadoop yarn spark
- spark学习hadoop
- spark hadoop解决方案
hadoop您可能感兴趣
- hadoop开发环境
- hadoop hbase
- hadoop集群
- hadoop数据处理
- hadoop数据分析
- hadoop入门
- hadoop系统
- hadoop技术
- hadoop大数据
- hadoop集群管理
- hadoop hdfs
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop分布式
- hadoop数据
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作